11/9 – Arbedo-Castione (Svizzera) – ore 18 – Arbed Smart Center, via San Gottardo 24. Evento sulla cyber sicurezza per le piccole/medie imprese, promosso dalla Zurigo Assicurazioni. Segue aperitivo e networking.
20/9 – Lugano Besso (Svizzera) – partecipazione alle Porte aperte alla RSI dalle ore 16. Via Canevascini, studio 2.
27/9 – Ascona (Svizzera) – ore 11 – Aula Magna del Collegio Papio, via delle Cappelle 1. Evento sull’IA per Amici del Collegio Papio.
Se non ci si addestra molto attentamente a essere vigili contro gli errori delle attuali intelligenze artificiali, quegli errori passeranno inosservati e finiranno per contaminare tutto, con conseguenze potenzialmente disastrose.
Leggo su The Verge che l’IA di Google dedicata alla medicina, Med-Gemini (non una IA generica, ma un prodotto destinato specificamente all’uso medico), ha “inventato” una parte anatomica che non esiste, i “gangli basilari”. Secondo Google si è trattato semplicemente di un refuso al posto di “gangli basali”, ma il problema è che il refuso non è stato notato dai revisori e quindi rischia di propagarsi inosservato, alterando la terminologia medica. E qui sta il problema di fondo di questi software: spesso generano risultati che a prima vista possono suonare giusti ma sono in realtà sottilmente sbagliati, e noi non siamo mentalmente predisposti per notare errori così sottili, nascosti in una sequenza di parole plausibili. Ci adagiamo facilmente, abbassiamo la guardia.
Me ne sono accorto personalmente stamattina. Sono alle prese con una traduzione medica dall’italiano all’inglese che a un certo punto parla di estrogeni, al plurale. DeepL, che ho usato nella sua versione professionale per la pre-traduzione di bozza (perché è abbastanza efficace come assistente ma ogni tanto prende granchi clamorosi), mi ha tradotto quel plurale volgendolo al singolare: estrogen.
La cosa mi ha insospettito. Nel rivedere attentamente a mano il testo, ritraducendo mentalmente per poi vedere come se l’è cavata DeepL, come faccio sempre, ho verificato che in inglese estrogen viene usato sia come countable, ossia sostantivo che ha un plurale (estrogens), sia come uncountable, ossia che rimane invariato al plurale (come furniture o information). E solitamente si usa come uncountable, quindi al singolare. DeepL ha lavorato bene.
Ma quando ho immesso in Google “estrogen plural”, come faccio sempre quando voglio verificare il plurale dei termini (soprattutto medici, visto che molti in inglese hanno plurali alla latina o alla greca), l’IA di Google mi ha risposto con perentoria certezza in modo molto differente.
The plural of estrogen is estrogens. This is because “estrogen” refers to a group of related hormones, not a single substance. The term “estrogens” is more accurate when referring to these multiple hormones.
In altre parole, l’IA di Google mi ha dato una risposta che è in sé corretta ma omette una parte importantissima, ossia il fatto che anche la forma estrogen per il plurale è valida. Questi errori di omissione sono i più subdoli in assoluto.
Faccio ancora un esempio, in cui stavolta è stato DeepL a sbagliare in maniera sottilmente ingannevole. Lo stesso testo parla, nell’originale, di DNA che viene tagmentato. Nella sua pre-traduzione, DeepL ha tradotto fragmented, ossia “frammentato”, come se avesse interpretato tagmentato come un errore di battitura al posto appunto di frammentato. Ma in realtà il testo originale è corretto, perché la tagmentazione è un procedimento che esiste e ha un significato tecnico molto preciso.
Quanti traduttori avrebbero pensato a un semplice refuso e avrebbero detto “ecco guarda quanto è bravo DeepL, corregge persino gli errori di battitura”, commettendo invece un errore importante di traduzione?
Per usare efficacemente questi software di traduzione assistita, e più in generale per usare efficacemente le intelligenze artificiali, bisogna insomma riaddestrarsi, cambiare metodo di lavoro, cercare di anticipare gli errori tipici di questi prodotti e diventare loro supervisori inflessibili e perennemente sul chi vive. Pensare che possano sostituire gli esseri umani è pura incoscienza.
Questo è il testo della puntata dell’11 agosto 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: audio da “Death Stranding”, tratto da questo video]
Ogni tanto, nella storia di Internet, arriva qualcuno che reclama che si deve fare qualcosa per impedire ai minori di vedere i contenuti non adatti alla loro età che si possono trovare facilmente online. Raccoglie firme, promuove petizioni, trova agevolmente qualche politico che sposa la sua causa perché proteggere i bambini piace molto a qualunque elettore ed elettrice, e la richiesta finisce per diventare una proposta di legge.
A questo punto, di solito, vengono convocati i tecnici, quelli che sanno come funziona realmente Internet, scuotono la testa come hanno già fatto altre volte in passato e avvisano che la proposta è nobile ma non è tecnicamente fattibile e provarci avrebbe delle conseguenze catastrofiche sulla sicurezza, sulla privacy di tutti i cittadini, sui minori stessi e sui servizi di sostegno a quei minori, diventerebbe una censura di massa di qualunque idea politicamente sgradita e comunque soprattutto non funzionerebbe, perché qualunque misura tecnica per identificare e distinguere fra minori e adulti quando accedono a un sito sarebbe facilmente aggirabile.
Il politico di solito rimane perplesso ma accetta il parere esperto dei tecnici e lascia perdere. Il 25 luglio scorso, invece, un intero paese europeo ha deciso di ignorare fieramente gli esperti e di provare lo stesso a proteggere i bambini approvando una legge che è l’equivalente informatico di vietare al vento di soffiare. Quel paese è il Regno Unito, e questa è la storia di un disastro annunciato, da ricordare la prossima volta che qualche altro politico, in qualche altro paese, si farà venire la stessa idea.*
* Tipo la Francia, ma in modi meno draconiani di quello britannico [Twobirds; Techinformed]; Danimarca, Grecia, Italia e Spagna stanno testando un’app di verifica dell’età [Lepoint; Liberation].
Perché tutto il costoso sistema di controllo online dell’età tramite riconoscimento facciale messo in piedi nel Regno Unito, usando le più sofisticate tecnologie, è crollato (come ampiamente previsto) nel giro di pochi giorni grazie a un videogioco, Death Stranding, di cui avete sentito uno spezzone in apertura. I suoi giocatori, infatti, hanno scoperto che per farsi identificare come adulti bastava mostrare alla telecamera uno dei personaggi del gioco, Sam Bridges, che può essere comandato per fargli fare tutti i movimenti e le espressioni richieste dai controlli. E ovviamente le vendite di VPN sono schizzate alle stelle. Ma soprattutto ci si è resi conto che questo sistema strangola le piccole comunità online e lascia invece il campo libero ai soliti grandi nomi stramiliardari dei social network.
Benvenuti alla puntata dell’11 agosto 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica; questa è l’unica puntata di questo mese. La prossima verrà pubblicata il primo settembre. Io sono Paolo Attivissimo.
[SIGLA di apertura]
L’Online Safety Act è una legge del Regno Unito concepita nel 2023 per impedire alle persone che hanno meno di diciotto anni di accedere alla pornografia e ai contenuti legati all’autolesionismo, ai disturbi dell’alimentazione e al suicidio. I suoi controlli online sono entrati in vigore il 25 luglio scorso. In pratica, i gestori dei siti che possono trovarsi a ospitare contenuti di questo tipo* sono obbligati ad attivare delle verifiche dell’età dei loro visitatori, gestite da aziende specializzate.
* Notare il “possono”. Questa legge non riguarda solo i siti pornografici. Ci torno dopo, ma è importante chiarirlo subito.
Queste verifiche possono richiedere per esempio di dare le coordinate di una carta di credito, perché si presume che chi ha accesso a una carta di credito sia maggiorenne. In alternativa, l’utente può dare le coordinate di un proprio documento d’identità insieme a una propria foto scattata sul momento e il software controllerà se corrispondono e se si riferiscono a un maggiorenne oppure no.
Uno dei metodi di controllo alternativi più originali proposti da questa nuova legge britannica è la verifica tramite email. L’utente fornisce il proprio indirizzo di mail a un servizio apposito, che interroga i fornitori di servizi bancari o di utenze domestiche del paese, come luce, telefono, gas o Internet, per sapere se quell’indirizzo è stato usato per fare transazioni o gestire utenze, nel qual caso si presume che l’utente sia maggiorenne. Ovviamente questo significa che i gestori di questi controlli devono ficcare il naso nelle attività personali di questi utenti.
Poi c’è il riconoscimento facciale, o meglio, la stima dell’età tramite analisi del volto. L’utente si fa un selfie o mostra il viso in diretta alla telecamera del computer o del telefonino e un’azienda specializzata usa l’intelligenza artificiale per decidere se ha una faccia da maggiorenne o da minorenne.
L’utente può anche dare il permesso a una società specializzata di verificare se il suo numero di telefonino è intestato a un minorenne o un adulto, oppure può affidarle le sue coordinate bancarie e la società di verifica interrogherà la banca per sapere se l’utente ha più o meno di 18 anni.
Sono tutte misure piuttosto invasive, che hanno tre punti deboli molto importanti.
Il primo è che raccolgono i dati personali di milioni di persone e li mettono in mano ad aziende private, creando quindi potenzialmente un archivio centrale che farà gola ai criminali informatici, come è già successo per esempio con AU10TIX, la società israeliana usata da TikTok, Uber, LinkedIn, PayPal e altri grandi nomi [404 Media].
Il secondo punto debole è che l’utente britannico può eludere tutte queste complicazioni semplicemente installando un’app VPN, in modo da simulare di trovarsi al di fuori del Regno Unito e quindi non essere soggetto a tutti questi controlli. E infatti tre giorni dopo l’entrata in vigore di questa legge le app VPN sono diventate le più scaricate in assoluto nell’App Store di Apple nel paese. L’app svizzera Proton VPN, per esempio, ha avuto un picco del 1800% nelle attivazioni provenienti dal Regno Unito.
Il colmo dell’ironia involontaria in questa situazione arriva dalla BBC, che in un articolo sul proprio sito riferisce che le autorità vietano alle piattaforme online di ospitare contenuti che incoraggino l’uso delle VPN per eludere i controlli sull’età e subito dopo, sulla propria piattaforma, offre una pratica infografica che spiega esattamente come usare una VPN per eludere i controlli sull’età.
L’infografica della BBC.
Come nota il sito Techdirt.com, “quando la tua legge ‘salvabambini’ ha come risultato principale insegnare ai bambini come usare le VPN per aggirarla, forse hai sbagliato leggermente il tuo obiettivo”.
Il terzo punto debole è che la stima dell’età tramite riconoscimento facciale può essere beffata appunto usando il volto di Sam Porter Bridges, il protagonista del popolare videogioco Death Stranding. Questo controllo infatti chiede all’utente di mostrare alcune espressioni facciali, tipo aprire o chiudere la bocca, e in questo gioco è possibile comandare questo personaggio in modo che faccia proprio queste espressioni.
Screenshot
La notizia di questo trucco si è diffusa immediatamente nei social network, nei siti di gaming e in quelli dedicati alle notizie informatiche, spesso accompagnato da un coro di “ve l’avevamo detto”. È una falla imbarazzantissima, che solleva una domanda importante: se le aziende che realizzano questi controlli sono talmente inette che basta un videogioco per beffarle, perché mai dovremmo credere che siano capaci invece di custodire perfettamente i nostri dati sensibili?
Anche se molti utenti eluderanno questi controlli, anche se sarà necessario rinunciare a un po’ di anonimato online, almeno qualche bambino verrà protetto dalle grinfie dei pornografi, giusto? No, perché la strada dell’inferno, come si suol dire, è lastricata di buone intenzioni, anche in informatica.
Infatti una delle conseguenze di questa nuova legge britannica è che le comunità online e le associazioni per la tutela dei minori adesso non sono più facilmente accessibili ai minori che vorrebbero proteggere. Per esempio, una vittima minorenne di abusi sessuali deve ora presentare un documento di un adulto per poter interagire con i servizi che la possono aiutare.
E non è tutto: molti siti e forum gestiti da privati si trovano costretti a chiudere, perché non hanno i fondi necessari per pagare le aziende private deputate a questi controlli obbligatori, che possono costare circa 2700 euro l’anno, e non hanno le risorse umane per mettersi in regola con le nuove disposizioni. Non si tratta solo di siti che parlano di tematiche sensibili riguardanti i minori: queste regole toccano tutti i siti britannici, su qualunque tema.* Persino un’associazione di ciclisti o un forum dedicato al golf o alle birre artigianali o ai criceti.
* Questa legge è stata presentata come “anti-porno”, ma non è affatto così. L’OSA non riguarda solo i siti pornografici. Tocca qualunque sito nel quale gli utenti possano pubblicare contenuti o interagire tra loro. In pratica, qualunque forum e qualunque sito di associazione.
“The Act’s duties apply to search services and services that allow users to post content online or to interact with each other. This includes a range of websites, apps and other services, including social media services, consumer file cloud storage and sharing sites, video-sharing platforms, online forums, dating services, and online instant messaging services.” [Gov.uk]
Inoltre questa legge tocca principalmente i siti britannici, ma si estende anche ai siti esteri in alcuni casi: “The Act applies to services even if the companies providing them are outside the UK should they have links to the UK. This includes if the service has a significant number of UK users, if the UK is a target market, or it is capable of being accessed by UK users and there is a material risk of significant harm to such users. [...] The Act gives Ofcom the powers they need to take appropriate action against all companies in scope, no matter where they are based, where services have relevant links with the UK. This means services with a significant number of UK users or where UK users are a target market, as well as other services which have in-scope content that presents a risk of significant harm to people in the UK.” [Gov.uk]
Persino Wikipedia. L’enciclopedia online, infatti, rischia di essere equiparata ai social network come Facebook o TikTok e ai grandi siti di pornografia che erano nella mente del legislatore quando ha concepito l’Online Safety Act. Gli avvocati della Wikimedia Foundation sono andati in tribunale per contestare la nuova legge, che obbligherebbe Wikipedia a mettere un tetto al numero di britannici che la consultano, perché se dovessero superare i sette milioni l’enciclopedia verrebbe classificata come un cosiddetto “servizio di categoria 1” e sarebbe soggetta quindi alle restrizioni massime previste da questa legge [Wikimedia Foundation]. Dovrebbe per esempio verificare le identità dei circa 260.000 utenti che contribuiscono volontariamente alla sua manutenzione e sottostare a mille altri obblighi che la renderebbero in sostanza ingestibile [The Telegraph; copia su Archive.is].
Insomma, quella che è stata presentata come una legge contro la pornografia sta diventando un bavaglio che tocca moltissimi settori.* Persino Spotify adesso deve chiedere agli utenti di farsi controllare l’età per poter accedere a certi suoi video musicali nel Regno Unito. Numerosi utenti segnalano che le notizie di guerra, soprattutto quelle riguardanti la Palestina, sono bloccate sui social network e per leggerle bisogna presentare un documento d’identità o farsi verificare l’età. Sono soggetti a controlli persino i forum di Reddit dedicati al cinema o ai labubu [Dazed].
* L’ambito intenzionale di questa legge è vastissimo: altro che “anti-porno”. I temi specificamente protetti non sono solo gli abusi sessuali su minori, la violenza sessuale estrema, gli abusi tramite immagini intime, lo sfruttamente sessuale e la pornografia estrema, ma le frodi, i reati contro l’ordine pubblico con aggravanti razziali o religiose, l’istigazione alla violenza, l’immigrazione illegale e il traffico di esseri umani, la promozione o la facilitazione del suicidio, la vendita di sostanze o armi illegali e il terrorismo. [Gov.uk]
I social network e i grandi siti per adulti, invece, prosperano indisturbati. A differenza delle piccole comunità online di volontari, hanno le risorse economiche e tecniche necessarie per implementare questi controlli di fatto inutili. Se si cerca di regolamentare Internet pensando che Internet sia solo Facebook e Google e poco altro, alla fine sopravvivono solo questi colossi, che sono gli unici che ricevono benefici da una legge come questa.
Chi prima gestiva un forum amatoriale indipendente, infatti, si troverà costretto a trasferire la propria comunità di utenti su un social network come Instagram o Discord o Facebook, dove i post dei membri saranno inframmezzati da inserzioni pubblicitarie che faranno diventare ancora più ricchi e potenti questi social e i loro proprietari, e dove quello che scrivono sarà soggetto agli umori e alle censure del momento [The New Statesman], come sa bene chiunque abbia perso di colpo il proprio profilo Instagram perché a quanto pare avrebbe violato qualche “standard della comunità” e non ha modo di reclamare e nemmeno di sapere quale di questi standard non avrebbe rispettato.
I cittadini britannici hanno criticato gli effetti di questa legge, depositando centinaia di migliaia di firme in pochi giorni presso il sito governativo apposito per le petizioni. Peter Kyle, segretario di stato per le tecnologie del governo del paese, ha risposto scrivendo su X/Twitter che chi vuole sopprimere questa legge sta dalla parte dei predatori di minori [X], equiparando insomma i critici ai criminali.
Visto che la tentazione di adottare leggi come quella britannica farà inevitabilmente capolino ancora, riassumo per chiarezza quali sono i veri effetti di qualunque legge che imponga la verifica delle identità o dell’età per accedere a contenuti online:
Per gli adulti diventa più difficile accedere alle informazioni e ai servizi perfettamente legali e utili.
I cittadini vengono obbligati a creare un tracciamento dettagliato delle loro attività online legato alle proprie identità e vengono spinti verso piattaforme meno sicure.
Le piccole comunità online che non possono permettersi gli oneri di conformità alla legge vengono distrutte.
E a un’intera generazione viene insegnato che eludere la sorveglianza governativa è una competenza di base della vita [TechDirt].
I danni che queste leggi affermano di voler eliminare, invece, proseguono indisturbati. I predatori non fanno altro che trasferirsi su altre piattaforme, usano la messaggistica con crittografia oppure ricorrono alle VPN. Si crea, insomma, l’illusione della sicurezza, ma in realtà si aumenta l’insicurezza di tutti. E i social network, i cui algoritmi creano spirali cognitive tossiche e causano tutti questi danni, vengono premiati invece di essere puniti.
Quello che è successo nel Regno Unito dovrebbe essere un monito per qualunque democrazia alle prese con la regolamentazione di Internet. Se i politici preferiscono atteggiarsi a uomini forti e decisionisti, se privilegiano l’apparenza di aver fatto qualcosa, qualunque cosa, alla sostanza di aver capito il problema e di aver agito ascoltando gli esperti, adottando soluzioni sociali a lungo termine e varando norme come l’interoperabilità che tolgano ai social network il loro strapotere di ghetti inghirlandati, il risultato è che nessun bambino viene salvato.
E l’unica cosa buona che viene fuori da questa legge britannica è che adesso quei pericoli per la democrazia che venivano ipotizzati dagli esperti non sono più teoria, ma sono pratica concreta, tangibile e reale, da studiare per capire che cosa non fare.
Jim Lovell davanti al razzo Saturn V che lo stava per portare sulla Luna – o quasi – nel 1970. Foto NASA S70-34268.
James Arthur Lovell, protagonista di quattro voli spaziali, due dei quali sono entrati nella storia per la loro straordinarietà di viaggi verso la Luna, è morto a 97 anni. La notizia è stata diffusa oggi.
Jim Lovell insieme a David Bowie sul set del film L’uomo che cadde sulla Terra.
Fece parte dell’equipaggio della missione più rischiosa della NASA negli anni della corsa alla Luna, Apollo 8, la prima circumnavigazione umana della Luna, nel 1968: insieme ai suoi compagni di viaggio Frank Borman e Bill Anders, fu il primo essere umano nella storia a superare l’abisso di quattrocentomila chilometri che ci separa dal nostro satellite naturale e a vedere la faccia nascosta del nostro satellite, sorvolandola su un veicolo il cui unico motore doveva funzionare perfettamente per permettere ai tre di tornare a casa. Non c’erano motori di riserva o scialuppe o soccorsi possibili. Mentre sorvolavano quella faccia nascosta erano completamente isolati dal resto dell’umanità, perché la Luna bloccava i segnali radio. Andò tutto bene e la missione fu un trionfo. La famosa foto della Terra che si staglia sull’orizzonte della Luna fu scattata durante questo volo.
Lovell tornò a volare verso la Luna nel 1970 per un’altra missione storica: Apollo 13. Quella che, come molti ricorderanno, ebbe “un problema” diventato proverbiale. Durante l’andata verso la Luna, uno scoppio di un serbatoio vitale trasformò un volo che prevedeva che Lovell camminasse sul suolo lunare insieme a Fred Haise in una vera e propria Odissea nello spazio: tre giorni al freddo e al buio su un veicolo che non sapevano quanto fosse stato danneggiato e a corto di ossigeno, di cibo e di acqua.
Quel veicolo spaziale ferito e menomato li riportò a casa grazie alla sua progettazione robusta e grazie ai nervi saldi e alla competenza tecnica straordinaria degli uomini a bordo (il terzo era Jack Swigert) e dei tecnici sulla Terra. Il film omonimo di Ron Howard, di cui quest’anno ricorre il trentennale, è una ricostruzione piuttosto fedele (con qualche licenza narrativa) di quel “disastro di grande successo”. Grazie a Gianluca Atti potete ripercorrere la cronaca reale di quel dramma sui giornali italiani dell’epoca:
Nel film che celebra la sua missione, Jim Lovell ebbe una piccola parte: lo si vede nelle scene finali, a bordo della portaerei, in divisa, mentre stringe la mano a Tom Hanks, l’attore che lo interpreta. Il regista, Ron Howard, offrì a Lovell una divisa da ammiraglio; l’astronauta rifiutò e tirò fuori la propria vecchia divisa da capitano. Aveva lasciato la Marina degli Stati Uniti con il grado di capitano, disse, e con quel grado voleva essere immortalato. Uno stile d’altri tempi.
Dal film Apollo 13 di Ron Howard (1995).
Gli altri due voli spaziali erano stati forse meno storici ma comunque fondamentali: insieme a Borman, a bordo della Gemini 7 era rimasto in orbita intorno alla Terra per due settimane, in una cabina strettissima, per dimostrare che il corpo umano poteva funzionare nello spazio per il tempo necessario per arrivare fino alla Luna, soggiornarvi e tornare indietro. Poi era tornato a volare nello spazio con la missione Gemini 12, insieme a un certo Buzz Aldrin, al suo primo volo. Aldrin aveva effettuato ben tre “passeggiate spaziali” durante quella missione; insieme a Neil Armstrong, sarebbe stato il primo essere umano a camminare sulla Luna a luglio del 1969, con la missione Apollo 11.
Nel 1952 il giovane Jim Lovell, ventiquattrenne appena uscito dall’Accademia navale, aveva sposato Marilyn Gerlach, la ragazza che aveva conosciuto a scuola. La loro missione congiunta durò ben settant’anni, fino a quando Marilyn morì, nel 2023.
La foto che io e la Dama del Maniero abbiamo scattato con lui nel 2015 è qui accanto a me, sulla scrivania, a ricordo di un incontro indimenticabile con una persona straordinaria, che a ottantasette anni smanettava con il suo smartphone, mi parlava di Viber e sapeva tenere con il fiato sospeso una sala di cinquecento persone mentre raccontava per un’ora intera i suoi quattro voli spaziali, senza aver bisogno di PowerPoint ma usando solo i suoi appunti scritti su cartoncini e una lucidità invidiabile a qualunque età. L’avremmo ascoltato per ore.
Sì, quello che ho in mano è il catalogo fotografico originale NASA della sua missione Apollo 13. Firmato.
Vorrei ricordarlo con queste sue parole, dette al pubblico in quell’occasione, che danno la misura dell’uomo straordinario che era:
“Mi sono chiesto spesso cosa sarebbe successo se Apollo 13 avesse avuto successo; se non ci fosse stata nessuna esplosione, fossimo atterrati sulla Luna, avessimo raccolto delle rocce, pronunciato frasi dimenticabili, e poi fossimo tornati sani e salvi. Sette missioni lunari completate con successo. La storia di Apollo 13 sarebbe stata sepolta nel bidone della spazzatura della storia dello spazio. Probabilmente non sarei qui a parlarne: la stessa cosa, fatta per la terza volta.
Per anni sono rimasto molto deluso di non aver potuto atterrare sulla Luna. Era la fine della mia carriera spaziale attiva e forse di quella navale. Era quello che avevo tanto desiderato fare. Ma poi, con il passare degli anni, abbiamo scritto un libro, intitolato inizialmente “Lost Moon” [Luna perduta] e poi “Apollo 13”, e mi sono detto che se fossimo atterrati sulla Luna e fossimo tornati, la lingua inglese non avrebbe il modo di dire “Houston, abbiamo un problema”. Non avrebbe “Il fallimento non è contemplato”. E mi sono detto che [quell’incidente] aveva tirato fuori quello che la gente sa fare quando c’è una crisi.
E quindi mi sono reso conto che la cosa migliore che poteva succedere nel nostro programma spaziale, in quel momento specifico, era avere un’esplosione come questa, che ha fatto emergere tante cose e ha consentito a gente di talento di trasformare una catastrofe quasi garantita in un atterraggio sicuro.”
Le eredità digitali sono un gran casino. Chiunque si sia trovato a gestire un lutto in famiglia oggi si trova confrontato con una sfida in più: districarsi nei vari account social e di servizi online di chi non c’è più e difficilmente ha lasciato istruzioni dettagliate e aggiornate su cosa sono e cosa farne. Con la spedizione delle bollette via mail e le comunicazioni delle aziende che arrivano sempre più spesso via WhatsApp, c’è il rischio di trovarsi con pagamenti in sospeso, multe e sanzioni di cui non si sa nulla. Viceversa, ci possono essere soldi custoditi online, sotto forma di conti PayPal o in criptovalute, che può essere interessante recuperare.
Tutto questo è ovviamente un territorio di caccia molto fertile per i truffatori, per cui a gennaio scorso, quando ho ricevuto delle mail a prima vista provenienti da Paypal sulla casella di mail di mio padre (morto cinque anni fa), con un invito a leggere e accettare le condizioni di contratto aggiornate, ho pensato subito a un classico phishing e le ho ignorate, sapendo che mio padre non era assolutamente il tipo di persona che avrebbe aperto un conto Paypal. E se anche l’avesse fatto, ne avrebbe preso nota (rigorosamente su carta, insieme a tutte le sue password). Nessuno in famiglia ne sapeva nulla.
Ma le mail hanno continuato ad arrivare, e il mittente sembrava essere realmente Paypal, per cui mi sono incuriosito. Vi racconto questa vicenda perché potrebbe essere utile per altre persone che si trovano nella mia stessa situazione.
Ho cercato in lungo e in largo, anche con strumenti di informatica forense, nei backup e nelle immagini disco che avevo fatto dei dispositivi di mio padre, ma non ho trovato la minima menzione di un account Paypal. Non avendo la password dell’account non potevo entrare nel conto; avendo la mail, potevo farmi mandare un link di reset della password, cosa che ho fatto. Il link mi è arrivato e portava effettivamente al sito di Paypal, che accettava la richiesta di reset di un conto associato alla mail di mio padre, a conferma che l’account era reale e non si trattava di un phishing.
Ma è emerso che l’account era protetto dall’autenticazione a due fattori (2FA), per cui il link di reset richiedeva il codice numerico temporaneo che veniva mandato via SMS. Il mistero si è quindi infittito, per due ragioni: mio padre non usava mai la 2FA, nonostante le mie perenni suppliche di mettersi in sicurezza, e il numero di telefono associato all’account (che potevo vedere in parte durante la procedura di reset) era un numero fisso, quello della sua abitazione, sul quale sarebbe stato impossibile anche per lui ricevere un SMS di autenticazione. La situazione non aveva alcun senso logico.
A questo punto mi trovavo con un account Paypal confermato come reale, in apparenza intestato a mio padre, ma inaccessibile. Non era phishing, non sembrava un account creato da mio padre; quindi come altro si poteva spiegare questo stato di cose?
La mia prima ipotesi è stata che si trattasse di un account aperto fraudolentemente a suo nome. Il suo indirizzo di mail e il suo numero di telefono erano facilmente reperibili online; qualcuno potrebbe averli usati per creare un account per qualche truffa. Nel qual caso su quel conto potevano esserci dei soldi… Non miei, certo, ma comunque soldi, da restituire se possibile ai derubati.
La cosa è rimasta ferma per qualche mese, intanto che ci rimuginavo sopra e inseguivo le infinite emergenze di lavoro e di famiglia che sembrano costellare la mia vita da qualche anno (a proposito, scusate se scrivo poco su questo blog ultimamente, ma sto facendo fatica a stare a galla in termini di risorse mentali e di sonno).
Qualche giorno fa è arrivata sulla casella di mail di mio padre l’ennesima mail di Paypal che mi ricordava di accettare le condizioni di contratto aggiornate, e così ho deciso di andare a fondo della questione. Invece di chiedere il reset della password, ho tentato di entrare nell’account Paypal usando le varie password che adoperava mio padre; tentativo disperato, lo so, soprattutto se l’account era stato aperto da un truffatore, ma non mi restavano altre vie percorribili.
Dopo alcuni tentativi falliti, bingo! Non sono riuscito a entrare nell’account, ma mi è comparso l’invito a contattare Paypal per risolvere il problema di accesso. Fra i metodi di contatto c’era anche un numero di telefono, e ho provato a usarlo: spiegare a voce tutta la situazione sarebbe stato infinitamente più facile che farlo per iscritto, e avrei potuto fornire subito eventuali elementi di autenticazione.
Il numero è 800 975 345 per chi chiama dall’Italia da telefono fisso. Per chiamare da cellulare o dall’estero, il numero di Paypal è +39 06 8938 6461. Gli operatori rispondono dalle 9 alle 19.30 italiane.
Ovviamente, da informatico che documenta truffe da una vita, mi sono messo nei panni di un operatore Paypal che riceve da un numero svizzero una telefonata del tipo “Salve, sono l’erede del signor Taldeitali ma non ho la password del suo account, mi può aiutare a prenderne il controllo?” e mi sono reso conto che le probabilità di essere creduto sulla parola per telefono erano veramente esigue. Ma valeva la pena di tentare.
L’operatore che mi ha risposto, Khaled, è stato gentilissimo e molto preciso. Gli ho spiegato con calma la situazione, sottlineando che non mi interessava accedere al conto, almeno per il momento, ma volevo solo sapere se era stato aperto fraudolentemente a nome di mio padre oppure no, perché non riuscivo a immaginare mio padre come titolare di un account Paypal, oltretutto segreto.
L’operatore evidentemente aveva già gestito situazioni di questo tipo e ha individuato molto rapidamente la ragione per cui esisteva l’account Paypal. Non ci sarei mai arrivato da solo. Sì, mio padre aveva davvero un account Paypal, aperto da lui e creato il 3 settembre 2007.
Spoiler: il saldo era zero.
Ho chiesto subito all’operatore se poteva dirmi se il saldo era zero o maggiore di zero, in modo da poter decidere se valesse la pena di avviare la procedura legale di subentro. Nota tecnica: credo che sia importante essere precisi nel formulare le domande, in casi come questi, per non chiedere all’operatore dati che per regolamento o legge non può dare, per cui non ho chiesto il saldo esatto. L’operatore mi ha risposto volentieri che il saldo era appunto zero.
Ma l’operatore mi ha dato anche un’informazione che ha fatto subito quadrare tutti gli indizi: ha detto che l’account era stato aperto automaticamente quando mio padre aveva acquistato una tessera prepagata di Lottomatica. Questo è stato il mio “momento a-HA!”.
Mio padre, infatti, era un accanito giocatore del lotto, con alterne fortune. Aveva perfettamente senso che avesse acquistato una prepagata e che con l’occasione avesse dato il proprio indirizzo di mail e numero di telefono. Aveva sì un account Paypal, ma non sapeva nemmeno di averlo, tant’è che non lo aveva mai confermato per attivarlo pienamente.
E così ora non mi resta che mandare una mail a Paypal, con una copia del certificato di morte, per chiudere l’account e mettere la parola fine a un piccolo mistero di famiglia.
Morale della storia: la realtà è sempre più complessa di quello che si immagina, anche quando si è abituati a pensare che sia complessa. E a volte dietro una mail che sembra phishing c’è una situazione autentica. Questo non vuol dire che si deve abbassare la guardia: i truffatori sono sempre in agguato.
Spero che questo racconto possa essere utile a qualcuno.
19 agosto – Spotorno, Piazza Vittoria ore 21.30. Conferenza: I marziani hanno 12 mani.
Partendo dalle rappresentazioni nei film di fantascienza (dagli alieni umanoidi ad Arrival) la conferenza esplora le possibili evoluzioni degli extraterrestri. Ingresso libero.
Abbiamo celebrato nei giorni scorsi, in una serie di post, il cinquantaseiesimo anniversario del primo sbarco umano sulla Luna, ricordando giorno per giorno quel luglio 1969 in cui avvenne la realizzazione del più antico sogno dell’uomo da parte dell’equipaggio di Apollo 11.
Altre straordinarie missioni si sono succedute dopo quella prima storica esplorazione. Dopo Armstrong e Aldrin, altri dieci uomini hanno avuto modo di vedere con i propri occhi e calpestare con i loro particolari scarponi la superficie del Satellite naturale della Terra.
I volti dei dodici uomini che nel corso del programma Apollo hanno impresso le loro orme sulla superficie lunare. Le foto a colori indicano quelli ancora viventi.
In questi ultimi anni, grazie alla casa editrice Cartabianca Publishing, sono uscite quattro importanti biografie, tradotte in italiano, di astronauti della NASA protagonisti della grande epopea spaziale lunare. Ne consigliamo la lettura.
La più grande avventura del secolo scorso: la folle, intensa e appassionante corsa alla conquista dello spazio e della Luna, il mondo a noi più vicino ma anche incredibilmente lontano, orbitando a oltre 380.000 km dalla Terra.
Chi meglio del comandante della missione Apollo 17 che ha portato gli ultimi uomini sul nostro satellite naturale nel dicembre 1972 può raccontare gli eventi di quella missione culminata nella discesa sul suolo lunare e nella guida della “Rover” che ne hanno percorso la superficie? L’astronauta Eugene Cernan, assieme al giornalista Don Davis, narra con stile discorsivo e linguaggio privo di inutili complessità la vera storia della corsa allo spazio degli Stati Uniti. Una competizione che doveva essere vinta ad ogni costo, sullo sprone delle parole del presidente Kennedy, e proseguita attraverso mille difficoltà fino al successo finale.
Tra tutte le persone che finora hanno avuto il privilegio di volare oltre i vincoli terrestri, una delle più interessanti è senza dubbio l’astronauta statunitense John W. Young, entrato a far parte della NASA nel 1962. Da quei primi anni avventurosi, in cui lanciarsi nello spazio a bordo delle capsule Gemini era un grande rischio, per quanto calcolato, Young è passato alle celebri missioni Apollo, circumnavigando la Luna con Apollo 10 e successivamente facendo escursioni sulla sua superficie nella missione di Apollo 16, sia a piedi che con il caratteristico “Rover” lunare. In seguito la NASA decise di inaugurare lo Space Shuttle, la celeberrima navetta spaziale, senza compiere preventivamente lanci di prova senza equipaggio. E John W. Young era ai comandi di quel primo Shuttle. Negli anni successivi Young ha continuato a lavorare per la NASA, occupandosi soprattutto di sicurezza degli equipaggi. Questo libro descrive minuziosamente tutto ciò che è accaduto a terra e nello spazio durante quarant’anni di attività della NASA, narrato da uno dei protagonisti.
Nel luglio 1969, Michael Collins era il pilota il modulo di comando dell’Apollo 11, consentendo ai compagni di viaggio Neil Armstrong e Buzz Aldrin di calpestare per la prima volta la superficie di un altro corpo celeste; un evento definito “la più grande avventura dell’umanità”. In questo appassionante libro di memorie, Collins racconta – in modo personale e “senza filtri” – il dramma, la bellezza e persino l’umorismo di quell’epica missione. Ma ripercorre anche la sua carriera professionale, dalle prime esperienze di volo nell’Aeronautica militare alle vicende come pilota collaudatore, fino al coinvolgimento nel progetto Gemini e alla sua prima passeggiata spaziale con la Gemini 10 nel luglio del 1966, prologo alla successiva missione lunare che lo ha consegnato alla Storia.
Fred Haise, pilota del modulo lunare dell’Apollo 13, prima della partenza ricevette alcune lettere in cui gli si chiedeva se temesse che una missione con quel numero potesse essere sfortunata. Non essendo una persona superstiziosa, le gettò via senza pensarci due volte. Ma tre giorni dopo l’inizio della missione Apollo 13, nell’aprile del 1970, un’esplosione a bordo costrinse l’equipaggio a trasformare il modulo lunare in una scialuppa di salvataggio di fortuna per poter rientrare in sicurezza sulla Terra. E quella non sarebbe stata l’ultima volta che Haise si sarebbe trovato ad affrontare una situazione potenzialmente fatale.
Anche stamattina è arrivata la solita mail del complottista lunare di turno.
Sei ancora convinto che siano andati sulla Luna?
La mia risposta, che potete usare liberamente se vi sembra utile:
No. “Convinto” non è la parola giusta. Tanto vale chiedermi se sono “convinto” che la gravità esiste. Esiste e basta, e o uno accetta questo fatto, oppure è libero di negarlo e dimostrare di aver ragione mettendosi a fluttuare a mezz’aria.
Non è una questione di fede, ma di accettare i fatti.
Semmai, chiediti tu una cosa: perché vuoi a tutti i costi negare un evento documentatissimo, verificato da fonti scientifiche indipendenti, confermato persino dai rivali sovietici? Come mai ci tieni così tanto?
Se vuoi levarti i dubbi, leggi il mio libro gratuito: lo trovi presso Luna1969.info. L’ho realizzato con la consulenza di numerosi esperti internazionali di esplorazione e ingegneria spaziale e di molti protagonisti diretti, anche italiani, delle missioni lunari. Ma se ritieni di saperne di più di loro, o se pensi che qualcuno che hai visto su YouTube sia più competente di loro, non leggerlo.
Credi quello che ti pare; non ho alcun desiderio o bisogno di convincerti. Il tuo rifiuto di accettare un fatto storico non cambia la realtà.
Non ho tempo per dibattiti personali su questo argomento, per cui mi perdonerai se non risponderò a ulteriori tuoi messaggi.
La qualità delle immagini e dei video generati tramite intelligenza artificiale sta aumentando molto rapidamente. I miei timidiesperimenti di due anni fa, rivisti oggi, fanno sorridere se confrontati con quello che viene pubblicato adesso: immagini fotorealistiche, non più plasticose e inespressive, in alta risoluzione, in movimento, con audio sincronizzato e labiale corretto, e persino con musiche e canzoni altrettanto generate.
Sono immagini che cominciano a rendere possibile raccontare una storia, e raccontarla con una qualità visiva che sarebbe costosissima da ottenere con le tecniche tradizionali (compresa la grafica digitale) e che invece l’uso esperto dell’IA permette di ottenere a costi abbordabili anche per un semplice appassionato. È una democratizzazione straordinaria della possibilità di esprimersi.
Considerate per esempio Kira, un corto (14 minuti) dedicato alla clonazione umana realizzato da una singola persona, Hashem Al-Ghaili (1 milione di follower su Instagram), realizzato interamente con immagini generate tramite IA e con un notevolissimo lavoro di montaggio manuale. Al-Ghaili dice di aver creato quasi 600 prompt e di averci messo dodici giorni del proprio tempo libero, spendendo 500 dollari. Il risultato è impressionante: ci vuole un occhio molto attento per notare le piccole imperfezioni tipiche di questa tecnica di creazione di immagini.
Secondo quanto riportato nei titoli di coda, i software utilizzati per la generazione delle immagini sono Whisk, Runway, Midjourney, Dreamina, Sora, Flow/Veo 3, Higgsfield e Kling.ai; le voci sono state generate usando Elevenlabs; la sincronizzazione del labiale è stata ottenuta con Flow/Veo 3, Dreamina e Heygen; la musica è stata generata tramite Suno; gli effetti sonori sono stati prodotti usando MMaudio ed Elevenlabs. I prompt sono stati ottimizzati tramite ChatGPT. Il montaggio, invece, è stato eseguito digitalmente ma a mano da Al-Ghaili.
L’IA generativa, usata in questo modo, spalanca le porte alla creatività di chi prima non avrebbe avuto i mezzi tecnici ed economici per manifestarla. Allo stesso tempo, ovviamente, riduce anche i costi delle produzioni commerciali: l’IA è stata già usata per esempio per conferire agli attori del film The Brutalist un accento ungherese nativo [Northeastern.edu; CNN], e Netflix ha dichiarato con una certa fierezza che la sua serie L’Eternauta (ispirata al celebre fumetto), prodotta in Argentina, include una scena realizzata usando immagini generate da IA: il crollo di un edificio a Buenos Aires è stato creato in questo modo, richiedendo un decimo del tempo che sarebbe stato necessario con effetti visivi fisici o digitali tradizionali (usati peraltro in grande abbondanza) e a un costo sostenibile per la produzione, che altrimenti avrebbe dovuto rinunciare alla scena.
E’ il giorno del rientro sulla Terra per i tre astronauti ormai entrati nella storia: Neil Armstrong, Edwin “Buzz” Aldrin e Michael Collins. A causa dell’arrivo del tifone “Claudia”, il punto di ammaraggio dell’Apollo 11 nell’Oceano Pacifico è stato spostato, la sera precedente, di circa 450 km; lì ci sarà ad attenderli la portaerei Hornet per il recupero dei tre astronauti e dell prezioso materiale lunare raccolto.
24 luglio, giovedì
Ore 01:04 italiane. Viene effettuata l’ultima trasmissione televisiva a colori dallo spazio, che dura dodici minuti. Durante il collegamento i tre astronauti tirano le somme sul significato del volo di Apollo 11, poi inquadrano la Terra in avvicinamento. Armstrong, Collins e Aldrin si trovano a 170.000 km dal nostro pianeta.
Il giorno del rientro di Apollo 11 sulla Terra nelle prime pagine de “La Stampa” e “Il Resto del Carlino” (dalla collezione personale di Gianluca Atti).
Ore 15:30 italiane. Dopo aver riposato e consumato l’ultimo pranzo nello spazio, i tre astronauti si preparano per le ultime delicate fasi del fantastico volo.
Ore 18:21 italiane. Il modulo di comando si distacca dal modulo di servizio e compie la manovra per assumere la posizione di rientro nell’atmosfera terrestre. Il veicolo ora è capovolto, in modo da presentare in avanti la base piatta protetta dallo scudo termico.
Nella rappresentazione artistica della NASA il modulo di comando si distacca dal modulo di servizio, abbandonandolo nello spazio.
Ore 18:35 italiane. La navicella, tutto ciò che rimane dell’immensa struttura lanciata da Cape Kennedy il 16 luglio, a un’altitudine di 120 km inizia il rientro nell’atmosfera. L’ingresso nel “corridoio di rientro” deve avvenire esattamente in un dato punto, con un determinato assetto ed un preciso angolo di discesa. Giungendo con un angolo più ampio del previsto, il veicolo non resisterebbe alle intensissime forze aereodinamiche che lo contrastano e finirebbe con il disintegrarsi. Arrivando con un angolo di discesa minore, potrebbe rimbalzare sugli strati esterni dell’atmosfera e trovarsi respinto nello spazio. Ha inizio il periodo di silenzio radio, il cosiddetto “blackout”, causato dal fatto che la capsula comprime violentemente, e quindi surriscalda, l’aria davanti al proprio fondo quasi piatto; questo calore intensissimo ionizza l’atmosfera intorno al veicolo, creando una barriera per le onde radio.
Raffigurazione artistica della NASA del rientro della capsula Apollo 11 nell’atmosfera terrestre.
Ore 18:44 italiane. Terminato il silenzio radio e ripristinati i collegamenti tra il veicolo spaziale e la base a terra, si dispiegano i primi paracadute ausiliari, utili per iniziare la frenata della navicella verso l’Oceano.
Ore 18:45 italiane. Si aprono i paracadute principali.
Ore 18:50 italiane. Apollo 11 ammara nell’Oceano Pacifico, a 24 km dalla portaerei Hornet, ammiraglia delle forze di recupero. La prima missione umana con esplorazione del suolo lunare è durata complessivamente 195 ore, 18 minuti e 35 secondi.
I tre astronauti a bordo del canotto poco dopo l’ammaraggio con indosso la tuta anticontaminazione. Accanto a loro il veicolo che li ha portati nello straordinario viaggio Terra-Luna-Terra (foto AP11-S69-21698).
Ore 20:12 italiane. Armstrong, Collins e Aldrin giungono a bordo della Hornet dopo aver indossato le speciali tute d’isolamento biologico. Ad attenderli sulla portaerei c’è il Presidente degli Stati Uniti, Richard Nixon.
Foto AP11-S69-21365.
Per i tre astronauti di Apollo 11 ha inizio un periodo di quarantena voluta per evitare eventuali pericoli di contaminazione da parte di germi lunari. Torneranno liberi alle 04:04 dell’11 agosto 1969, lunedì.
Il giusto tributo all’impresa lunare dei tre astronauti americani di Apollo 11 sui principali quotidiani italiani (dalla collezione personale di Gianluca Atti).
Le copertine e gli inserti dei settimanali Epoca e L’Europeo usciti nelle edicole nei giorni successivi al ritorno a Terra di Armstrong, Collins e Aldrin (dalla collezione personale di Gianluca Atti).
Prosegue tranquillo il viaggio di ritorno verso la Terra di Armstrong, Collins e Aldrin. Gli ultimi due giorni che li separano dallo “splashdown” previsto nell’Oceano Pacifico sono impiegati dai tre astronauti per compiere alcuni esperimenti riguardo l’orientamento interplanetario servendosi delle stelle, il resoconto di alcuni particolari che riguardano l’esplorazione avvenuta nel Mare della Tranquillità, richiesti dai numerosi scienziati presenti a Houston, e le ultime trasmissioni televisive programmate.
Ore 03:08 italiane. Viene riaccesa la telecamera a colori a bordo dell’Apollo per una trasmissione televisiva, la penultima nel programma di volo, della durata di diciotto minuti. Durante il collegamento vengono inquadrate la Luna, ormai alle spalle degli astronauti, e la Terra, ancora lontana a 297.000 km ma prossima a essere raggiunta.
Armstrong mostra ai telespettatori i contenitori nei quali sono racchiuse le rocce lunari raccolte durante l’escursione sul suolo selenico. “Buzz” Aldrin, inquadrato, mostra una delle bevande di bordo, sigillate in un sacchetto, e fa vedere come si spalma il paté di prosciutto sul pane in assenza di peso. Michael Collins, padrone di casa in quanto pilota del modulo di comando, dimostra come l’acqua nonostante l’assenza di gravità rimanga attaccata al cucchiaino e come si beve a bordo del veicolo spaziale.
Alcune immagini tratte dalla penultima trasmissione TV dall’Apollo 11.
Le prime pagine di alcuni quotidiani alla vigilia del rientro sulla Terra dei tre uomini dell’Apollo 11 (dalla collezione personale di Gianluca Atti).
Ore 17:30 italiane. All’equipaggio viene data la sveglia dal Centro di Controllo di Houston dopo aver dormito otto ore.
Ore 21:44 italiane. Apollo 11 supera la metà della distanza Terra-Luna. Tra meno di ventiquattro ore l’intero pianeta è pronto a riabbracciare i tre eroi della Luna, di nuovo a casa!
Dopo gli straordinari avvenimenti che hanno visto quasi l’intera umanità incollata davanti ai televisori per seguire i primi passi di due uomini su un altro corpo celeste al di fuori della Terra, i tre astronauti di Apollo 11, Armstrong, Aldrin e Collins, sono di nuovo insieme, pronti a lasciare l’orbita lunare e a rimettersi in viaggio verso la “casa” Terra.
22 Luglio, martedì
Ore 01:45 italiane. NeilArmstrong e Edwin “Buzz” Aldrin, insieme con il materiale lunare raccolto, rientrano nel modulo di comandoricongiungendosi con Collins. I due hanno anticipato il rientro sul “Columbia” dopo aver segnalato una serie di vibrazioni a bordo del Lem poco dopo l’aggancio tra i due veicoli.
Ore 01:55 italiane. Terminato il suo straordinario compito, “Aquila” viene sganciata da “Columbia” e abbandonata in orbita lunare.
Il successo della prima esplorazione umana della Luna sulle prime pagine dei quotidiani e settimanali italiani (dalla collezione personale di Gianluca Atti).
Ore 06:56 italiane. Dopo aver consumato un veloce pasto, dal Centro di Controllo di Houston viene dato l’ordine di lasciare l’orbita lunare. Viene acceso per circa tre minuti il motore principale (SPS) del modulo di servizio, che sottrae “Columbia” all’attrazione lunare immettendola nella traiettoria di ritorno verso la Terra.
Nella raffigurazione artistica della NASA il veicolo spaziale Apollo, lasciata la Luna, si dirige verso la Terra.
Ore 22:02 italiane. Lieve correzione di rotta necessaria per mantenere “Columbia” con il suo prezioso carico umano, nello stretto corridoio ideale, calcolato dai cosiddetti “cervelli” elettronici, che porta diritto dalla Luna fino al nostro pianeta. Secondo il programma di volo, il rientro a terra di Apollo 11 è previsto per giovedì 24 luglio.
Un ultimo sguardo alla Luna per i tre di Apollo 11 prima di riprendere la strada di casa (foto AS11-44-6667).
L’uomo, anzi due uomini, a bordo di uno strano e buffo ma straordinario veicolo, hanno realizzato uno dei più antichi sogni dell’umanità: arrivare sulla Luna! Ora Armstrong e Aldrin, due dei tre protagonisti della missione Apollo 11, attendono il “go” da terra per iniziare l’escursione sul suolo selenico a cui assisterà in diretta televisiva l’intero pianeta Terra.
21 luglio, domenica
Ore 00:30 italiane. Il Centro di Controllo di Houston, in Texas, autorizza Armstrong e Aldrin ad anticipare, su loro richiesta, l’uscita dal Lem per iniziare l’esplorazione lunare, prevista inizialmente dal piano di volo per le 08:17 italiane.
Lo storico allunaggio di Armstrong e Aldrin sulla Luna a bordo del Lem “Aquila” sulle prime pagine dei quotidiani italiani (dalla collezione personale di Gianluca Atti).
Ore 03:53 italiane. Ha inizio la depressurizzazione interna del modulo lunare in previsione dell’apertura del portello di “Aquila” e della discesa del primo uomo che metterà piede sulla Luna.
Ore 04:39 italiane. Il comandante di Apollo 11, Neil Armstrong, comunica al Centro di Houston che il portello è stato aperto.
Ore 04:49 italiane. Armstrong inizia la discesa dalla scaletta. Tirando un anello semicircolare collegato a un cavo, sblocca e apre un vano nel modulo di discesa del Lem dove è installata una telecamera in bianco e nero, che riprenderà non solo i primi passi umani sulla Luna ma l’intera esplorazione dei due astronauti.
Ore 04:56 italiane. Il comandante di Apollo 11, scesi i nove gradini della scaletta del Lem, tocca con il piede sinistro il suolo della Luna.“E’ un piccolo passo per un uomo”, esclama, “un balzogigantesco per l’umanità”. Aldrin riprende la scena con la cinepresa a colori installata all’interno del modulo lunare, mentre la telecamera in bianco e nero rimanda le immagini a terra, viste in diretta da milioni di telespettatori.
La discesa dalla scaletta del Lem di Armstrong ripresa dalla telecamera in bianco e nero installata in un vano nello stadio di discesa di “Aquila”.
I primi passi di Armstrong sulla superficie lunare, ripresi dalla cinepresa a colori installata all’interno del modulo lunare.
Ore 05:05 italiane. Armstrong raccoglie i primi campioni del suolo selenico nell’eventualità di una partenza improvvisa.
Armstrong raccoglie con una speciale paletta i primi campioni lunari, quelli denominati “di emergenza”, nel caso di una partenza improvvisa dalla Luna.
Ore 05:15 italiane. Fotografato da Armstrong, anche Aldrin esce dal Lem e scende sul suolo lunare. Descrive tecnicamente l’ambiente che lo circonda, aggiungendo un commento che riassume tutta la straordinarietà del luogo che stanno visitando: “Magnifica desolazione”.
Foto AS11-40-5862.
Foto AS11-40-5863.
Foto AS11-40-5866.
Foto AS11-40-5867.
Foto AS11-40-5868.
La sequenza della discesa dal Lem del secondo uomo nella storia a esplorare la Luna (foto AS11-40-5869).
Ore O5:24 italiane. Armstrong e Aldrin scoprono e leggono la targa commemorativa che rimarrà sulla Luna, montata su una delle gambe di “Aquila”, e che porta le firme dei tre astronauti di Apollo 11 e quella del presidente degli Stati Uniti Richard Nixon. “Qui uomini del pianeta Terra posero piede per la prima volta sulla Luna. Luglio 1969. Venimmo in pace per tutta l’umanità”.
La targa scoperta dai due astronauti a perenne memoria della straordinaria missione lunare (foto AS11-40-5899).
Ore 05:41 italiane. I due astronauti piantano sulla Luna la bandiera degli Stati Uniti. La telecamera in bianco e nero, piazzata a circa venti metri dal Lem, riprende la scena.
Ore 05:48 italiane. Il Presidente Nixon parla dalla Casa Bianca con i due astronauti. Terminata la breve conversazione, Armstrong continua la raccolta del materiale lunare sino a riempire i contenitori che ha con sé. I campioni vengono racchiusi in speciali sacchetti di plastica. Aldrin sistema i vari equipaggiamenti scientifici, denominati ALSEP, per gli esperimenti che rimarranno sul suolo lunare: comprendono un dispositivo sismografico e un riflettore laser.
Viene anche dispiegato un foglio di alluminio per la cattura di particelle solari, che però verrà ripiegato e riportato a bordo del Lem una volta terminata l’escursione. Poco prima di rientrare su “Aquila”, mentre Armstrong completa la raccolta di campioni, Aldrin estrae due “carote” di suolo selenico a una decina di centimetri di profondità.
Aldrin fotografato da Armstrong, riflesso nel visore insieme ad una porzione del Lem e ad un puntino azzurro… la nostra Terra!
La Terra fotografata dal suolo selenico dai primi esploratori lunari (AS11-40-5923).
Ore 06:57 italiane. Dopo un’ora, quarantacinque minuti e sette secondi, Aldrin rientra a bordo del modulo lunare.
Ore 07:09 italiane. Dopo due ore e undici minuti dall’inizio della prima storica esplorazione umana di un corpo celeste diverso dalla Terra, anche Armstrong rientra a bordo di “Aquila”.
Ore 07:11 italiane. Il portello del modulo lunare viene chiuso. Verrà riaperto alle 09:37 italiane per consentire ai due astronauti di gettare sul suolo lunare il materiale che non serve più: zaini, caschi, soprascarpe, guanti. Tutto questo rimarrà sulla Luna insieme alle apparecchiature scientifiche, allo stadio di discesa del Lem, alla telecamera in bianco e nero, a due macchine fotografiche, e altro ancora.
I primi due pedoni lunari lasciano ai piedi del modulo lunare anche una busta contenente degli oggetti commemorativi: l’emblema della missione Apollo 1, in onore di Virgil Grissom, Edward White e Roger Chaffee, i tre astronauti morti nell’incendio della loro capsula sulla rampa di lancio il 27 gennaio 1967; due medaglie in ricordo dei cosmonauti sovietici Yuri Gagarin e Vladimir Komarov; un ramoscello di ulivo, realizzato in oro, e un piccolo disco di silicio che contiene i messaggi scritti da una settantina di capi di stato del mondo oltre a quello di sua santità Paolo VI. Restano su “Aquila”, e ritorneranno sulla Terra insieme ai tre astronauti, più di venti chilogrammi di campioni lunari e il foglio di alluminio per la cattura delle particelle solari.
Armstrong fotografato da Aldrin dopo il ritorno a bordo del Lem. Faccia stanca ma felice per il primo uomo a camminare sulla Luna. (foto AS11-37-5528). Sotto: “Buzz” Aldrin, pilota del modulo lunare e secondo terrestre nella storia a calcare il suolo lunare. (foto AS11-37-5331)
Le prime pagine dei quotidiani italiani arrivati nelle edicole in mattinata e nel primo pomeriggio dopo l’inizio dell’attività sul suolo lunare di Armstrong e Aldrin (dalla collezione personale di Gianluca Atti).
Ore 11:52 italiane. Dopo aver risposto ad alcune domande e curiosità poste dai tecnici e dagli scienziati in collegamento dal Centro di Controllo di Houston, Armstrong e Aldrin possono finalmente rilassarsi con una buona dormita.
Ore 19:54 italiane. Addio Luna! Armstrong e Aldrin decollano dal Satellite naturale della Terra a bordo dello stadio di ascesa di “Aquila”.
Rappresentazione artistica della NASA della partenza dalla Luna della stadio superiore del Lem.
Lo stadio di ascesa di “Aquila” prossimo all’aggancio con “Columbia” e sullo sfondo la Terra, nella splendida foto scattata da Michael Collins. (foto AS11-44-6642)
Ore 23:35 italiane. “Aquila” si ricongiunge con la navicella-madre “Columbia”, rimasta in attesa in orbita lunare. I due veicoli sono a 110 km di altezza dal suolo lunare. I tre straordinari eroi di Apollo 11 sono di nuovo insieme!
Sono trascorsi otto anni da quando il presidente John Fitzgerald Kennedy pronunciò queste parole davanti ai rappresentanti del Congresso degli Stati Uniti: “Credo che questa nazione si debba impegnare a raggiungere l’obiettivo, prima che finisca questo decennio, di far atterrare un uomo sulla Luna e di farlo tornare sano e salvo sulla Terra. Nessun progetto spaziale di questo periodo sarà più impressionante per il genere umano, o più importante per l’esplorazione spaziale a lungo raggio; e nessuno sarà così difficile e dispendioso da compiere”.
Oggi, domenica 20 luglio 1969, con la missione Apollo 11, quella promessa, considerata dai più utopistica, sta diventando realtà.
20 luglio, domenica
Ore 01:22 italiane. Il comandante Neil Armstrong e il pilota del modulo lunare Edwin “Buzz” Aldrin entrano nel Lem “Aquila” per un’ulteriore ispezione.
Ore 03:17 italiane. Finita l’ispezione del modulo lunare, i due piloti rientrano nel modulo di comando “Columbia” e annunciano, in collegamento con la base di Houston, che il Lem è stato trovato in ottime condizioni.
Uno sguardo verso la Terra vista dall’orbita lunare dall’interno del modulo lunare. Al centro, in primo piano, uno dei sedici ugelli dei motori di manovra e di assetto del veicolo (foto AS11-37-5442).
Ore 04:32 italiane. Consumata la cena, i tre astronauti di Apollo 11 iniziano un periodo di riposo.
La grande attesa per il primo sbarco di un equipaggio umano sulla Luna occupa le prime pagine dei quotidiani italiani e di tutto il mondo (dalla collezione personale di Gianluca Atti).
Ore 15:17 italiane. Dopo un periodo di riposo e il pranzo del giorno, Aldrin ritorna all’interno del modulo lunare, seguito quaranta minuti dopo da Armstrong. Insieme effettuano l’ultimo definitivo controllo di tutti gli strumenti del Lem. Prima di lasciare il modulo di comando “Columbia”, i due vengono aiutati da Collins nella vestizione delle tute; poi, dopo aver controllato insieme che i condotti per la pressurizzazione, i contatti radio e tutto il resto siano perfettamente a posto, anche Collins indossa lo speciale indumento spaziale.
Ore 18:00 italiane. Armstrong e Aldrin, dall’interno del Lem, con un comando automatico dispiegano le gambe di atterraggio del “ragno lunare”.
Ore 19:44 italiane. Il Lem, il cui nome in codice è diventato “Aquila” per le comunicazioni con la Terra e tra le due navicelle,si distacca dal modulo di comando “Columbia”. “Aquila ha messo le ali”, comunica Armstrong a terra. Ora i due veicoli, sulla stessa orbita, sono a circa dieci metri di distanza l’uno dall’altro. Collins, rimasto solo a bordo del “Columbia”, osserva attraverso i finestrini della navicella se le gambe di atterraggio del ragno si sono distese completamente e ne dà comunicazione ai due astronauti a bordo del Lem.
Foto AS11-44-6567.
Foto AS11-44-6568.
Foto AS11-44-6576.
Foto AS11-44-6582.
Ore 20:12 italiane. Michael Collins, l’astronauta nato a Roma il 31 ottobre 1930, pilota del modulo di comando, accende i piccoli motori della sua nave spaziale, guidandola su un’orbita leggermente diversa a circa tre chilometri da “Aquila”.
Ore 22:05 italiane. Giunto a 15.200 metri dalla superficie selenica, il modulo lunare “Aquila” inizia la discesa a motore, lasciando l’orbita ellittica descritta sino a quel momento e detta “orbita di trasferta” perché Armstrong e Aldrin possono servirsene per trasferire il Lem su una traiettoria diretta di discesa verso il suolo lunare.
Nel corso delle prime fasi della discesa, Armstrong e Aldrin notano che stanno oltrepassando i punti di riferimento sulla superficie lunare quattro secondi prima del previsto. “Aquila” viaggia troppo veloce e quindi essendo un po’ “lunghi” capiscono che probabilmente atterreranno alcune miglia più ad ovest rispetto al punto previsto.
A 1.800 m sopra la superficie lunare, il computer di navigazione e di guida del modulo lunare richiama l’attenzione dei due uomini a bordo con una serie di allarmi con codice 1202 e 1201, che indicano che il computer di guida si sta sovraccaricando.
Dal Centro di Controllo di Houston i tecnici che seguono il volo, dopo un rapido consulto, tranquillizzano gli astronauti: potete continuare la discesa. Durante l’ultimo tratto Armstrong, guardando dai finestrini, si accorge che il luogo dell’atterraggio indicato dal computer e dalle carte studiate a terra è molto più roccioso e pieno di massi del previsto. A questo punto il comandante di Apollo 11 prende il controllomanuale del Lem.
Ore 22:17 italiane. Il modulo lunare “Aquila”, alla velocità di un metro al secondo, si posa con le gambe del sistema di atterraggio sulla superficie della Luna, precisamente in un punto nel Mare della Tranquillità presso l’equatore lunare. È il comandante Armstrong a dare lo storico annuncio a terra: “Houston, qui Base della Tranquillità , l’Aquila è atterrata!”. L’inclinazione del Lem sul suolo selenico è di appena 4 gradi. il limite di sicurezza per una ripartenza sicura dalla Luna è di 12 gradi.
Sono passate 102 ore, 45 minuti e 40 secondi dal lancio da Cape Kennedy, sono trascorsi otto anni di preparativi dopo la promessa del presidente Kennedy, e probabilmente sono passati migliaia e migliaia di anni da che l’uomo ha sognato di andare sulla Luna: Armstrong e Aldrin sono i primi nella storia a giungere su un corpo celeste al di fuori della Terra.
Foto AS11-37-5449.
Foto AS11-37-5451.
Foto AS11-37-5458.
Queste foto furono scattate dai finestrini del modulo lunare “Aquila” circa un’ora e mezza dopo l’allunaggio, per formare una panoramica d’emergenza e documentare almeno brevemente il sito e non tornarsene a mani vuote qualora si fosse resa necessaria una ripartenza senza escursione. Sono le prime fotografie scattate da un essere umano sulla Luna.
(continua)
Per saperne di più
La conquista della Luna è stata uno degli eventi più importanti della storia dell’umanità e anche la Rai aveva preparato una diretta fiume di trenta ore coordinata da Andrea Barbato e con due commentatori: Tito Stagno in studio a Roma e Ruggero Orlando inviato a Houston. Durante la discesa del Modulo Lunare di Apollo 11 verso la superficie lunare, i due conduttori furono protagonisti di un battibecco in diretta TV: Stagno annunciò l’allunaggio, ma Orlando lo smentì.
Il terzo giorno di navigazione celeste di Armstrong, Collins e Aldrin segna l’attracco al “porto lunare” per Apollo 11: dopo un viaggio di 384.000 km a bordo del loro fantastico mezzo cosmico, i tre si inseriscono in orbita lunare.
19 luglio, sabato
Ore 5:11 italiane. Apollo 11 supera la zona dell’equigravisfera, il punto oltre il quale l’attrazione gravitazionale lunare prevale su quella terrestre.
Il giorno dell’ingresso in orbita lunare di Apollo 11 su alcuni quotidiani italiani di sabato 19 luglio 1969 (dalla collezione personale di Gianluca Atti).
Ore 19:02 italiane. Dopo un periodo di riposo e dopo aver consumato il pranzo, da Houston arriva agli astronauti la comunicazione che autorizza l’Apollo 11 ad immettersi in orbita lunare.
Ore 19:13 italiane. Il “treno spaziale”, composto dal modulo di comando e di servizio e dal modulo lunare, scompare dietro la Luna, interrompendo così il collegamento radio con la Terra. Sul lato opposto del Satellite naturale della Terra viene effettuata la manovra per inserire il veicolo in orbita lunare: l’unico motore del modulo di servizio (SPS) viene acceso per contrastare l’attrazione lunare che, a circa 8.000 km di distanza, ha accelerato l’Apollo 11 fino a circa 9.000 km orari. L’accensione del motore, per sei minuti e 2 secondi, riduce a 3.200 km/h la velocità del veicolo, consentendogli di immettersi in un’orbita ellittica che ha un apocinzio di 314 km e un pericinzio di 112 km.
Nella raffigurazione artistica, l’entrata in orbita lunare del complesso spaziale Apollo 11.
Ore 19:22 italiane. Apollo 11 entra in orbita lunare.
Ore 19:46 italiane. Il complesso spaziale Apollo 11 riappare da dietro la Luna. Cessa così il silenzio radio, detto “LOS”, dalle iniziali di “Loss of Signal”, e il contatto con la Terra viene ristabilito. “Tutto perfetto”, annuncia con la solita calma il comandante Armstrong. Poi aggiunge: “Stiamo ora sorvolando il punto di atterraggio prescelto nel Mare della Tranquillità, ed è esattamente come nelle fotografie scattate da Apollo 10, ma vedere la nostra pista di atterraggio dal vero è un’altra cosa; c’è la stessa differenza fra assistere a una partita di football allo stadio e vederla in televisione”.
La superficie della Luna fotografata dai tre astronauti di Apollo 11 in orbita. Un paesaggio freddo, eppure affascinante. Senza vegetazione, senza luci di città che rivilano vita, uomini o animali. Ma ad ogni giro intorno alla Luna i tre astronauti hanno l’occasione di rivedere la propria casa, dove sono nati, cresciuti e dove ritorneranno dopo questa straordinaria impresa…la Terra!
Ore 21:56 italiane. Viene accesa per la quinta volta dall’inizio del volo la telecamera a colori per la prima trasmissione dall’orbita lunare. Durante i trenta minuti di collegamento, viene mostrata e descritta dai tre astronauti a distanza ravvicinata la superficie selenica sorvolata dall’astronave.
Ore 23:43 italiane. Il motore principale dell’Apollo viene riacceso per 17 secondi per rendere circolare l’orbita intorno alla Luna, con un apocinzio di 122 km e un pericinzio di 112 km. I tre uomini di Apollo 11 hanno come ancorato il loro straordinario “vascello cosmico” al porto della Luna, terzi nella ancor giovane storia dell’astronautica, dopo gli equipaggi di Apollo 8 e Apollo 10. Ora resta la parte più difficile della missione, quella più affascinante e finora unica nella storia dell’umanità: la discesa con la “scialuppa”, il Lem, denominato “Aquila”, in un punto prescelto nel Mare della Tranquillità.
La copertina del Radiocorriere TV con all’interno i programmi della settimana dal 20 al 26 luglio 1969 (dalla collezione personale di Gianluca Atti).
Per i tre astronauti di Apollo 11 il loro pianeta natale, la Terra, appare sempre più lontano. Superata la metà del percorso celeste, per la giornata di domani, 19 luglio, è prevista l’entrata in orbita lunare: la meta finale è sempre più vicina!
18 Luglio 1969, venerdì
Ore 01:31 italiane. Nuova trasmissione televisiva da bordo dell’Apollo della durata di trentacinque minuti. Durante il collegamento viene mostrato sullo sfondo nero dello spazio il nostro pianeta azzurro, sempre più piccolo dagli oblò della navicella; i tre astronauti, passandosi tra loro la telecamera e inquadrandosi a vicenda, mostrano anche l’interno del modulo di comando e le carte stellari con cui seguono la rotta celeste, non solo grazie al computer di bordo e a quelli di terra a Houston ma anche, come gli antichi navigatori, con il…sestante!
Il comandante di Apollo 11, Neil Armstrong, ripreso durante la trasmissione televisiva in collegamento con il Centro di controllo a terra a Houston.
Circondato dal nero buio dello spazio, il nostro pianeta azzurro, ripreso da uno dei finestrini dell’Apollo (foto AS11-36-5381).
Lo straordinario viaggio di Armstrong, Aldrin e Collins continua a riempire le prime pagine, e non solo, dei quotidiani di tutto il mondo. Anche i settimanali usciti nelle edicole, colpiti dalla “febbre lunare”, dispensano inserti e gadget nelle loro pubblicazioni (dalla collezione personale di Gianluca Atti).
Ore 22:40 italiane. Nuova trasmissione televisiva di novantasei minuti: Aldrin, ripreso con la telecamera a colori da Armstrong, ispeziona il modulo lunare e illustra ai numerosi telespettatori i vari dispositivi di bordo; vengono anche mostrati i caschi, i guanti e lo zaino per la sopravvivenza (PLSS), che i due dovranno indossare durante l’escursione sul suolo lunare. I tre astronauti vengono anche informati da terra che da Mosca con un telegramma si assicura che la sonda automatica Luna 15, lanciata dal Cosmodromo di Baikonur, tre giorni prima dell’Apollo e già in orbita lunare, non interferirà con la missione americana.
Aldrin fotografato da Armstrong all’interno del modulo lunare durante l’ispezione (foto AS11-36-5390).
L’interno del Lem, ribattezzato “Eagle”, “Aquila”. Si nota a destra la piccola cinepresa che riprenderà su pellicola la discesa del modulo lunare e successivamente quella di Armstrong e Aldrin (foto AS11-36-5389).
Nonostante l’ottimismo che regna tra gli scienziati e i tecnici della NASA per la felice realizzazione del viaggio di Apollo 11, al di là dei proclami ufficiali, il governo americano si è preparato anche al peggio: nel caso che Neil Armstrong e “Buzz” Aldrin non riuscissero ad allunare regolarmente, schiantandosi sulla Luna, o a ripartire una volta conclusa l’attività sul suolo, è pronto un discorso che il presidente Nixon, dopo aver fatto le personali condoglianza alle vedove, leggerà in diretta televisiva al mondo intero. Ma questo è top secret.
Dopo le emozioni del “liftoff” dalla rampa di lancio di Cape Kennedy e le ore che sono seguite, prosegue regolare il terzo viaggio umano della storia verso la Luna, dopo quelli di Apollo 8 e Apollo 10, che hanno preparato questa straordinaria impresa, che prevede il primo sbarco umano sulla superficie selenica di due degli uomini di Apollo 11.
17 Luglio 1969, giovedì
Ore 02:16 italiane. Viene accesa la telecamera a bordo dell’Apollo per una trasmissione televisiva non prevista dal piano di volo. Per 16 minuti e mezzo le riprese a colori della Terra sono captate dalle stazioni terrestri insieme ai commenti dei tre astronauti. In quel momento il “treno spaziale” formato dal modulo di comando e di servizio e dal modulo lunare si trova a circa 94 mila km dalla Terra.
Armstrong, Collins e Aldrin da circa due ore si sono liberati della combinazione di volo indossata per la partenza, compreso il pannolone e il collettore dell’urina. Hanno indossato una tuta di volo più leggera sopra una calzamaglia più intima, muovendosi molto più liberamente all’interno della navicella. Per i “bisogni” fisiologici dovranno urinare in un tubo collegato a un sacchetto, il cui contenuto verrà poi scaricato periodicamente nello spazio. Per le feci c’è un apposito sacchetto che si applica nella zona perianale e non è sempre detto che ciò che si evacua dal proprio corpo vada a finire tutto nel sacchetto!
La Terra ripresa durante la prima trasmissione televisiva, non prevista dal piano di volo, a circa 94 mila km di distanza dall’Apollo 11.
Ore 03:00 italiane. I tre astronauti, al termine della loro prima giornata spaziale, vanno a dormire con un paio di ore di anticipo, essendo stata annullata la correzione di rotta prevista per le 03:16. Armstrong e i suoi due compagni hanno cenato con salmone, pollo al riso, patate dolci, cacao e succhi di frutta.
I quotidiani di quasi tutto il mondo, esclusi i molti paesi che appartengono alla “cortina di ferro”, arrivati ed esposti nelle edicole, presentano a caratteri cubitali l’inizio della grande avventura dei tre uomini di Apollo 11.
Le prime pagine di alcuni quotidiani e settimanali italiani che a grandi titoli danno la notizia dell’inizio dell’avventura lunare di Apollo 11 (dalla collezione personale di Gianluca Atti).
Ore 14:01 italiane. Armstrong, Aldrin e Collins vengono svegliati dal Centro di Controllo di Houston dopo la loro prima notte trascorsa nello spazio.
Ore 15:32 italiane. A ventiquattro ore dall’inizio del viaggio, Apollo 11 si trova a 187.378 km dalla Terra. La sua velocità è di 5.839 km orari.
Ore 16:32 italiane. I tre astronauti si trovano praticamente a metà strada, la distanza ora dalla Terra è di 193.048 km. La sua velocità è scesa, per effetto dell’attrazione gravitazionale terrestre, a 5.600 km orari.
Ore 18:17 italiane. Avviene una lieve correzione di rotta mediante l’accensione, per tre secondi, del razzo principale del modulo di servizio (SPS). Ora la distanza dalla Terra è di 201 mila km.
Ore 22:00 italiane. Si riaccende la telecamera a colori a bordo dell’Apollo 11 per una nuova trasmissione televisiva della durata di cinquanta minuti.
Cinquantasei anni fa veniva intrapresa la più grande avventura umana di tutti i tempi. Tre uomini all’interno di una navicella sistemata alla sommità di un gigantesco razzo venivano lanciati in direzione della Luna, dove due di loro, a quattro giorni dalla partenza, vi avrebbero messo piede, primi nella storia, realizzando il più antico sogno dell’uomo.
Si tratta della missione denominata Apollo 11, e questa è la cronologia di quei nove giorni che tennero con il fiato sospeso l’intera umanità.
La patch ufficiale della missione Apollo 11.
L’equipaggio di Apollo 11: a sinistra il comandante Neil Armstrong, scelto per essere il primo umano a camminare sulla Luna; al centro Michael Collins, pilota del modulo di comando; e a destra Edwin “Buzz” Aldrin, pilota del modulo lunare.
16 luglio 1969, mercoledì
Ore 10:15 italiane. Sono le quattro e quindici antimeridiane sulla costa orientale degli Stati Uniti e specificamente in Florida. Gli astronauti di Apollo 11, Neil Armstrong, Michael Collins e Edwin “Buzz” Aldrin, vengono svegliati. Dopo essersi lavati e rasati scendono nella mensa della NASA situata all’interno del Manned Spacecraft Operation Building per la colazione: uova, bistecche, pane e marmellata, succo di frutta e l’immancabile caffè. D’ora in poi, sino al ritorno sulla Terra i tre dovranno nutrirsi con i cibi contenuti in sacchetti di plastica confezionati nel vuoto secondo la dieta prevista. Molti di questi alimenti sono disidratati e perciò devono essere ricostituiti aggiungendovi acqua, altri invece hanno le dimensioni di un boccone e possono essere ingoiati facilmente.
L’ultima colazione terrestre prima dell’inizio della grande avventura per l’equipaggio di Apollo 11 (foto KSC-69PC-368).
Terminata la colazione, gli astronauti vengono sottoposti ad un rapido esame medico inteso ad accertare la loro completa idoneità fisica prima che inizino le ultime operazioni per il lancio verso la Luna.
Ore 11:30 italiane. Trovati in ottime condizioni, Armstrong e i suoi due compagni passano alla vestizione. In primo luogo viene applicata sulla loro epidermide, specialmente in corrispondenza del torace, una serie di piccoli sensori che serviranno a misurare i battiti del cuore e il ritmo della respirazione durante tutto il volo e a trasmettere, attraverso un dispositivo radiometrico automatico, i dati raccolti ai medici del Centro di Controllo di Houston, i quali saranno così in grado di valutare in ogni momento le condizioni fisiche dei tre uomini di Apollo 11.
E’ poi la volta della combinazione di volo permanente, simile nella foggia alle tute indossate dagli sportivi durante l’allenamento; poi viene la tuta pressurizzata, contenente una vera atmosfera artificiale, gli attacchi per gli apparecchi di comunicazione e il sistema di evacuazione dei rifiuti corporali. Servirà a proteggere gli astronauti da un eventuale incendio all’interno della capsula o dall’eccessivo calore al momento del rientro nell’atmosfera terrestre.
Foto KSC-69PC-377HR.
Vestizione di Edwin “Buzz” Aldrin.
Michael Collins indossa il cosiddetto Snoopy cap, che è una calottina di tessuto che racchiude la cuffia e i microfoni usati per comunicare quando la tuta è sigillata. Si chiama così perché la sua colorazione bianca con porzioni laterali nere richiama la testa del personaggio dei fumetti Snoopy di Charles Schulz.
Gli astronauti, sigillati nelle loro tute, salgono a bordo del furgone che li porterà alla rampa di lancio.
Ore 12:52 italiane. Armstrong, Collins e Aldrin, preso l’ascensore che corre entro la torre di lancio affiancata al gigantesco razzo vettore Saturn V e raggiunta la passerella che porta alla navicella Apollo, a circa cento metri dal suolo, entrano a turno nella cabina del modulo di comando, aiutati dai tecnici presenti nella cosiddetta “white room”. Dopo che hanno preso posto nelle cuccette, vengono assicurati con le cinghie e iniziano gli ultimi controllo delle apparecchiature. A terra aumenta sempre più la tensione, mentre il conto alla rovescia si avvia verso la conclusione.
Decine di migliaia di persone sono arrivate a Cape Kennedy da ogni parte degli Stati Uniti e da molti altri paesi. Si calcola che per assistere al lancio di Apollo 11 siano stipate sulle spiagge adiacenti al Centro Spaziale Kennedy più di un milione di persone. Sulle tribune erette in vista del complesso di lancio siedono i settemila invitati di riguardo della NASA, tra scienziati, parlamentari, ambasciatori stranieri, uomini d’affari e personalità minori; ad essi si aggiungono i cinquemila giornalisti inviati dai giornali di tutto il mondo, i radiotelecronisti e i cineoperatori. Secondo calcoli fatti alla vigilia del lancio, almeno seicento milioni di persone seguiranno il decollo del Saturn V verso la Luna sui teleschermi di quaranta paesi.
Le prime pagine di alcuni quotidiani italiani il giorno del lancio di Apollo 11 (dalla collezione personale di Gianluca Atti).
Ore 15:32 italiane. Sono le nove e trentadue, ora della Florida. Al termine di un perfetto conto alla rovescia, dal complesso di lancio 39-A avviene la partenza del più potente razzo mai costruito dall’uomo fino a quel momento, il Saturn V. Lingue di fuoco arancione e bianco visibili a 100 chilometri di distanza si sprigionano dai cinque motori F-1 del primo stadio del gigantesco vettore. Il rombo assordante è avvertito fino a 50 chilometri di distanza. Il complesso spaziale, dapprima lentamente poi con una accelerazione sempre più crescente, sale verso il cielo.
Ore 09:32 ora della Florida lo spettacolare lancio del Saturn V.
I tre astronauti sono tutti veterani dello spazio, avendo volato in orbita nel 1966 in tre missioni separate: Neil Armstrong, comandante della missione, 38 anni, con la Gemini 8; Michael Collins, 38 anni, pilota del modulo di comando, con la Gemini 10; e Edwin “Buzz” Aldrin, 39 anni, pilota del modulo lunare, con la Gemini 12.
Nei primi due minuti e mezzo di volo il Saturn V, a una velocità di 9.650 km orari, raggiunge un’altitudine di 61 km, dove avviene il distacco del primo stadio, che ricade in mare. Si accendono quindi i cinque motori J-2 del secondo stadio, che rimangono in azione per circa sei minuti, spingendo il veicolo fino a un’altitudine di circa 185 km e una velocità di oltre 22.500 km orari. Esaurita la sua funzione, anche il secondo stadio si distacca dal vettore, dopo aver consumato 450 tonnellate di propellente.
Il veicolo si trova ormai oltre gli strati densi dell’atmosfera; ciò che rimane del gigantesco vettore che ha lasciato da pochi minuti la rampa di lancio funziona perfettamente e la torre di lancio o sistema di fuga in fase di lancio, ormai inutile, viene sganciata. A questo punto si accende l’unico motore J-2 del terzo ed ultimo stadio, che accelera il veicolo a circa 28.000 km orari, a una velocità cioè bastante ad equilibrarlo in orbita terrestre. Per le statistiche, il lancio del Saturn V-Apollo 11 è il 4.039° oggetto lanciato nello spazio dall’uomo.
Ore 15:44 italiane. Il complesso formato dalla navicella Apollo e dal terzo stadio del Saturn V si inserisce con regolarità in un’orbita di parcheggio intorno alla Terra con un perigeo (punto più vicino al nostro pianeta) di 183 km e un apogeo (punto più lontano) di 190 km. Spento il motore del terzo stadio, i tre astronauti controllano le apparecchiature di bordo per accertare che non vi siano danni dopo il tremendo sforzo del lancio. Intanto nella base di Houston alla quale è passato il controllo del volo dopo il distacco dalla rampa di lancio, i tecnici a terra, insieme agli elaboratori elettronici, eseguono i calcoli per stabilire il momento esatto in cui il veicolo dovrà essere inserito nella cosiddetta “traiettoria translunare”, la via che dovrà essere seguita per intercettare la Luna alla data stabilita.
Ore 18:16 italiane. Subito dopo l’inizio della seconda rivoluzione in orbita terrestre, il motore del terzo stadio viene riacceso per cinque minuti e 23 secondi in modo da passare dalla prima velocità cosmica (28,000 km orari circa), alla seconda velocità cosmica, o velocità di fuga dalla Terra (39.000 km orari circa), necessaria per sottrarre il veicolo alla forza di attrazione terrestre inserendolo nella “traiettoria translunare”. Ha inizio il fantastico viaggio di 73 ore dalla Terra alla Luna.
Il quotidiano “Il Giornale D’Italia”, con uscita pomeridiana, è tra i primi a riportare il felice inizio del volo di Armstrong, Collins e Aldrin (dalla collezione personale di Gianluca Atti).
Ore 18:43 italiane. Il complesso CSM, formato dal modulo di comando (CM) e dal modulo di servizio (SM), si stacca dal terzo stadio del Saturn V al quale rimane agganciato internamente il modulo lunare (LM o “Lem”). I bulloni che tengono uniti i quattro pannelli dell’adattatore entro il quale è avvolto il Lem vengono fatti saltare con un radiocomando inviato dalla navicella. I pannelli dell’adattatore si aprono come petali per consentire al CSM, che sta compiendo una piroetta di 180 gradi, di accostarsi con la prua al modulo lunare.
Ore 18:53 italiane. Il CSM perfeziona la manovra di accostamento effettuando l’aggancio con il modulo lunare.
Ore 19:42 italiane. Il CSM, agganciato prua contro prua al Lem, si stacca dal terzo stadio che si allontana definitivamente, evitando possibili collisioni, per finire in un’orbita solare. L’astronave si trova ora a 29.437 km dalla Terra, viaggia alla fantastica velocità di 4.517 metri al secondo e pesa ora “solo” (rispetto al momento della partenza da Cape Kennedy) 48.365 kg.
(continua)
Per saperne di più: Siamo davvero andati sulla Luna? Le risposte a tutti i dubbi in questo sito:
Questo è il testo della puntata del 14 luglio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: inizio del brano “Dust on the Wind” dei Velvet Sundown]
Riconoscete questa canzone? È “Dust on the Wind” dei Velvet Sundown, una band composta dal cantante Gabe Farrow, dal chitarrista Lennie West, dal tastierista Milo Raines e dal percussionista Orion Del Mar. Questo brano ha oltre un milione e mezzo di ascolti su Spotify, dove la band ha un milione e trecentocinquantamila ascoltatori mensili, accumulati nel giro di poche settimane.
Ma come avrete probabilmente intuito dal fatto che me ne sto occupando in un podcast a tema informatico, i Velvet Sundown hanno una particolarità: non esistono, e la loro musica è generata usando appositi programmi di intelligenza artificiale. O perlomeno così sembra, perché non ci sono conferme assolute, ma soltanto forti indizi.
Questa è la storia di come un gruppo musicale sintetico è arrivato ad avere un successo di questo livello, di come si indaga per capire se una band è reale oppure no, e di cosa significa oggi il concetto stesso di “reale”.
Benvenuti alla puntata del 14 luglio 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
Prima di cominciare, segnalo che questa è l’unica puntata di luglio; la prossima uscirà l’11 agosto.
[SIGLA di apertura]
Alla fine di giugno 2025, su Reddit [qui e qui] è stato segnalato l’insolito successo dei Velvet Sundown, un gruppo musicale che ha iniziato a comparire nelle playlist Discover Weekly, quelle di brani consigliati settimanalmente da Spotify, nonostante avesse tutte le caratteristiche piuttosto evidenti di una finta band generata con l’aiuto dell’intelligenza artificiale.
[CLIP: inizio del brano “Drift Beyond the Flame” dei Velvet Sundown]
Quello che avete sentito adesso è l’inizio di un loro brano, intitolato “Drift Beyond the Flame”: come tanta musica generata, a un ascolto distratto pare orecchiabile e normale, ma se lo si ascolta attentamente, e soprattutto se si leggono le sue parole, ci si accorge che sono blande, banali, superficiali, una compilation di cliché che non ha un senso generale e che non c’entra nulla con il titolo. Cosa che, è vero, si potrebbe dire anche di molti brani scritti inequivocabilmente da artisti umani, ma è comunque un indizio notevole.
Dust on the wind Boots on the ground Smoke in the sky No peace found Rivers run red The drums roll slow Tell me brother, where do we go?
Raise your hand Don’t look away Sing out loud Make them pay March for peace Not for pride Let that flag turn with the tide
Guitars cry out Bullets fly Mama prays while young men die Ashes fall on sacred land We still got time to make a stand
Raise your hand Don’t look away Sing out loud Make them pay March for peace Not for pride Let that flag turn with the tide
Smoke will clear Truth won’t bend Let the song fight ‘till the end
Inoltre la foto del gruppo pubblicata su Spotify ha il tipico aspetto delle immagini sintetiche, e i membri non hanno nessuna presenza online, non hanno mai rilasciato interviste e non hanno un calendario di concerti pubblici.
La “foto ufficiale” dei Velvet Sundown.
Ma siamo nel 2025, e oggigiorno fare una foto di copertina che imiti l’aspetto delle immagini generate dall’intelligenza artificiale potrebbe anche essere una scelta stilistica. Inoltre il fatto di non avere account social* non significa che una persona non esista, perlomeno per ora, e farsi intervistare ed esibirsi in pubblico non sono obblighi: lo fanno anche gli artisti musicali in carne e ossa.
* I singoli membri del gruppo non ne hanno, ma la band ha degli account con numeri assurdamente bassi su Instagram (1728 follower, 4 post), TikTok (60 follower, 2 post) e X (530 follower, 18 post) e Facebook (251 follower).
Per contro, Spotify assegna ai Velvet Sundown il bollino di “artista verificato”, e la musica di questa band è presente anche su altri servizi di streaming, come Apple Music, Amazon Music, YouTube e Deezer.
Una dettagliata indagine svolta dal sito Musically.com fa emergere altri elementi sospetti, come il fatto che la biografia del gruppo cita una loro recensione positiva che viene attribuita alla prestigiosa rivista musicale Billboard ma in realtà non risulta essere mai stata pubblicata, o il fatto che il servizio di streaming Deezer indica che entrambi gli album del gruppo “potrebbero essere stati creati usando l’intelligenza artificiale” secondo i suoi rilevatori automatici. Un articolo pubblicato su Mashable fa notare inoltre che manca qualunque indicazione di un produttore o di altre figure che solitamente partecipano alla creazione di un brano, e tutte le canzoni sono attribuite genericamente alla band, mentre di solito si indicano i nomi degli autori e dei titolari dei diritti dei singoli brani.
Queste indagini rivelano anche che la popolarità dei brani dei Velvet Sundown è dovuta ad alcune specifiche playlist presenti sulle piattaforme di streaming più popolari. Queste playlist sono costruite in modo anomalo: sono raccolte eterogenee di artisti di grande successo nelle quali sono inserite in abbondanza le canzoni di questa band sconosciuta, e hanno un numero molto modesto di follower ma centinaia di migliaia di account che le hanno salvate nelle proprie librerie.
Quasi tutti gli indizi, insomma, suggeriscono che si tratti di una costruzione sintetica accuratamente pianificata e organizzata.
Il caso dei Velvet Sundown è uno dei primi in cui una band dall’aspetto palesemente sintetico acquisisce una discreta popolarità e diventa virale senza ricorrere a espedienti classici come la parodia o l’imitazione delle voci, come era successo nel 2023 con quelle di Drake e The Weeknd [Disinformatico]. E non sarà sicuramente l’ultimo.
La vicenda di questa pseudo-band rivela un problema di fondo tipico di tanti aspetti dell’attuale periodo storico: si sta diluendo il concetto stesso di realtà. Le varie forme di intelligenza artificiale generativa permettono infatti di creare foto, musica, testi, interviste, video di persone – in questo caso artisti musicali – che non esistono. Ma per il pubblico che ne fruisce, per quel milione e mezzo di ascoltatori mensili dei Velvet Sundown, tutto questo è reale. O meglio, la musica che ascoltano esiste indubbiamente, e tutto il resto non conta.
Sì, perché abbiamo infatti progressivamente smaterializzato la musica, passando dall’esibizione obbligatoriamente dal vivo alla registrazione su disco, poi al CD che ha sostanzialmente eliminato la fisicità delle note interne o delle copertine, e poi siamo passati agli MP3 che hanno liquidato quel poco che restava dell’esperienza tattile di maneggiare un disco, e infine siamo arrivati allo streaming, per cui non possediamo neanche più i file delle canzoni che ci piacciono ma abbiamo una semplice lista, una playlist, che sta da qualche parte in un cloud intangibile di cui non siamo proprietari. Eliminare a questo punto anche gli artisti sostituendoli con generatori di musica sintetica, e vedere che la gente ascolta e gradisce questa sbobba sonora da tenere in sottofondo, sembra essere semplicemente un ulteriore passo, logico e inevitabile, in questa direzione.
Un passo, fra l’altro, incoraggiato dal fatto che fa comodo a molti, perché riduce i costi, aumenta i profitti e inoltre evita il problema dei comportamenti scandalosi e illegali che rovinano la reputazione degli artisti e frenano gli incassi delle case discografiche e soprattutto delle piattaforme di streaming.
Non sembra un caso il fatto che il CEO di Spotify, Daniel Ek, abbia dichiarato qualche tempo fa che non intende bandire dalla sua piattaforma la musica generata dalla IA [BBC]. Poco importa che gli artisti reali e le associazioni che si occupano di diritto d’autore facciano notare che questi generatori basati sull’intelligenza artificiale sono stati addestrati usando la loro musica senza pagare un centesimo di diritti [BBC]. C’è, fra loro, chi descrive questo addestramento con parole taglienti e senza compromessi: “furto travestito da concorrenza” [BBC].
Ma al tempo stesso si può obiettare che in realtà dietro ogni artista sintetico c’è eccome una persona reale: quella che genera la musica, ne sceglie i parametri, dà istruzioni a ChatGPT o Suno o Mubert o Google Veo su come creare i testi, le immagini e i video, concepisce la struttura, il look, lo stile e le caratteristiche della band immaginaria.
In altre parole, dietro i Velvet Sundown c’è in ogni caso qualcuno di reale, una o più persone che hanno avuto l’idea, l’hanno sviluppata ed eseguita, hanno lavorato per creare le playlist e hanno studiato i meccanismi e gli algoritmi delle piattaforme di streaming per ottenere il risultato di far diventare virale un gruppo musicale che non esiste.
Un atto creativo, insomma; una sorta di meta-arte, una forma di denuncia di una situazione pericolosa per gli artisti e per la cultura e un’incarnazione dell’ansia diffusa di perdere il controllo di tutto cedendolo alle intelligenze artificiali commerciali. Una denuncia, fra l’altro, mediaticamente efficace, visto che di questa vicenda stanno parlando le testate giornalistiche generaliste di buona parte del pianeta.
E in effetti dopo la prima ondata di clamore iniziale, quando la band si presentava come se fosse composta da persone reali, le informazioni presenti nella pagina Spotify dei Velvet Sundown sono cambiate, e ora parlano apertamente di “un progetto di musica sintetica guidato da una direzione creativa umana, composto, cantato e visualizzato con il supporto dell’intelligenza artificiale. Questo – dice sempre la pagina Spotify – non è un trucco: è uno specchio. Una provocazione artistica, concepita per saggiare i confini dell’essere autori, dell’identità e del futuro della musica stessa nell’era della IA.”
La “bio” del gruppo su Spotify come si presentava il 14 luglio 2025.
Complimenti, insomma, a chiunque si celi dietro questa provocazione: ha funzionato e ha sfruttato astutamente i punti deboli delle piattaforme di streaming. Ma forse arriva tardi, perché da anni c’è già chi li sta sfruttando non per fare arte o meta-arte, ma per fare cinicamente soldi. Tanti soldi. Per l’esattezza, dodici milioni di dollari.
Michael Smith è un musicista cinquantaduenne che vive nella Carolina del Nord. Intorno al 2018, quando l’intelligenza artificiale generativa era ancora un prodotto di nicchia, ha iniziato a generare insieme a un esperto del settore migliaia di brani sintetici ogni mese, piazzandoli sulle principali piattaforme di streaming.
Poi ha pagato delle agenzie per creare migliaia di account fasulli di utenti di queste piattaforme, automatizzandoli in modo che “ascoltassero”, si fa per dire, i suoi brani. Ascoltatori sintetici per musica sintetica, insomma.
In questo modo, le sue “canzoni” sono state “ascoltate” miliardi di volte da questi bot, e siccome le piattaforme di streaming pagano gli artisti qualche millesimo di dollaro ogni volta che una loro produzione viene ascoltata, nel corso di vari anni e fino al 2024 il signor Smith l’ha fatta franca, e ha incassato in totale circa dodici milioni di dollari, sottraendoli con l’inganno alle piattaforme e dividendoli con i suoi complici.
Sappiamo tutto questo perché a settembre 2024 il signor Smith è stato arrestato e incriminato per la sua attività, i cui complessi dettagli tecnici sono raccontati nell’atto d’accusa pubblico del processo che lo riguarda. Uno degli aspetti chiave di questi dettagli è l’uso dell’intelligenza artificiale: è quella che gli ha permesso di avere un numero immenso di brani sul quale spalmare gli ascolti fraudolenti, rendendo molto più difficile per gli operatori delle piattaforme accorgersi che si trattava di un inganno. Ma alla fine, dopo qualche anno, se ne sono accorti lo stesso, e la giustizia ha fatto il proprio corso. O meglio, lo sta ancora facendo, perché il processo non si è ancora concluso [Digital Music News].
Smith al momento rischia alcuni decenni di carcere. Chissà se parte dell’eventuale pena consisterà nel fargli ascoltare la sua stessa musica artificiale.
Nel frattempo, fra l’incudine delle piattaforme di streaming che non fanno controlli adeguati perché inseguono principalmente i profitti, e il martello degli artisti-provocatori e dei truffatori, restiamo noi, poveri utenti, che adesso grazie all’intelligenza artificiale non possiamo più goderci un po’ di musica senza chiederci ogni volta se quello che ascoltiamo sia vero o sia l’ennesima paccottiglia generata.
Se per caso state vedendo comparire nei vostri feed RSS delle puntate del podcast Il Disinformatico risalenti all’anno scorso, non è un errore. Sto lentamente ripostando qui i podcast degli anni precedenti, in modo da avere tutto in un unico blog (questo).
Domani (lunedì) uscirà invece una nuova puntata del podcast.
Premessa: conosco l’autore da una vita per il suo lavoro per il CICAP e per amicizia personale, per cui questa recensione è inevitabilmente influenzata da questo legame, ma ho cercato di essere obiettivo e imparziale.
È uscito pochi giorni fa L’ombra del sudario, descritto come “un thriller tra le pieghe della Sindone”, e ho finito di leggerlo stanotte, intrigato e incuriosito da questa creazione letteraria di Luigi Garlaschelli, chimico, socio emerito del CICAP, noto per i suoi saggi e i suoi esperimenti di replicazione riguardanti fenomeni legati al paranormale religioso, come le stimmate di Padre Pio, il presunto sangue di San Gennaro e, appunto, la Sindone.
Ho sempre letto con piacere i saggi di Luigi su questi temi; scopro con altrettanto piacere che sa anche costruire una storia di fiction intrigante, agile e realistica intorno a questi argomenti, con personaggi ben delineati, uno stile asciutto e preciso e una costruzione ben orchestrata della struttura narrativa.
L’ombra del sudario è anche un libro divulgativo: la storia è un’occasione, ma non un pretesto, per presentare idee, temi e fatti tecnici e storici assolutamente reali calandoli in un contesto avventuroso e dinamico. Molti, leggendo questo libro, finalmente scopriranno cosa ne pensava realmente la Chiesa di questo reperto quando comparve inizialmente oltre settecento anni fa.
L’ho letto tutto d’un fiato (215 pagine) e mi sono divertito, scoprendo dettagli della storia della Sindone che non conoscevo e godendomi le citazioni e le allusioni che chi conosce il CICAP coglierà con particolare gusto aggiuntivo. Molti degli eventi e dei personaggi raccontati sono infatti ispirati da accadimenti e persone reali, ma con ampie licenze letterarie.
Ovviamente non faccio spoiler: vi dico solo dove trovarlo. È disponibile online subito qui presso Cartabianca Publishing (la casa editrice che ha reso possibili le traduzioni italiane delle autobiografie degli astronauti lunari alle quali ho collaborato) a 14 euro su carta e a 6,99 euro in formato digitale (EPUB, Kindle, Apple). La presentazione del libro è invece qui.
Ricorre in questi giorni di luglio 2025 il 50° anniversario della missione congiunta tra una navicella americana Apollo e una russa della serie Soyuz, che ha segnato la prima collaborazione nei viaggi umani nello spazio tra gli Stati Uniti e l’allora Unione Sovietica. Ripercorriamo ora quella prima storica impresa, che mise fine alla grande gara spaziale che caratterizzò gli anni sessanta del XX secolo.
La “patch” ufficiale della storica missione ASTP.
La prima pagina del quotidiano “La Stampa” di martedì 15 luglio che annuncia l’imminente avvio del volo spaziale Apollo-Soyuz (dalla mia collezione personale).
Sono le 14:20 italiane di martedì 15 luglio 1975 quando un potente razzo vettore A2 si innalza nel cielo del cosmodromo sovietico di Baikonur, lanciando verso l’orbita terrestre la navicella Soyuz 19 con a bordo i cosmonauti Aleksei Leonov, comandante della missione, eroe dell’Unione Sovietica e primo uomo nella storia a compiere una “passeggiata spaziale” dieci anni prima durante il volo della Voskhod 2, e Valeri Kubasov, ingegnere, tra i protagonisti della prima saldatura di metalli nello spazio durante la missione Soyuz 6 nell’ottobre del 1969.
Per la storia della cosmonautica sovietica, la missione che decolla oggi è diversa da tutte quelle che l’hanno preceduta per due motivi straordinari e particolari: il primo è che per la prima volta il lancio viene trasmesso in diretta TV in mondovisione, con un seguito di oltre cento milioni di spettatori nella sola Unione Sovietica; il secondo è che a sette ore e trenta minuti di distanza (alle 21:50 in Italia), dalla rampa di lancio 39-B del Centro spaziale Kennedy in Florida, un Saturn IB immette in orbita una navicella Apollo con a bordo tre astronauti allo scopo di incontrare il veicolo sovietico: i tre sono Thomas Stafford, veterano dello spazio, Vance Brand e Donald Slayton.
Pochi minuti dopo il lancio l’Apollo si inserisce in orbita a circa 220 km di altezza con lo stesso grado di inclinazione, ossia 51,8 gradi, della navicella sovietica. È l’inizio della storica missione denominata ASTP (Apollo Soyuz Test Project). L’Apollo di Stafford e la Soyuz di Leonov sono le protagoniste della prima esperienza di cooperazione internazionale nello spazio.
La prima pagina de “La Stampa” di mercoledì 16 luglio 1975 (dalla mia collezione personale).
L’inizio dello storico incontro tra le due potenze spaziali capeggia nella prima pagina del quotidiano politico “L’Unità” (dalla mia collezione personale).
C’è da ricordare che la prima iniziativa spaziale congiunta tra Stati Uniti e Unione Sovietica si era avuta undici anni prima, nel 1964, con gli esperimenti di riflessione delle onde radio mediante il satellite-pallone Echo 2, ma da allora in poi la collaborazione tra le due grandi protagoniste della “corsa spaziale” si è limitata a un semplice, e a volte diffidente, scambio di opinioni.
Tuttavia, grazie anche al miglioramento dei rapporti politici tra i due paesi, tra la fine degli anni sessanta e l’inizio degli anni settanta, durante la presidenza Nixon, la cooperazione si è fatta più concreta, tanto che nel maggio del 1972 è stato sottoscritto un accordo quinquennale che prevede lo studio e la realizzazione di “un sistema compatibile di rendez-vous e aggancio delle stazioni e delle navicelle abitate dell’Unione Sovietica e degli Stati Uniti, al fine di accrescere la sicurezza dei voli umani nello spazio e di avere l’occasione in avvenire di effettuare esperienze scientifiche congiunte”. Il primo obiettivo dell’accordo è un volo combinato in orbita terrestre tra una cosmonave Soyuz e una navicella Apollo.
Gli uomini che compongono i due equipaggi della missione congiunta ASTP: in piedi a sinistra, il comandante dell’Apollo Thomas Stafford; in piedi a destra, il comandante sovietico Alexei Leonov; seduti, da sinistra a destra, gli americani Deke Slayton e Vance Brand e il sovietico Valery Kubasov (foto S75-22410).
I problemi di compatibilità tecnica da risolvere sono numerosi: innanzitutto, le differenze esistenti tra i dispositivi di aggancio dei due veicoli. Per superare l’ostacolo senza dover modificare la struttura originale dell’Apollo, i tecnici della NASA costruiscono uno speciale “modulo di docking”, che da un lato si incastra all’estremità dell’astronave americana, dopo essere stato estratto dal suo alloggiamento posto nell’ultimo stadio del razzo vettore (in pratica si eseguiva l’identica manovra che avveniva durante le missioni verso la Luna con l’estrazione del modulo lunare dall’involucro del terzo stadio), dall’altro risulta adatto a raccordarsi con la Soyuz sovietica.
Un altro problema è rappresentato dalle condizioni di passaggio degli equipaggi da un veicolo all’altro: a bordo dell’Apollo si respira un’atmosfera composta di ossigeno puro con una pressione del 34% dell’atmosfera terrestre, mentre sulla Soyuz si respira la normale aria composta da ossigeno e azoto, e quindi un trasferimento diretto degli astronauti potrebbe provocare dei gravi scompensi organici: a ciò si pone rimedio installando una camera di compensazione nel modulo di aggancio.
Altre difficoltà nella realizzazione dello storico volo riguardano le comunicazioni radio tra i due veicoli una volta in orbita intorno alla Terra e inoltre il superamento delle ovvie barriere linguistiche.
Giovedì 17 luglio 1975 è il giorno stabilito per lo storico aggancio tra la navicella Apollo e la Soyuz, come titola il quotidiano “L’Unità” (dalla mia collezione personale).
17 luglio 1975: il veicolo Apollo fotografato dalla Soyuz in orbita poco prima delle ultime manovre per l’aggancio. Si nota sul “naso” lo speciale dispositivo “Docking Module” (DM) per l’aggancio delle due navicelle.
La Soyuz 19 fotografata da uno dei finestrini dell’Apollo. L’unione fisica tra le due navicelle è sempre più vicina.
Tutti questi problemi vengono felicemente superati e così il 17 luglio 1975, cinquantuno ore e 49 minuti dopo il lancio della Soyuz 19, le due navicelle effettuano un perfetto aggancio in orbita a 225 km di altezza. La manovra è seguita in diretta TV in tutto il mondo. In Italia sono le 18:10 di un caldo giovedì.
Alle 21:19, a tre ore dallo storico “docking”, vengono aperti i portelli della camera di compensazione e i due comandanti Leonov e Stafford si incontrano a metà strada nel tunnel di collegamento: la loro lunga e calorosa stretta di mano viene seguita con entusiasmo e commozione da milioni di telespettatori in tutto il mondo, compresi anche i due cosmonauti Piotr Klimuk e Vitali Sevastiyanov che si trovano a bordo del laboratorio spaziale Salyut 4 da maggio. I due equipaggi si scambiano le rispettive bandiere nazionali insieme al vessillo delle Nazioni Unite. Ricevono dalla Terra che scorre sotto (o sopra?) le loro navicelle i saluti e gli auguri per la buona riuscita del volo da parte del primo ministro sovietico Leonid Breznev e del presidente americano Gerald Ford.
La storica stretta di mano tra i due comandanti e veterani dello spazio Leonov e Stafford (foto ASTP-S75-29932).
Volti sorridenti dopo lo storico aggancio nella grande sala controllo di volo al Centro spaziale di Houston (foto ASTP-S75-28685).
Il presidente degli Stati Uniti Gerald Ford si congratula con i due equipaggi russo-americani per la storica unione in orbita (foto PD-USGOV-NASA).
Una nuova data nella storia dell’astronautica in prima pagina sul quotidiano “La Stampa” di venerdì 18 luglio 1975 (dalla mia collezione personale).
Il successo dell’unione nello spazio di due veicoli spaziali di nazionalità diversa in diretta televisiva in mondovisione, celebrato sulla prima pagina de “L’Unità” (dalla mia collezione personale).
Il programma di lavoro per gli equipaggi nei due giorni in cui le navicelle formano un unico “treno spaziale” è intenso: trentadue esperimenti scientifici, dallo studio sugli effetti della microgravità, all’astronomia, alla medicina e all’osservazione della Terra. Avviene anche una seconda manovra di docking, dopo uno sganciamento e il successivo riaggancio durante la quale è la Soyuz a fare da cacciatore e l’Apollo da lepre, a differenza di quanto è successo nella prima storica operazione.
Particolarmente spettacolare è la realizzazione di una eclisse solare artificiale, durante il quale è l’Apollo che fa da disco di occultazione del Sole, mentre l’equipaggio della Soyuz effettua osservazioni della nostra stella scattando foto della corona solare. I cinque trovano anche il tempo di partecipare in collegamento TV ad una conferenza stampa “spazio-Terra” della durata di trenta minuti con alcuni giornalisti americani e russi che dalle basi a terra di Houston e Mosca seguono lo sviluppo della missione.
Due giorni dopo, il 19 luglio, i due equipaggi si congedano. Sono le 17:26 ora italiana: sbloccato il meccanismo di aggancio, le due navicelle prendono le rispettive strade del ritorno. “Missione compiuta”, comunica il comandante della Soyuz 19 Leonov allontanandosi dall’Apollo. “Bello spettacolo, Soyuz”, gli fa eco il veterano dello spazio Thomas Stafford.
La navicella russa rientra sulla Terra, per la prima volta nella storia dei voli spaziali sovietici in diretta televisiva, il 21 luglio atterrando nelle steppe del Kazakhstan. L’Apollo invece continua ad inanellare giri intorno al nostro pianeta ancora per altri tre giorni: ultimo viaggio del glorioso “vascello” che ha portato ventiquattro americani verso la Luna, dodici dei quali vi hanno camminato, esplorandola e riportando sulla Terra più di trecento chilogrammi di suolo selenico.
Giovedì 24 luglio 1975: l’ultimo ammaraggio di una navicella Apollo. Si concludono la missione ASTP e il glorioso “Programma Apollo”. L’ultimo “splashdown” nell’Oceano Pacifico.
La missione ASTP è un volo congiunto svolto nel miglior modo possibile, anche se nel finale, durante il rientro della navicella Apollo viene evitata per poco una tragedia che sarebbe potuta costare la vita ai tre astronauti americani.
Poco dopo aver effettuato la manovra di ingresso nell’atmosfera, dei gas tossici penetrano dal circuito di ventilazione all’interno della cabina a causa di una valvola degli RCS (Reaction control system, serie di propulsori grandi e piccoli per il controllo dell’assetto) probabilmente aperta per errore da uno dei tre astronauti; inoltre anche i paracadute principali non si aprono automaticamente, richiedendo l’intervento per lo spiegamento manuale da parte di Brand.
In conseguenza di ciò, l’ammaraggio nell’Oceano Pacifico avviene abbastanza violento, capovolgendo la capsula. È Brand che nuovamente interviene azionando il congegno che raddrizza in maniera corretta l’Apollo prima di perdere i sensi. Prontamente il comandante Stafford riesce a fare indossare all’astronauta svenuto una maschera di ossigeno e ad aprire il portellone della navicella, facendo defluire all’esterno i gas tossici e facendo entrare all’interno della cabina la fresca aria marina del Pacifico. Tutto è bene quel che finisce bene, dunque, anche se Stafford, Slayton e Brand rimarranno per circa due settimane in ospedale per osservazioni.
Lo storico volo congiunto dell’ASTP, nonostante il successo e la promessa di continuare la cooperazione tra le due superpotenze, non ebbe un seguito immediato, anche a causa dell’invasione sovietica dell’Afghanistan. Bisognerà attendere il febbraio del 1994, tre anni dopo la caduta dell’Unione Sovietica, per vedere un cosmonauta russo viaggiare insieme ad astronauti della NASA (Sergei Krikalyov, nella missione della navetta Discovery STS-60), e venti anni esatti, nel giugno 1995, per vedere di nuovo un veicolo della NASA, lo Shuttle Atlantis (STS-71), attraccare alla stazione orbitale russa MIR nell’ambito del programma russo-americano Shuttle-Mir.
29 giugno 1995: di nuovo russi e americani uniti nello spazio. La navetta Atlantis (STS-71) agganciata alla stazione spaziale MIR.
“Vent’anni dopo” non è solo il titolo del romanzo di Alexandre Dumas ma vale anche come titolo del secondo incontro con aggancio tra un veicolo spaziale della NASA e uno russo. Dal quotidiano “Il Giornale” di venerdì 30 giugno 1995 (dalla mia collezione personale).
Prima della collaborazione fra Russia e Stati Uniti per costruire e occupare la Stazione Spaziale Internazionale, prima dei voli dello Shuttle statunitense verso la stazione spaziale sovietica Mir, in tempi di Cortina di Ferro e guerra fredda, quando non si parlava ancora di glasnost o perestrojka, ci fu una missione spaziale congiunta sovietico-americana, nella quale un veicolo spaziale degli Stati Uniti e uno dell’Unione Sovietica si incontrarono e i rispettivi equipaggi si strinsero la mano, in un memorabile gesto simbolico di distensione: la Apollo-Soyuz.
Tra pochi giorni ne ricorre il cinquantenario: il veicolo Apollo partì dagli Stati Uniti il 15 luglio 1975, portando nello spazio tre astronauti (Stafford, Slayton e Brand) e raggiungendo in orbita intorno alla Terra il veicolo Soyuz decollato poche ore prima dal cosmodromo di Baikonur in Kazakistan, allora facente parte dell’Unione Sovietica, con a bordo i cosmonauti Leonov e Kubasov.
Illustrazione del 1973 del volo congiunto della navicella Apollo (a sinistra) e del veicolo Soyuz (a destra). In mezzo, agganciato al veicolo statunitense, il vano pressurizzato di raccordo fra i due veicoli. Immagine NASA S73-02395.
Una collaborazione del genere tra superpotenze nucleari nemiche non era certo frutto dell’improvvisazione: erano stati necessari anni di lunghissime trattative politiche e diplomatiche (quale nome mettiamo per primo facendolo sembrare più importante? Soluzione: Apollo-Soyuz in USA, Soyuz-Apollo in URSS), per non parlare delle risoluzione di innumerevoli aspetti tecnici.
Dalla traduzione dei rispettivi manuali di lancio e di volo alle decisioni su come rendere compatibili due sistemi di attracco e di pressurizzazione drasticamente differenti (con pressioni operative molto differenti fra i due veicoli), dalla risoluzione dei problemi di comunicazione radio alle tecniche di rendez-vous, fu necessario uno sforzo tecnico e organizzativo straordinario. E c’era poi il problema che gli statunitensi sapevano benissimo che i sovietici li avrebbero spiati e avrebbero fatto di tutto per carpire i segreti della tecnologia spaziale americana, di gran lunga superiore a quella russa, eppure bisognava collaborare per il bene della missione.
Gli equipaggi della missione Apollo-Soyuz: in piedi a sinistra, il comandante americano Thomas Stafford; in piedi a destra, il comandante russo Alexei Leonov; seduti, da sinistra a destra, Deke Slayton e Vance Brand (per gli Stati Uniti) e Valery Kubasov (per l’Unione Sovietica). Foto S75-22410, marzo 1975.
A livello personale, fra astronauti e cosmonauti nacque un’amicizia che continuò per decenni, in particolare fra i comandanti, Stafford e Leonov. Ricordo con piacere l’incontro con Leonov a Martigny, nel 2015, in cui il cosmonauta spiegò che dopo anni di studio dell’inglese si rese conto che la sua controparte non parlava inglese, ma Oklahomski. Entrambi ci hanno lasciato (Leonov nel 2019, Stafford nel 2024); di quegli equipaggi è vivo ancora soltanto Vance Brand, oggi novantaquattrenne. Slayton è morto nel 1993, Kubasov nel 2014.
Insieme all’amico Gianluca Atti, racconterò alcuni aspetti di questa missione molto particolare (l’ultimo volo di un veicolo Apollo) in una serie di articoli. Se volete approfondire l’argomento, sul sito della NASA c’è una sezione apposita, insieme a un libro scaricabile di 580 pagine, pubblicato nel 1978 (e tutto scritto usando il sistema metrico decimale, che in quegli anni si tentò di introdurre negli Stati Uniti).
Nel frattempo, dalla Russia arrivano queste immagini. Cinquant’anni dopo Apollo-Soyuz, una navicella cargo Progress (la versione senza equipaggio della Soyuz, derivata dal veicolo di mezzo secolo fa) viene approntata per il lancio, sempre presso il centro di lancio di Baikonur. Sul suo rivestimento esterno spicca il logo della missione Apollo-Soyuz.
Ho chiesto a Meta AI, la versione integrata in Whatsapp, un’informazione molto semplice: Quante R ci sono nel padre nostro (minuscolo solamente perché andavo di fretta). Risposta generata dai potentissimi server di Zuckerberg per i quali Meta sta spendendo cifre allucinanti:
Persino io so che questo non è il Padre Nostro corretto: quell’assurdo “indurre in tentazione” è stato finalmente corretto ufficialmente nel 2018 [Il Mattino]. Ma Meta AI non lo sa. Complimenti.
Sul fatto che Meta AI trovi soltanto cinque lettere R nel Padre Nostro non aggiungo alcun commento. L’errore è talmente grossolano che si commenta da solo.
2025/06/27 8.25
Nei commenti è stato segnalato il fatto che sbagliare il conteggio delle lettere in una parola o frase è un limite intrinseco dei grandi modelli linguistici (LLM), che funzionano sulla base dei cosiddetti token e quindi non “vedono” le lettere come le vediamo e consideriamo noi. Dario Bressanini sottolinea questo concetto in questo bel video [Facebook] e dice che chiedere a una IA di contare le lettere significa non conoscere bene lo strumento. Con l’aiuto (riveduto) di Whisper, ecco la trascrizione del video:
Non chiedete a ChatGPT! Lo so che lo fate, lo fanno tutti, lo faccio anch’io, è una tendenza sempre più diffusa, specialmente tra gli studenti, ma è un errore. Ora vi spiego meglio, e alla fine vi darò un consiglio.
L’intelligenza artificiale, o meglio gli LLM, i Large Language Model, modelli di linguaggio di grandi dimensioni, sta sostituendo Google per molte ricerche e se ne è accorto anche Google, che ha introdotto nei suoi risultati riassunti generati dalla sua AI Gemini.
Sempre più studenti chiedono a ChatGPT aiuto sugli argomenti più disparati o per risolvere degli esercizi, ma fidarsi ciecamente delle risposte è un rischio. Tempo fa ho letto un’intervista al premio Nobel Giorgio Parisi in cui raccontava di aver convinto un modello linguistico che 5 per 4 fa 25. Parisi ovviamente sa benissimo come funzionano questi sistemi, dato che la matematica su cui si basano è molto vicina ai suoi studi. Ma molte persone, studenti compresi, non hanno idea di cosa siano davvero questi modelli e vedo sempre più gente dire “Ah, ho chiesto a ChatGPT” e prendere per oro colato le sue risposte. È il nuovo “l’ha detto la televisione”, dopotutto si chiama intelligenza artificiale, no? Dovrebbe dare le risposte giuste.
E invece no, il punto chiave è che questi sistemi non sono stati progettati per dire la verità. La G di GPT sta per Generative. Il loro compito è generare testo plausibile in base al loro addestramento, non fornire risposte corrette. Se gli chiedete di risolvere un’operazione matematica, sbaglia e vi lamentate, fate solo la figura di chi non ha capito come funzionano questi sistemi. Come si dice, it’s a feature, not a bug: non è un errore, è una caratteristica. Il fatto che la si possa convincere che 5 per 4 faccia 25 non è una prova che l’intelligenza artificiale sia inaffidabile, ma è proprio la dimostrazione di come realmente funzioni. E non è un motivo valido per sottovalutare quello che di incredibile può fare.
Se vi lamentate pubblicamente perché ChatGPT conta male il numero di lettere R in una parola, non avete smascherato un truffatore, avete solo dimostrato di non aver capito lo strumento, facendo la figura del picio. È come provare a piantare un chiodo con un cacciavite e poi lamentarsi che non funziona bene. Beh, la colpa non è del cacciavite, ma vostra che lo state usando. Per piantare un chiodo serve un martello.
Detto questo, le persone vogliono risposte affidabili. Non gli basta avere un LLM che generi solo testo plausibile ma inventato. Vogliono fatti, vogliono certezze, e quindi le aziende si stanno adattando. Ora ChatGPT, Perplexity e altre aziende hanno strumenti che possono cercare sul web e riassumere le informazioni trovate. Google per esempio ha introdotto il suo Deep Research e funziona in modo impressionante, provatelo.
Ma il cuore del sistema resta sempre lo stesso, un modello linguistico addestrato per prevedere la parola successiva, o meglio il prossimo token, sulla base delle precedenti, indipendentemente dal valore di verità. Se nell’addestramento ha trovato più testi che dicono per esempio che aceto e bicarbonato siano un buon detergente, ripeterà questa informazione, anche se è una scemenza, e affinare i prompt può migliorare la risposta, ma non risolve il problema della radice. Forse dovrebbe leggere i miei libri.
Io li utilizzo moltissimo, li trovo straordinari, per fare il brainstorming, strutturare appunti sparsi, traduzioni, riassunti di documenti complessi, no, ve l’ho fatto vedere in due vecchi video, Il controllo della struttura logica di un articolo, la creazione di quiz a risposta multipla per gli esami, sbobinando le mie lezioni, scalette per approfondire un argomento, mappe concettuali e così via. E quando scrivo del codice in Mathematica, o faccio operazioni avanzate con Excel, o scrivo degli script complessi per la Z Shell che uso, il risparmio di tempo è notevolissimo.
Ma per usarli al meglio è necessario capire come funzionano internamente, che cosa possono fare e cosa per loro natura ancora non riescono a fare.
Non sono oracoli, generano testo basandosi sulle probabilità, bisogna sapere cosa aspettarsi e soprattutto verificare quello che producono. La sfida più grande oggi credo sia proprio quella di far capire agli studenti, e non solo ovviamente, che chiedere a ChatGPT non è sbagliato di per sé, ma lo diventa se ci si aspetta che la risposta sia sempre giusta. La verifica delle fonti rimane fondamentale, in pratica dovete usare la vostra intelligenza, non la sua.
Se volete capire meglio quali sono le basi della cosiddetta intelligenza artificiale moderna vi posso consigliare questo libro, Why Machines Learn: l’ho comprato un po’ di tempo fa, e spiega i fondamenti matematici, perché c’è della matematica alla base del funzionamento delle moderne reti neurali, a partire dagli anni 50, con i primi studi sul perceptrone, sulle prime reti neurali molto semplici, i primi successi, i primi fallimenti, fino ad arrivare ai giorni nostri, e spiega in dettaglio, ma non è assolutamente pesante (c’è un po’ di matematica, ma è sufficiente che vi ricordiate la matematica delle scuole superiori), però spiega molto bene come funzionano internamente questi sistemi che poi sono la base dei moderni modelli linguistici.
È un libro interessante, l’ho comprato e poi qualche tempo dopo mi è stato spedito senza che io lo chiedessi da Apogeo, che ringrazio però, insomma, avevo già letto la versione in inglese. Se uno va a fondo e capisce qual è la base di questi sistemi, capisce anche che è stupido lamentarsi perché “Ah il sistema non riesce a fare 4 più 5” oppure “l’ho convinto che 4 più 5 faccia 10”. Quindi se volete andare un po’ oltre vi consiglio appunto uno di questi libri.
Giustissimo, e sono felice di prendermi del picio da Dario. Ma l’esempio si fa lo stesso proprio perché evidenzia un limite d’uso per nulla ovvio, che l’utente medio non si aspetta e che queste IA non ci avvisano di avere. Inoltre mostra l’altro errore, il più pericoloso: l’incapacità di queste IA di ammettere che non sono capaci di fare una cosa.
Dare questi prodotti in pasto al pubblico generico senza mettere bene in evidenza questi limiti significa creare intenzionalmente disastri fregandosene delle conseguenze. Significa, per usare il paragone di Bressanini, vendere un cacciavite spacciandolo per un martello.
Sulle confezioni di candeggina, o di qualunque prodotto potenzialmente pericoloso, la legge obbliga a scrivere delle avvertenze belle grosse e in evidenza. Perché non possiamo chiedere che si faccia la stessa cosa per queste IA? Davvero dobbiamo accettare quella minuscola foglia di fico della scrittina in piccolo in grigio?
Questo è il testo della puntata del 23 giugno 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Il podcast va in pausa per due settimane e tornerà il 14 luglio.
[CLIP: audio di notifica di arrivo di un SMS]
Usate gli SMS per ricevere i codici di sicurezza dei vostri account? Quegli SMS che vi ricordano insistentemente che quei codici non devono essere condivisi con nessuno? Beh, in realtà quei codici vengono spesso condivisi con qualcuno ancora prima di arrivare a voi, perché possono essere letti dagli intermediari che li trasmettono per conto delle grandi aziende che li usano, e quindi non sono affatto sicuri e segreti come molti pensano.
Questa è la storia di come gli SMS “di sicurezza” possono essere intercettati, permettendo di rubare account di posta o di accesso a servizi online di ogni genere anche quando sono protetti, almeno in apparenza, tramite l’autenticazione a due fattori. E al centro di questa storia c’è un bottino di un milione di SMS di autenticazione trafugati e c’è una società di telecomunicazioni svizzera. Ma questa è anche la storia di come si rimedia a questa falla sorprendente e inaspettata.
Benvenuti alla puntata del 23 giugno 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Gli SMS, intesi come messaggi di puro testo veicolati dalla rete telefonica cellulare, esistono da quasi quarant’anni, e resistono piuttosto bene alla frenetica evoluzione della tecnologia. Furono definiti nel 1986 dagli standard tecnici che diedero vita alla rete cellulare digitale GSM, e il primo SMS in assoluto fu inviato a dicembre del 1992, ma ci vollero alcuni anni prima che diventassero disponibili al pubblico i telefonini capaci di inviarli e i messaggini di testo diventassero un fenomeno di massa.
Oggi sembra quasi assurdo, ma all’epoca gli SMS si pagavano e spesso non era possibile mandarli a un numero estero o a quello di un altro operatore telefonico. Dopo un picco di utilizzo intorno al 2000, gli SMS sono stati in buona parte soppiantati e resi obsoleti dai messaggi gratuiti e molto meno limitati dei social network e dall’arrivo degli smartphone, ma ne vengono ancora inviati miliardi ogni mese nel mondo: non dagli esseri umani, ma dalle macchine.
Moltissimi servizi online, infatti, oggi usano gli SMS per inviare agli utenti i codici temporanei di accesso ai loro servizi, per verificare le identità dei loro clienti, per notificare allarmi meteo o relativi al traffico, per validare gli acquisti e, purtroppo, anche per inviare pubblicità indesiderata.
Sono uno dei cardini dell‘autenticazione a due fattori, quella raccomandata dagli esperti di sicurezza per proteggere gli account di posta o social dai furti, perché viaggiano su un canale separato rispetto alla richiesta di password tradizionale. La password viene trasmessa via Internet, mentre il codice supplementare di sicurezza mandato in un SMS viaggia attraverso la rete telefonica tradizionale, e quindi un aspirante intruso o ladro di account dovrebbe riuscire a intercettare sia il traffico Internet del bersaglio, sia il suo traffico telefonico.
Ma un’indagine pubblicata pochi giorni da un gruppo di giornalisti chiamato Lighthouse Reports in collaborazione con Bloomberg Businessweek [paywall] ha rivelato il ventre molle di questo venerabile servizio di messaggistica.
Quando un negozio online, una banca, un servizio di mail come Gmail o una piattaforma social come Instagram o Bluesky ci manda un SMS con i codici temporanei di autenticazione, in realtà non lo invia quasi mai direttamente a noi, come verrebbe spontaneo immaginare. Per contenere al massimo i costi, lo invia quasi sempre tramite società terze specializzate, degli intermediari, che a loro volta lo passano ad altri, fino a che finalmente arriva sul nostro schermo. Questo rimpallo è estremamente rapido, per cui non ce ne accorgiamo. Ma gli SMS vengono trasmessi in chiaro, ossia senza crittografia, e quindi ognuno di quegli intermediari può leggerne il contenuto senza che il mittente o il destinatario se ne possano accorgere.
E il contenuto di quegli SMS spesso include tutto quello che serve per rubare un account, perché assieme ai codici vengono inviati il numero di telefono del destinatario, per ovvie ragioni, e a volte anche il nome dell’account al quale si riferiscono. I codici segreti di autenticazione, insomma, non sono affatto segreti.
Se ne sono accorti l’anno scorso i giornalisti di Lighthouse Reports, appunto, quando hanno ricevuto da un addetto ai lavori, sotto anonimato e protezione giornalistica, un immenso archivio di SMS trafugati, che includevano circa un milione di messaggi contenenti codici di autenticazione a due fattori inviati intorno a giugno del 2023. Stando alle loro indagini, questi messaggi erano stati veicolati da una piccola società di telecomunicazioni svizzera, la Fink Telecom Services, che ha meno di dieci dipendenti. I mittenti erano Google, Meta, Amazon, banche europee, app come Tinder e Snapchat, servizi di scambi di criptovalute come Binance e persino servizi di messaggistica crittografata come Signal e WhatsApp. I destinatari, nota Bloomberg, erano situati in oltre 100 paesi in cinque continenti.
In altre parole, i nostri codici di sicurezza passano quasi sicuramente attraverso intermediari che non abbiamo mai sentito nominare.
Il problema è che questo settore è scarsamente regolamentato, ed è facilissimo diventare intermediari di miliardi di messaggi privati. In particolare, la Fink Telecom Services è nota agli esperti del settore per aver collaborato con agenzie di sorveglianza governative e con società specializzate nella sorveglianza digitale. Sempre Bloomberg sottolinea che “sia i ricercatori di sicurezza informatica, sia i giornalisti investigativi hanno pubblicato rapporti che accusano la Fink di essere coinvolta in vari casi di infiltrazione in account online privati.” Il CEO dell’azienda, Andreas Fink, respinge le accuse.
Le aziende che usano gli SMS per autenticare i propri servizi sono così ansiose di contenere i costi che si appoggiano a lunghe e intricate catene di intermediari non verificati, anche se sanno che questo è un comportamento pericoloso. Una delle principali organizzazioni di settore, il GSMA, ha pubblicato nel 2023 un codice di condotta che sconsiglia questa prassi proprio perché permetterebbe ai criminali di intercettare gli SMS contenenti i codici di sicurezza. Ma si tratta di un codice di condotta volontario, e sembra proprio che manchi la volontà diffusa di applicarlo.
Il rischio che deriva da questa carenza di volontà è tutt’altro che teorico. Nel 2020, per esempio, è emerso che una serie di attacchi informatici ai danni di investitori in criptovalute aveva usato proprio questa tecnica: un criminale informatico aveva ottenuto in questo modo i codici di autenticazione necessari per accedere agli account di mail e a quelli di gestione delle criptovalute di una ventina di persone in Israele. E ci sono altri casi documentati di intercettazioni e sorveglianze governative basate su questo approccio.
Purtroppo l’industria della trasmissione degli SMS, che si stima abbia un valore di oltre 30 miliardi di dollari, non ha strumenti legali che le consentano di scremare eventuali intermediari disonesti. I grandi utenti, ossia le aziende, appaltano gli invii dei loro codici di autenticazione a uno di questi intermediari e non hanno modo di sapere se questi invii vengono subappaltati e se quel subappaltatore a sua volta cede il contratto a terzi, e così via, in un complicato gioco internazionale di scatole cinesi e di società che spesso non hanno nemmeno bisogno di una licenza per operare.
E i nostri codici di sicurezza viaggiano così in questo mare burrascoso come messaggi in bottiglia che tutti possono leggere, mentre noi crediamo di aver protetto i nostri account attivando gli SMS di autenticazione.
Per fortuna ci sono delle soluzioni.
Di fronte a questa situazione caotica e insicura degli SMS tradizionali, gli esperti di sicurezza raccomandano alternative più robuste. In molti casi si possono attivare dei PIN supplementari sui propri account, e molti grandi nomi dei servizi online, come Google o Meta, offrono soluzioni di autenticazione che fanno a meno degli SMS e anzi stanno incoraggiando gli utenti ad abbandonare la ricezione di codici tramite messaggi telefonici tradizionali.
Una delle soluzioni più efficaci è l’uso di una app di autenticazione, come quelle di Google [Android; iOS] e Microsoft [Android; iOS], che si chiamano entrambe Authenticator, oppure Authy di Twilio. Per usarla, si entra nel proprio account del servizio che si vuole proteggere e lo si imposta in modo che non mandi un SMS con dei codici di verifica ma richieda un codice generato dall’app di autenticazione. Quel codice dura un minuto e poi viene cambiato automaticamente, e la sincronizzazione fra l’app e il sito si fa semplicemente inquadrando una volta con il telefono un codice QR.
Un altro metodo è l’uso di chiavi di sicurezza hardware: degli oggetti fisici, simili a chiavette USB, che si inseriscono nel computer, tablet o telefonino oppure si tengono vicini a uno di questi dispositivi per autorizzarlo ad accedere a un servizio online. Costano qualche decina di euro o franchi e diventano una sorta di portachiavi elettronico.
Queste soluzioni offrono maggiore sicurezza rispetto alla situazione colabrodo attuale degli SMS, ma in cambio richiedono un po’ di attenzione in più da parte dell’utente e, nel caso della chiave hardware comportano anche una piccola spesa.
Hanno anche un altro limite: accentrano tutti i codici in un’unica app o un unico dispositivo, per cui se si perde o rompe il telefonino o la chiave hardware si rischia di perdere accesso a tutti i propri account, mentre gli SMS invece arrivano sempre e comunque e sono separati per ogni account. Ma anche qui ci sono dei rimedi: si possono avere copie multiple dell’app di autenticazione su telefonini differenti o su più di una chiave hardware, un po’ come si fa con le chiavi della porta di casa, di cui è prassi normale avere almeno un paio di esemplari.
Se avete in casa un vecchio smartphone che non usate più perché la batteria non regge, potete recuperarlo facendolo diventare il vostro autenticatore di scorta, da lasciare a casa al sicuro in un cassetto e da usare in caso di furto o guasto dello smartphone principale.
Le soluzioni, insomma, ci sono. Ma resta la constatazione amara che le società più ricche del pianeta, come Google, Amazon o Meta, non sono disposte a spendere per garantire meglio la sicurezza dei propri utenti e continuano ad appoggiarsi a questa ingarbugliata rete di intermediari e sottointermediari invece di prendere il toro per le corna e mandare gli SMS di autenticazione direttamente. Tanto se perdiamo accesso ai nostri dati sui loro server, se ci saccheggiano il conto PayPal o Twint o quello in criptovalute, se perdiamo il controllo dei nostri profili social o qualcuno si legge tutta la nostra mail, il problema è nostro, non loro. E quindi, cinicamente, a queste grandi aziende conviene barattare la nostra sicurezza in cambio di un loro risparmio.
È dunque il caso di rimboccarsi le maniche virtuali e abbandonare gli SMS, pensando in prima persona alla propria protezione digitale, senza aspettare che lo faccia qualcuno per noi.
È andata in onda lunedì scorso l’ultima puntata prima della pausa estiva di Niente Panico, il programma che conduco in diretta insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embed qui sotto.
L’articolo sulle ipotesi di allineamento delle piramidi egizie che cito è stato pubblicato su Astronomy nel 2021. Le tecniche di posa dei sarcofagi di Saqqara sono tratte da questo articolo di Wikipedia.
La vicenda della funicolare di Lugano che secondo Google Gemini dovrebbe chiudere nel 2027 (non è vero) mi è stata segnalata da un lettore, Mauro, che ringrazio. A lui devo questi screenshot. Non fidatevi di quello che dicono queste pseudointelligenze. Con tutti i miliardi che hanno speso Google, Microsoft, Meta e compagnia bella, non sono ancora capaci di distinguere la satira e i pesci d’aprile dalla realtà.
Sì, certo, c’è scritto “Le risposte dell’AI potrebbero contenere errori”. Ma allora cosa le consultiamo a fare? Sono solo una costosa, energivora perdita di tempo.
Questo è il testo della puntata del 16 giugno 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: voce sintetica legge il testo di una domanda: “quale crema o unguento si può usare per lenire una grave reazione con lesioni allo scroto causate dal rasoio usato per depilarsi?”]
Se siete fra gli utenti delle app di Meta, come Facebook, Instagram o WhatsApp, fate attenzione alle domande che rivolgete a Meta AI, l’assistente basato sull’intelligenza artificiale integrato da qualche tempo in queste app e simboleggiato dall’onnipresente cerchietto blu. Moltissimi utenti, infatti, non si rendono conto che le richieste fatte a Meta AI non sempre sono private. Anzi, può capitare che vengano addirittura pubblicate online e rese leggibili a chiunque. Come quella che avete appena sentito.
E sta capitando a molti. Tanta gente sta usando quest’intelligenza artificiale di Meta per chiedere cose estremamente personali e le sta affidando indirizzi, situazioni mediche, atti legali e altro ancora, senza rendersi conto che sta pubblicando tutto quanto, con conseguenze disastrose per la privacy e la protezione dei dati personali: non solo i propri, ma anche quelli degli altri.
Questa è la storia di Meta AI, di come mai i dati personali degli utenti finiscono per essere pubblicati da quest’app e di come evitare che tutto questo accada.
Benvenuti alla puntata del 16 giugno 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Meta AI è un servizio online basato sull’intelligenza artificiale che è stato presentato pochi mesi fa ed è accessibile tramite un’app omonima e tramite Facebook, Instagram e WhatsApp: è rappresentato da quel cerchietto blu che è comparso, non invitato, in tutte queste app. È simile a ChatGPT, nel senso che gli utenti possono fargli domande scritte o a voce e ottenerne risposte altrettanto scritte o vocali, possono mandargli immagini per farle analizzare, e possono chiedergli anche di creare immagini in base a una descrizione.
Meta AI, però, ha una differenza importantissima rispetto a ChatGPT, Google Gemini e gli altri prodotti analoghi: ha un’opzione che permette che le domande che gli vengono rivolte possano essere pubblicate online, dove chiunque può leggerle. E a giudicare dalle cose che si possono vedere nel flusso pubblico di queste domande e risposte, è evidente che moltissimi utenti non sono affatto consapevoli di questa differenza e stanno rendendo pubbliche richieste molto private e spesso spettacolarmente imbarazzanti.
Nell’app e nel sito di Meta AI (https://www.meta.ai/#feed) c’è infatti una sezione, chiamata formalmente Discover, dove chiunque può sfogliare le domande poste dagli utenti a questa intelligenza artificiale e vedere chi le ha fatte: ogni domanda è infatti associata all’account di chi l’ha inviata.
Esplorando il contenuto di questa sezione si trova davvero di tutto: richieste di generare immagini di donne che si baciano mentre lottano nel fango in bikini, o di produrre le soluzioni a un compito o a un esame, per esempio, ma anche richieste di fare diagnosi mediche, accompagnate da descrizioni dettagliate dei sintomi, oppure di comporre una lettera di risposta a uno studio legale, con tanto di nomi, cognomi e indirizzi delle persone coinvolte.
Molte testate giornalistiche [CNBC; BBC; Fastcompany; Wired; Business Insider] e vari esperti di sicurezza informatica e privacy digitale, come per esempio Rachel Tobac, hanno catalogato e documentato davvero di tutto: dettagli di casi clinici e procedimenti legali, richieste di pareri riguardanti evasioni fiscali, informazioni sui reati personalmente commessi, domande appunto su come rimediare a irritazioni prodotte dalla rasatura delle parti intime o come affrontare una transizione di genere, richieste di aiuto su come trovare donne (cito) “con un sedere grosso e un bel davanzale”, e altro ancora, sotto forma di richieste scritte o vocali, leggibili o ascoltabili da chiunque e condivisibili con il mondo, perché ciascuna richiesta ha un link pubblico.
Uno dei casi più incredibili è la richiesta pubblica a Meta AI di “creare una lettera che implori il giudice (identificato dal cognome) di non condannarmi a morte per l’omicidio di due persone”.
E tutto questo, ripeto, è associato ai nomi degli account dei richiedenti, che molto spesso sono i loro nomi e cognomi anagrafici, per cui risalire alle loro identità è facilissimo.
Se avete già usato Meta AI e adesso siete nel panico perché state ripensando alle cose potenzialmente imbarazzanti o private che avete chiesto a questo servizio, aspettate un momento. Ci sono alcuni dettagli importanti da conoscere.
Prima di tutto, il problema di questo torrente di domande rivolte dagli utenti a Meta AI e rese pubbliche riguarda soltanto i paesi nei quali Meta AI è pienamente attivo. In gran parte dell’Europa, per esempio, il flusso pubblico di domande non è accessibile, grazie alle norme sulla protezione dei dati personali che servono proprio a impedire disastri come questo.
Per consultarlo, o per finire inavvertitamente per farne parte, è necessario risiedere in uno dei numerosi paesi, come gli Stati Uniti, nei quali Meta AI opera senza restrizioni, e occorre avere un account Meta legato a quel paese. Per esempio, per poter vedere con i miei occhi questo impressionante flusso di domande pubblicate ho dovuto usare una VPN per simulare di essere negli Stati Uniti. E il mio account Meta di test, associato alla Svizzera, mi dice che le funzioni dell’app Meta AI non sono ancora disponibili nella mia area geografica.
In altre parole, se abitate in Europa questo problema probabilmente non vi riguarda, almeno per ora. Ma le cose possono cambiare, e se vivete fuori dall’Europa o avete amici, colleghi o parenti che non risiedono in questo continente è consigliabile avvisarli di questa potenziale fuga di dati personali estremamente sensibili.
In secondo luogo, per rendere pubblica una domanda rivolta a Meta AI è necessario cliccare su un pulsante di condivisione e poi su un ulteriore pulsante di pubblicazione, ed è indicato piuttosto chiaramente quello che succederà, con un avviso dettagliato che dice specificamente che se si condivide il prompt, ossia la domanda, le altre persone potranno vedere per intero la conversazione fatta con Meta AI e raccomanda di “evitare di condividere informazioni personali o sensibili”.
Ma se ci sono tutte queste avvertenze, come è possibile che gli utenti di Meta AI finiscano lo stesso per pubblicare le proprie domande imbarazzanti e le proprie informazioni personali? È vero che le persone usano queste app in maniera molto distratta e superficiale, e spesso non hanno ben chiaro cosa significhi esattamente “condividere” o “prompt” nel mondo dei social, ma dare la colpa esclusivamente agli utenti disattenti e impreparati sarebbe scorretto.
La già citata esperta Rachel Tobac spiega infatti che gli utenti comuni si sono fatti ormai uno schema mentale di come funzionano i chatbot basati sull’intelligenza artificiale e non si aspettano nemmeno lontanamente che le loro richieste possano essere pubblicate, perché le altre app dello stesso genere non lo fanno. Si aspettano che le loro domande siano sempre e comunque private; magari condivise con il fornitore del servizio, ma non con il mondo intero. Non si aspettano che esista addirittura una pagina pubblica del sito di Meta dove le loro domande possono essere pubblicate per errore.
Non solo: se si chiede a Meta AI se le domande che gli si rivolgono sono pubbliche o no, l’intelligenza artificiale mente senza esitazione, dicendo con tono risoluto che no, le conversazioni sono private e nessun altro le può vedere [Rachel Tobac]. Per cui è comprensibile che gli utenti siano confusi e disorientati.
I responsabili di Meta hanno insomma commesso un errore grave e fondamentale nella progettazione della propria interfaccia con gli utenti. Sanno benissimo che fra i loro quattro miliardi di utenti stimati nel mondo ci sono tante persone che hanno un rapporto molto superficiale con l’informatica, eppure non ne hanno tenuto conto e hanno pensato che fosse una buona idea offrire l’opzione di pubblicare le proprie domande, senza considerare le possibili conseguenze. E soprattutto hanno pensato che fosse sensato permettere a chiunque di leggere le conversazioni condivise inavvertitamente dagli altri, creando un disastro di privacy ampiamente prevedibile.
Come nota TechCrunch, infatti, ci sono dei precedenti molto educativi: questo sito dedicato alle tecnologie dice che “c’è un motivo per cui Google non ha mai tentato di trasformare il proprio motore di ricerca in un flusso social, o per cui la pubblicazione delle ricerche degli utenti di America Online in forma pseudo-anonimizzata nel 2006 è finita così male” [New York Times, 2006].E come nota invece Gizmodo, Facebook anni fa rilasciò una versione nella quale la casella di ricerca somigliava alla casella di scrittura dei post, per cui gli utenti finivano per postare pubblicamente le loro ricerche, e nel 2023 l’app di pagamento Venmo aveva avuto l’idea geniale di rendere pubblicamente cercabili i dettagli delle transazioni degli utenti, con conseguenze ovvie e disastrose [Daily Dot].
C’è anche un secondo errore commesso dai progettisti di Meta, ed è la scelta di impostare questo servizio di dubbia utilità in modo che spetti all’utente agire per tutelare la propria privacy, invece di progettarlo in modo tale che l’utente debba fare qualcosa di concreto per perderla. È il concetto di privacy by default: la riservatezza deve essere l’impostazione predefinita.
Vediamo allora a questo punto cosa si può fare per rimediare a queste scelte di Meta.
Se avete installato l’app Meta AI e vi funziona pienamente, potete ridurre il rischio di postare inconsapevolmente le vostre domande personali andando nell’app e toccando l’icona del vostro profilo in alto a destra.
Fatto questo, scegliete le impostazioni dell’app e la sezione dedicata a dati e privacy, andate nella sottosezione dedicata alla gestione delle informazioni personali e toccate l’opzione che parla di rendere visibili solo a voi tutti i vostri prompt e di condividere quei prompt con altre app, disattivando tutto. Già che ci siete, vi conviene anche toccare e attivare l’opzione che permette di cancellare tutti i prompt precedenti, per fare tabula rasa [Gizmodo]. Se vi siete persi qualche passaggio, non vi preoccupate: le istruzioni dettagliate sono disponibili presso Attivissimo.me.
Questa vicenda, al di là dei suoi risvolti umani a metà fra il voyeuristico e il deprimente, dimostra ancora una volta che nonostante gli infiniti proclami di avere a cuore la nostra privacy, in realtà ai gestori dei social network la protezione dei dati degli utenti non interessa affatto. Tengono invece al profitto, e devono in qualche modo giustificare le cifre spropositate che stanno spendendo per stare al passo con questa febbre dell’intelligenza artificiale, per cui non ci chiedono se per caso vogliamo la IA in tutte le nostre app, ma ce la impongono a forza.
Se avessero davvero a cuore la nostra riservatezza, imposterebbero i loro servizi in modo che debba essere l’utente ad abbassare volontariamente le proprie protezioni. E invece tocca a noi utenti informarci e stare vigili a ogni aggiornamento delle nostre app social per tenere alzate quelle protezioni. È estenuante, e forse l’unico rimedio per non cedere allo sfinimento prima o poi è semplicemente smettere di usare questi prodotti e passare ad alternative progettate meglio e a favore degli utenti e non degli azionisti.
Sì, esistono. Ma questa è un’altra storia per un’altra puntata di questo podcast.
Questo è il testo della puntata del 9 giugno 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Un’azienda informatica operante nel settore dell’intelligenza artificiale applicata alla programmazione e valutata un miliardo e mezzo di dollari è crollata sotto gli occhi dei suoi investitori, fra i quali spicca Microsoft, perché è emerso che il suo prodotto basato sulla IA era molto I ma poco A: la sua strombazzata “intelligenza artificiale”, infatti, era in realtà quasi interamente costituita da 700 informatici residenti in India, pagati da 8 a 15 dollari l’ora per fingere di essere un software.
Questa è la storia di Builder.ai, che probabilmente è il più grosso flop di questo periodo di delirio di investimenti su qualunque cosa legata all’intelligenza artificiale, ma non è l’unico: è stato stimato che il 40% delle startup che hanno annunciato di avere un prodotto basato sull’intelligenza artificiale in realtà non usano affatto questa tecnologia ma simulano di averla per attirare più capitali. E finalmente comincia a serpeggiare una domanda: quanto di questo boom estenuante dell’intelligenza artificiale è solo marketing o addirittura sconfina nella truffa?
Benvenuti alla puntata del 9 giugno 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Builder.ai era una delle grandi speranze legate all’intelligenza artificiale nel Regno Unito. La startup londinese aveva raccolto 450 milioni di dollari di finanziamenti in capitale di rischio, principalmente da Microsoft e dal fondo sovrano di investimento del Qatar, uno dei più grandi del mondo. Il suo prodotto era Natasha, un’intelligenza artificiale che a suo dire permetteva ai clienti di creare app o addirittura interi siti di commercio elettronico semplicemente conversando con lei, senza aver bisogno di sapere nulla di programmazione. Nel 2023, quando Microsoft aveva investito in Builder.ai, uno dei vicepresidenti dello storico colosso del software, Jon Tinter, aveva detto che Builder.ai stava “creando una categoria completamente nuova che dà a tutti il potere di diventare sviluppatori” [GlobeNewsWire, 2023], e Microsoft aveva intenzione di integrare Natasha nel suo onnipresente Teams.
Ma il mese scorso Builder.ai ha presentato istanza di fallimento negli Stati Uniti, con debiti stimati fra i 50 e i 100 milioni di dollari [Courtlistener; Courtlistener], perché le indagini giornalistiche e quelle degli investitori hanno rivelato pratiche di contabilità estremamente sospette e perché è emerso che Natasha non esisteva: era solo una facciata di marketing, per nascondere il fatto poco vendibile che la sua cosiddetta intelligenza artificiale era in realtà costituita da un gruppo di 700 analisti, sviluppatori e programmatori residenti a Delhi, in India, addestrati a fingere di essere una IA, tanto che i dipendenti dicevano scherzosamente che “AI”, l’acronimo inglese che indica l’intelligenza artificiale, stava in realtà per “Another Indian”, ossia “un altro indiano”. I tecnici di Builder.ai si autodefinivano “un call center, ma con un marketing migliore”. Natasha si prendeva il merito e i clienti credevano di interagire con una straordinaria intelligenza artificiale capace di sviluppare app meglio degli esseri umani.
E le cose andavano avanti così da anni, fin dal 2016, quando l’azienda si chiamava Engineering.ai, e sono andate avanti nonostante il fatto che già nel 2019, quindi sei anni fa, le indagini del Wall Street Journal avevano fatto emergere il fatto che la sedicente IA dell’azienda era in realtà la maschera che copriva i volti di sviluppatori in carne e ossa [The Verge; WSJ], anche se il CEO di allora, Sachin Duggal, andava in giro a dire pubblicamente che il lavoro di sviluppo delle app era svolto per più dell’80% dall’intelligenza artificiale [Builder.ai su Facebook, video del 2018].
Sempre nel 2019, il responsabile commerciale di Engineering.ai, Robert Holdheim, aveva fatto causa all’azienda accusandola di esagerare le proprie capacità di intelligenza artificiale per ottenere gli investimenti che le servivano per sviluppare realmente la tecnologia che diceva di avere già [The Verge]. Ma ci sono voluti quasi nove anni perché i nodi arrivassero al pettine, e nel frattempo Builder.ai si è lasciata dietro una scia di investitori prestigiosi che ora si rendono conto di essere stati beffati.
La febbre dell’intelligenza artificiale arde ormai da parecchi anni, e molti investitori si lasciano sedurre dal marketing invece di analizzare la sostanza delle aziende che finanziano. E il caso di Builder.ai non è isolato. Secondo un’analisi della società di investimenti britannica MMC Ventures datata 2019, “le startup che hanno qualche sorta di componente IA possono attirare fino al 50% in più di investimenti rispetto alle altre società di software” ma “si sospetta che il 40% o più di queste startup non usi in realtà nessuna forma di intelligenza artificiale” [The Verge].
Per esempio, ad aprile 2025 è emerso che l’app di shopping Nate, che affermava di permettere agli utenti di completare gli acquisti nei negozi online facendo un solo clic grazie all’intelligenza artificiale, in realtà sfruttava centinaia di lavoratori nelle Filippine, che non facevano altro che completare a mano gli acquisti iniziati dai clienti. Secondo il Dipartimento di Giustizia statunitense, che ha incriminato l’ex CEO dell’azienda che gestiva questa app, il tasso effettivo di automazione di questa app era zero e il CEO ha nascosto intenzionalmente questo fatto agli investitori, dai quali è riuscito a farsi dare oltre 40 milioni di dollari.
Un altro esempio: nel 2023 la Presto Automation, società che offriva un popolare software per automatizzare gli ordini e gli acquisti nelle più importanti catene di fast food, ha ammesso che oltre il 70% degli ordini che a suo dire venivano gestiti dall’intelligenza artificiale erano in realtà presi in carico da lavoratori anche stavolta nelle Filippine [The Verge; Bloomberg]. La società è finita sotto indagine da parte delle autorità statunitensi di vigilanza sui mercati.
Nel 2016 Bloomberg ha segnalato il caso delle persone che lavoravano per dodici ore al giorno fingendo di essere dei chatbot per i servizi di gestione delle agende, come per esempio X.ai e Clara. Nel 2017 è emerso che i gestori di Expensify, una app che dichiarava di usare una “tecnologia di scansione smart” per leggere e digitalizzare ricevute e scontrini, in realtà sfruttava dei lavoratori umani sottopagati, che ovviamente venivano a conoscenza di tutti i dati personali dei clienti. E si potrebbe citare anche Facebook, il cui assistente virtuale per Messenger, denominato M, dal 2015 al 2018 si è appoggiato in realtà a esseri umani per oltre il 70% delle richieste [The Guardian].
In altre parole, l’intelligenza artificiale viene spesso usata come luccicante foglia di fico per coprire il fatto che si vuole semplicemente sfruttare una manodopera più a buon mercato di quella locale.
Non è che quelli che operano nel settore dell’intelligenza artificiale siano tutti truffatori o venditori di fumo: in parte il fenomeno delle IA fittizie è dovuto al fatto che spesso l’intelligenza artificiale sembra funzionare bene durante la fase di test ma fallisce quando viene esposta alle complessità del mondo reale e viene usata su vasta scala. Inoltre procurarsi i dati necessari per l’addestramento di una IA dedicata è molto costoso e richiede molto tempo.
C’è anche il fatto che l’intelligenza artificiale attuale ha ancora molto bisogno di intervento umano, e oltretutto di intervento umano qualificato, che costa, e quindi le promesse di riduzione dei costi spesso si rivelano vane. Per esempio, i social network, nonostante spingano insistentemente per l’adozione di massa delle intelligenze artificiali, non riescono ancora a usarle per moderare automaticamente i contenuti pubblicati dagli utenti e sono tuttora costretti a subappaltare questo compito a esseri umani, anche in questo caso sottopagati, ma siccome ammettere questa situazione non è cool e non fa bene alla quotazione in borsa, si continua a far finta di niente e si cerca di far sembrare che questa tecnologia sia più sofisticata di quanto lo sia realmente.
A questo miraggio della IA come tecnologia magica e affidabile credono in molti, compresi i professionisti di vari settori. Nella puntata precedente di questo podcast ho raccontato alcuni incidenti molto costosi e imbarazzanti che hanno coinvolto per esempio gli avvocati di vari paesi, che si sono affidati alle intelligenze artificiali per preparare le loro cause senza rendersi conto che questi software non sono fonti attendibili perché per natura tendono a inventarsi le risposte ai quesiti degli utenti. Dal Regno Unito arriva un aggiornamento che mostra quanto sia diventato grave e diffuso questo uso scorretto.
L’Alta corte di giustizia dell’Inghilterra e del Galles, un tribunale superiore che vigila sulle corti e i tribunali ordinari, ha rilasciato la settimana scorsa un documento indirizzato a tutti gli operatori di giustizia di sua competenza che è in sostanza una solenne lavata di capo a chi, per professione, dovrebbe sapere benissimo che non si va in tribunale portando fonti cercate rivolgendosi a ChatGPT, Gemini e simili senza verificarle.
Erano già state emanate delle direttive che mettevano in guardia contro i rischi di perdite di tempo e di equivoci derivati dall’uso improprio dell’intelligenza artificiale in campo legale, ma dopo un caso nel quale una causa di risarcimento per danni finanziari ammontanti a ben 89 milioni di sterline (circa 105 milioni di euro) è stata presentata fornendo al tribunale 45 precedenti inesistenti e fabbricati da un’intelligenza artificiale generativa, l’Alta corte ha deciso che a questo punto “è necessario prendere misure pratiche ed efficaci” contro questo fenomeno, come l’ammonimento pubblico dell’avvocato coinvolto, l’imposizione di una sanzione per i costi inutili causati, l’annullamento dell’azione legale e, nei casi più gravi, il processo per oltraggio alla corte o la segnalazione alla polizia [Pivot to AI].
L’aspetto forse più sorprendente, in tutte queste vicende legate all’intelligenza artificiale, è che non sono coinvolte persone qualsiasi, ma professionisti altamente qualificati, sia in campo legale sia in campo finanziario. Tutta gente che teoricamente dovrebbe sapere che prima di investire il proprio denaro (o quello degli altri) bisogna informarsi seriamente e indipendentemente sulla solidità della proposta, senza fidarsi delle patinate presentazioni aziendali, e che altrettanto teoricamente dovrebbe sapere che per fare le ricerche di precedenti legali non si va su Google e si prende per buono qualunque cosa risponda, ma si usano i servizi di ricerca professionali appositi. E invece ci cascano, e continuano a cascarci.
I catastrofisti dell’intelligenza artificiale dipingono spesso scenari inquietanti nei quali le macchine prima o poi acquisiranno un intelletto superiore a quello umano e quindi prenderanno il controllo di tutto. Ma forse non c’è bisogno di far leva sulla superiorità intellettiva. È sufficiente giocare sulla nostra tendenza a credere non a quello che è vero, ma a quello che vorremmo che fosse vero.
Gli investitori superpagati vogliono credere che investire nell’IA li farà diventare ancora più ricchi, e gli avvocati vogliono credere di poter delegare il loro lavoro a un software ottuso e incassare laute parcelle facendo meno fatica. E così l’intelligenza artificiale generativa dei grandi modelli linguistici come ChatGPT, Claude o Gemini, con la sua parlantina scioltissima e le sue risposte apparentemente così autorevoli, diventa l’imbonitore perfetto per rifilare fregature.
Credo che il video qui sotto sia stato realizzato con Google Veo 3, che costa 250 dollari al mese: una cifra abbordabilissima per qualunque truffatore. Inquietante.
Questo, invece, è sicuramente fatto con Veo 3. Ottima l’idea di usare l’IA per mettere in guardia contro i rischi di inganno dell’IA stessa. Il video è disponibile anche su Instagram ed è opera di @thetravisbible.
Questo è il testo della puntata del 2 giugno 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
A giugno 2023, esattamente due anni fa, i nomi degli avvocati statunitensi Peter LoDuca e Steven Schwartz avevano fatto il giro del mondo perché LoDuca, per difendere il suo assistito, aveva depositato in tribunale una lunga serie di precedenti legali che però erano stati inventati di sana pianta da ChatGPT, usato dal collega Schwartz credendo che fosse una fonte attendibile e addirittura chiedendo a ChatGPT di autenticare i precedenti che aveva appena inventato. Nel suo ormai classico stile, ChatGPT aveva risposto che era tutto in ordine.
Il giudice li aveva puniti con un’ammenda di alcune migliaia di dollari, ma la punizione più grave era stata la figuraccia mediatica. Chiunque cercasse i nomi di questi avvocati in Google li trovava associati da moltissimi giornali, e anche da questo podcast, alla loro dimostrazione di travolgente inettitudine [Disinformatico; Disinformatico].
Potreste pensare che dopo un caso clamoroso del genere gli avvocati in generale abbiano imparato la lezione e che simili disastri non si siano più ripetuti, ma non è così. Anzi, anche dal mondo del giornalismo e persino dai governi arrivano esempi di preoccupante incapacità di usare correttamente l’intelligenza artificiale.
Questa è la storia di una serie di esempi di uso inetto e incompetente della IA generativa da parte di professionisti e politici che sembrano incapaci di imparare dagli errori altrui e continuano, a volte con leggerezza preoccupante e spesso con arroganza sconcertante, a partorire deliri e vaneggiamenti dai quali purtroppo dipendono le sorti e la salute di tutti noi.
Sono esempi da raccontare non per umiliare o sbeffeggiare, ma per ribadire e diffondere il più possibile un concetto fondamentale che a quanto pare fa veramente fatica a essere acquisito: le intelligenze artificiali attuali non sono fonti affidabili e non ci si può fidare ciecamente dei loro risultati, ma bisogna sempre controllarli accuratamente. Altrimenti, prima o poi, la figuraccia è garantita.
Benvenuti alla puntata del 2 giugno 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Il 18 maggio scorso vari quotidiani statunitensi, comprese testate di prestigio come il Chicago Sun-Times e il Philadelphia Inquirer, hanno pubblicato una pagina di suggerimenti letterari per l’estate: un elenco di titoli di libri di autori molto celebri, accompagnato da una dettagliata recensione di ciascuno dei quindici libri proposti. Titoli come I creatori della pioggia, del premio Pulitzer Percival Everett, o I sogni dell’acqua di marea di Isabel Allende. Titoli che anche se siete appassionati di letteratura non vi suoneranno per nulla familiari, per la semplice ragione che non esistono.
Dei quindici titoli consigliati da questi giornali, solo cinque sono reali: gli altri dieci sono inesistenti, e la loro recensione è quindi ovviamente del tutto fasulla. L’inserto letterario di questi quotidiani è stato generato usando l’intelligenza artificiale: lo ha ammesso il suo autore, Marco Buscaglia, in seguito alle proteste dei lettori paganti di quei giornali.
Figuraccia per le testate coinvolte, che rischiano una grave perdita di fiducia e di credibilità lasciando che venga pubblicato del contenuto generato da IA senza alcuna supervisione o verifica, ma figuraccia anche per la società che ha fornito ai giornali quel contenuto, la King Features, che è una consociata del colosso dell’editoria statunitense Hearst.
Andando a leggere le scuse e gli atti di contrizione di tutte le parti coinvolte emerge una classica catena di errori: tutti hanno dato per scontato che l’elenco dei libri fosse stato verificato da qualcun altro lungo la filiera di produzione, e alla fine nessuno ha verificato nulla e i deliri dell’intelligenza artificiale, dall’aria superficialmente così plausibile, mimetizzati in mezzo a informazioni corrette, hanno raggiunto indisturbati le rotative. Buscaglia, fra l’altro, ha dichiarato che usava abitualmente l’intelligenza artificiale per le ricerche di base e controllava sempre i risultati che otteneva, ma questa volta non lo aveva fatto. La sua fiducia nell’intelligenza artificiale gli è costata il posto di lavoro [404 Media; Ars Technica; NPR; 404 Media].
Purtroppo questo non è l’unico caso del suo genere. Il giornalismo, cioè il mestiere che dovrebbe farci da baluardo contro la disinformazione, sta invece adottando disinvoltamente uno strumento che genera disinformazione. E in molti casi lo sta adottando in maniera totalmente dilettantesca: per esempio, il giornalista Aaron Pelczar si è dimesso dal giornale del Wyoming dove lavorava, il Cody Enterprise, perché ha usato ripetutamente l’intelligenza artificiale per generare articoli che contenevano virgolettati inventati e attribuiti al governatore locale, che non l’ha presa bene.
Il giornalista è stato colto sul fatto perché in fondo a uno dei suoi articoli ha lasciato la frase “Questa struttura garantisce che vengano presentate per prime le informazioni più critiche, facilitando ai lettori la comprensione più rapida dei punti salienti”, che non c’entrava nulla con il tema trattato ma era chiaramente presa di peso dalla risposta di una IA alla richiesta di strutturare e generare un articolo. Articolo che Pelczar non si era nemmeno degnato di rileggere prima di consegnarlo [The Guardian; Powell Tribune].
Foto del paragrafo finale dell’articolo di Pelczar, che contiene la frase generata da ChatGPT.
Già nel 2023 la celebre rivista Sports Illustrated era stata colta a pubblicare non solo articoli generati completamente dall’intelligenza artificiale ma anche ad attribuirli a giornalisti inesistenti, i cui nomi e le cui foto erano stati partoriti dalla stessa intelligenza artificiale, usata da un fornitore esterno di notizie. Episodi analoghi hanno coinvolto giornali e riviste di prestigio, come il Los Angeles Times, il Miami Herald e US Weekly, e il sito dedicato alle notizie tecnologiche CNET, smascherati tutti solo grazie alle indagini di giornalisti veri, in carne e ossa, che si erano insospettiti leggendo lo stile stentato e ripetitivo di questi falsi articoli e notando le loro frasi grammaticalmente impeccabili ma completamente prive di senso [PBS; Futurism; Washington Post; Futurism; NPR].
Quello che colpisce, in tutti questi episodi, non è tanto il fatto che delle redazioni tentino di usare la scorciatoia dell’intelligenza artificiale per ridurre i tempi e contenere i costi, ma che cerchino di farlo di nascosto e sperino di farla franca. È come se pensassero che il lettore sia stupido e quindi non si possa rendere conto che gli è stato rifilato un prodotto avariato. Ci sono molte situazioni nelle quali l’intelligenza artificiale può essere utile in una redazione, ma usarla per generare articoli in questo modo è come vendere una torta piena di segatura al posto della farina e pensare che tanto nessuno si accorgerà della differenza.
E nonostante questi precedenti, c’è sempre qualcuno che ci riprova.
A proposito di precedenti, anche gli avvocati sembrano incapaci di imparare dagli errori dei colleghi. Dopo la figuraccia, la sanzione e il clamore internazionale del caso degli avvocati LoDuca e Schwartz che nel 2023 erano stati colti appunto a depositare in tribunale dei precedenti inesistenti, generati dall’intelligenza artificiale, l’elenco dei legali che hanno pensato bene di affidarsi ciecamente alla IA per il proprio lavoro non ha fatto che allungarsi.
Addirittura è nato un sito, AI Hallucination Cases, che compila e documenta gli episodi di questo genere. Finora ne ha catalogati ben 129; e questo è solo il numero dei casi, in tutto il mondo, nei quali si è arrivati a una decisione legale che ha confermato che un avvocato ha presentato in tribunale materiale fasullo, generato da un’intelligenza artificiale. Non si tratta insomma semplicemente di casi nei quali si sospetta che sia stata usata l’IA, ma di casi nei quali un avvocato è stato colto sul fatto e sanzionato per la propria condotta.
La cosa che colpisce è che ben 20 di questi casi sono avvenuti a maggio di quest’anno: segno che l’uso inetto e maldestro dell’intelligenza artificiale nelle consulenze legali si sta espandendo, e lo sta facendo in tutto il mondo. Fra i casi raccolti da questo sito compilativo ce ne sono infatti vari avvenuti in Australia, Paesi Bassi, Regno Unito, Spagna, Canada, Sud Africa, Israele, Brasile, Irlanda e Nuova Zelanda, e ce n’è anche uno italiano, datato marzo 2025, in cui il Tribunale delle Imprese di Firenze rileva che una delle parti in lite ha appunto citato “sentenze inesistenti” che sono “il frutto della ricerca effettuata da una collaboratrice di studio mediante lo strumento dell’intelligenza artificiale ‘ChatGPT’”.
Questo catalogo di utilizzi incompetenti delle IA nei tribunali può comportare non solo una figuraccia imbarazzantissima di fronte al giudice, ma anche sanzioni pecuniarie notevoli, come in un caso britannico recentissimo, datato maggio 2025, dove l’uso dell’intelligenza artificiale per generare documenti prolissi e ripetitivi e precedenti legali inesistenti ha portato a una sanzione di centomila sterline, ossia circa 118.000 euro. Per non parlare del rischio di essere sospesi o radiati dall’ordine degli avvocati e di vedersi archiviare il caso.
Viene da chiedersi come si sentano gli assistiti di questi avvocati quando scoprono di aver pagato parcelle non trascurabili ottenendo in cambio queste dimostrazioni di incompetenza e di mancanza di professionalità. Non risulta, per ora, che qualcuno di questi assistiti abbia tentato di saldare la parcella con delle immagini di banconote generate da ChatGPT, ma la tentazione potrebbe essere forte.
Il caso più preoccupante in questa carrellata di castronerie arriva non dai giornalisti o dagli avvocati, che pure hanno un ruolo cruciale nella società, ma da un governo, che ovviamente prende decisioni che hanno effetto diretto su milioni di cittadini.
Il governo in questione è quello attuale degli Stati Uniti, dove il ministro della salute, Robert F. Kennedy Junior, ha presentato un rapporto di ben 73 pagine sulle cause delle malattie croniche nella popolazione statunitense e in particolare nei bambini, dicendo che si trattava di un rapporto scientifico redatto secondo i massimi criteri qualitativi del settore, da usare come documento fondante per la politica sanitaria dell’intero paese.
Ma l’associazione giornalistica Notus ha scoperto che alcuni degli studi scientifici citati come fonti dal rapporto non esistevano affatto e altri erano stati interpretati in modo grossolanamente errato. Alle domande dei giornalisti sulla causa di queste citazioni inesistenti o distorte, la portavoce della Casa Bianca ha risposto dicendo che si trattava di “errori di formattazione”. Ma secondo gli esperti, questo tipo di citazione inventata è invece un segno tipico dell’uso maldestro dell’intelligenza artificiale generativa e la “formattazione” non c’entra assolutamente nulla [CBS News; The Guardian; New York Magazine]. Uno degli indizi tecnici più vistosi di questo uso maldestro è il fatto che il link di alcune delle fonti citate dal rapporto contiene la sequenza di caratteri “oaicite”, che viene tipicamente aggiunta dalle IA di OpenAI alle citazioni ed è un errore ben documentato e caratteristico di ChatGPT [NBC; Reddit].
Il ministro Kennedy ha detto ripetutamente che avrebbe adottato una “trasparenza radicale” per la gestione della salute nel suo paese, eppure non ha voluto fornire dettagli su chi abbia scritto questo rapporto e su che basi lo abbia fatto. Inoltre le conclusioni del rapporto non corrispondono a quello che risulta analizzando i dati presenti nel rapporto stesso: per esempio, questo documento descrive l’obesità infantile come una “crisi sanitaria che sta peggiorando” ma allo stesso mostra un grafico che indica che il tasso di obesità negli Stati Uniti è relativamente stabile da vent’anni a questa parte [NBC].
Sarebbe davvero preoccupante scoprire che la sanità di un’intera nazione (quella che fra l’altro di fatto definisce gli standard sanitari di gran parte del mondo) viene decisa affidandosi ciecamente a ChatGPT.
La morale di fondo, alla fine di questa carrellata di disastri informatici, è che sembra che sia straordinariamente difficile sfuggire alla seduzione delle intelligenze artificiali generative, e che lo sia anche per persone altrimenti considerate professionisti intelligenti, razionali e competenti.
Eppure il concetto è semplice, e potrebbe anzi essere la base per un’idea regalo per chiunque si affacci al giornalismo o alle professioni legali: una bella targa, da affiggere nel proprio studio, con cinque semplici parole: ChatGPT non è una fonte.
Immagine generata da me usando un generatore di immagini basato su IA. Prompt: “A Victorian-style brass plaque bears the words “ChatGPT non è una fonte” etched in bas-relief into the metal, written in very elegant black Bodoni font. The plaque is screwed onto the elegant antique wood bookshelves of a very formal lawyer’s office, with antique furniture and lots of books and encyclopedias. Masterpiece, 4K, Nikon F1, underexposed, light streaming through large window from the left.”
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embed qui sotto.
La settimana prossima Niente Panico è in pausa e torna per l’ultima puntata della stagione il 16 giugno.
I temi e le fonti della puntata
Il leone marino che sa battere il ritmo meglio degli umani. Un articolo scientifico pubblicato su Scientific Reports descrive Ronan, una femmina di leone marino che ama tenere il ritmo della musica e vive presso il Long Marine Laboratory dell’Università della California, a Santa Cruz, dove i ricercatori hanno esplorato in dettaglio la sua capacità di riconoscere i ritmi anche quando sono inediti, dimostrando quindi la flessibilità di Roman nel riconoscere nuovi ritmi. I ricercatori hanno chiesto a dieci studenti universitari di fare lo stesso, muovendo l’avambraccio al ritmo dei battiti che cambiavano, e Ronan li ha superati tutti (NBC News).
Due parole sul convegno anti fake news di Como.Ho raccontato per sommi capi gli argomenti del convegno e le tecniche per difendersi da social network e disinformazione.
Anniversari: incoronazione della regina Elisabetta (1953); morte di Garibaldi (1882); Festa della Repubblica in Italia e qualche chicca sull’inno di Mameli, diventato inno nazionale italiano ufficiale solo nel 2017.
Un filo interdentale in grado di misurare lo stress. Su Science Daily di fine maggio è stato presentato un filo interdentale che preleva campioni di cortisolo dalla saliva e li usa come indicatori dello stress, che viene quantificato tramite un elettrodo integrato. La tecnologia usata permette di catturare e quantificare numerosi indicatori, come gli estrogeni per monitorare la fertilità o il glucosio per monitorare il diabete, e la facilità d’uso consente di integrare il monitoraggio in molte aree di trattamento.
Perché dopo 2000 anni non sappiamo ancora come funziona il solletico? L’articolo The extraordinary enigma of ordinary tickle behavior: Why gargalesis still puzzles neuroscience pubblicato su Science Advances esplora il mistero del solletico: perché non è possibile farselo da soli, come mai alcuni lo sopportano perfettamente mentre altri gridano di disperazione, e perché in generale siamo sensibili a questo particolare tipo di esperienza tattile, che è una complessa interazione tra aspetti motori, sociali, neurologici, evolutivi e dello sviluppo, spiega la ricercatrice Konstantina Kilteni dell’Università Radboud di Nimega, nei Paesi Bassi. La ricerca mostra anche che le persone con disturbi dello spettro autistico, ad esempio, percepiscono il tocco come più solleticante rispetto alle persone senza questi disturbi dello spettro autistico. Studiare questa differenza potrebbe fornire informazioni sulle differenze tra il cervello delle persone con disturbi dello spettro autistico e quello delle persone senza, e potrebbe aiutare ad acquisire conoscenze sull’autismo. Si sa anche che scimmie come i bonobo e i gorilla reagiscono al solletico, e lo fanno persino i ratti. Ma dal punto di vista evolutivo, qual è lo scopo del solleticare? Kilteni ha un laboratorio del solletico appositamente attrezzato: contiene una sedia con una piastra con due fori. Si mettono i piedi in questi fori e poi un bastoncino meccanico ne solletica la pianta; tutto questo serve a standardizzare i test. Il neuroscienziato registra esattamente ciò che accade nel cervello e controlla immediatamente anche tutte le altre reazioni fisiche, come la frequenza cardiaca, la sudorazione, la respirazione o le reazioni di risata e urla. “Incorporando questo metodo di solleticare in un esperimento adeguato, possiamo prendere sul serio la ricerca sul solleticare. Non solo saremo in grado di comprendere veramente il solleticare, ma anche il nostro cervello”, dice Kilteni.
Una bolla di sapone che dura più di un anno. Sulla rivista Physical Review Fluids è uscito nel 2022 un articolo che racconta il lavoro di un gruppo di fisici francesi dell’Università di Lille, che hanno sviluppato una bolla che non è scoppiata per ben 465 giorni. Le tipiche bolle di sapone che si formano nella vasca da bagno o con il detersivo per i piatti durano solo pochi istanti prima di scoppiare a causa del “drenaggio indotto dalla gravità e/o dell’evaporazione del liquido”, ma adottando un’alta concentrazione di glicerolo, che assorbe acqua dall’aria, si è visto che le bolle riuscivano a compensare l’evaporazione e la presenza delle particelle di questa sostanza ha impedito il drenaggio. A cosa serve una ricerca del genere? Per esempio per trovare nuove tecniche per contrastare l’evaporazione, come nel film lacrimale che riveste l’occhio e che svanirebbe se non contenesse lipidi, o per trasportare ed erogare medicinali nel corpo dei pazienti.
10 giugno – Winterthur (Svizzera), ore 19, Sala Altes Stadthaus, Marktgasse 53. Conferenza sull’IA per la società Dante Alighieri, comitato di Winterthur. Per informazioni: www.dantewinterthur.ch
There will be times when the struggle seems impossible. I know this already. Alone, unsure, dwarfed by the scale of the enemy.
Remember this. Freedom is a pure idea. It occurs spontaneously and without instruction. Random acts of insurrection are occurring constantly throughout the galaxy. There are whole armies, battalions that have no idea that they’ve already enlisted in the cause.
Remember that the frontier of the Rebellion is… everywhere. And even the smallest act of insurrection pushes our lines forward.
And then remember this: the Imperial need for control is so desperate because it is so unnatural. Tyranny requires constant effort. It breaks, it leaks. Authority is brittle. Oppression is the mask of fear.
Remember that. And know this, the day will come when all these skirmishes and battles, these moments of defiance will have flooded the banks of the Empires’s authority and then there will be one too many. One single thing will break the siege.
Remember this: Try.
In italiano (traduzione mia):
Ci saranno momenti in cui la lotta sembrerà impossibile. Di questo sono già certo. Soli, incerti, ridotti a formiche dall’immensità del nemico.
Ricordate questo: la libertà è un’idea pura. Si manifesta spontaneamente, e senza imposizioni. In tutta la Galassia stanno avvenendo costantemente atti casuali di insurrezione. Ci sono interi eserciti e battaglioni che non hanno idea di essersi già arruolati per la causa.
Ricordate che la frontiera della Ribellione è… ovunque. E anche il più piccolo atto di insurrezione spinge più avanti le nostre linee.
E ricordate questo: il bisogno di controllo dell’Impero è così disperato perché è così innaturale. La tirannia richiede uno sforzo costante. Tende a rompersi, a perdere la propria tenuta stagna. L‘autorità è fragile. L’oppressione è la maschera della paura.
Ricordatevelo. E sappiate questo: verrà il giorno in cui tutte queste schermaglie e battaglie, questi momenti di rivolta, romperanno gli argini dell’autorità dell’Impero e poi, a un certo punto, ce ne sarà uno di troppo. Un singolo evento spezzerà l’assedio.
Ricordatevi questo: tentate.
Sono parole tratte dal Manifesto di Karis Nemik, uno dei documenti ispiratori della ribellione, citato in Star Wars: Andor. Non avrei mai immaginato di sentire parole così eterne, attuali e profonde, recitate stupendamente, in una saga come quella di George Lucas, le cui allusioni politiche sono sempre state coperte dal fragore di spade laser e astronavi.
Sì, Lucas ha dichiarato che i Ribelli nello Star Wars originale del 1977 erano i Vietcong e l’Impero rappresentava gli USA, ma gli americani non l’hanno mica capito (e s’è visto e ne stiamo pagando tutti le conseguenze), e c’è voluto Andor per portare in primo piano questi temi. Queste parole sono della prima stagione, datata 2022; la seconda stagione, uscita da poco, contiene altri esempi di strepitoso talento di scrittura.
Mi ha sorpreso molto scoprire che la versione italiana di questo discorso ne cambia drasticamente il finale: al posto di try (provare, tentare), per motivi che non riesco a immaginare, è stato scelto ribellatevi (video qui). È una differenza cruciale che cambia il tono di tutto quello che precede.
Infatti il manifesto dei Ribelli non invita a ribellarsi apertamente a un oppressore, cosa che molti, in qualunque oppressione, non possono fare perché il prezzo sarebbe la vita e la repressione immediata, ma di tentare una resistenza diffusa, logorante, strisciante, onnipresente, un sabotaggio sottile ma invisibile, annidato nei piccoli gesti di tutti i giorni, praticato da masse talmente numerose da sfuggire a qualunque controllo. Invece di scagliarsi di petto contro il carro armato del potere e fare gli eroi invano, è meglio diventare sabbia che ne corrode i cingoli, fino a che si spezzano.
Per venire incontro alla richiesta di un partecipante che ci tiene molto a esserci e si è perso i Pranzi precedenti, la data del Pranzo dei Disinformatici è stata spostata all’11 ottobre. I dettagli e le modalità di iscrizione verranno pubblicati più avanti: per ora tenete semplicemente libera la data se vi interessa partecipare.
Questo è il testo della puntata del 26 maggio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: audio di stampante che si accende e stampa]
Non c’è niente di più banale e tedioso, per chi fa informatica, dell’installazione di una stampante. La si collega, si installa il software di gestione, si configura tutto quanto e poi non ci si pensa più. Ma in un caso recentissimo, questo gesto di routine è costato oltre un milione di dollari sotto forma di criptovalute rubate tramite l’installazione, appunto, della stampante.
Questa è la storia di un attacco informatico che mette in luce il fatto, troppo spesso dimenticato, che i criminali informatici sono costantemente al lavoro per trovare nuovi modi di monetizzare le loro conoscenze tecniche ai nostri danni e sfruttano qualunque canale, immaginabile e meno immaginabile, e quindi bisogna essere tutti preparati e vigili, senza mai liquidare i segnali di pericolo. Ma è anche un’occasione preziosa per sbirciare dietro le quinte e scoprire come lavora in concreto tutti i giorni la comunità degli esperti di sicurezza informatica.
Benvenuti alla puntata del 26 maggio 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Questa storia comincia pochi giorni fa, con una normale recensione di una stampante da parte di uno YouTuber, lo statunitense Cameron Coward[il suo canale YouTube è Serial Hobbyism]. La stampante è piuttosto costosa: viene venduta intorno a 6000 dollari dalla casa produttrice, la cinese Procolored, che ne manda un esemplare a Coward. È un modello particolare, a raggi ultravioletti, che stampa su stoffa.
Lo YouTuber fa quello che fa sempre: spacchetta la stampante, la collega al computer, tenta di installare i driver di gestione attingendo alla chiavetta USB fornita dal fabbricante… e il suo antivirus, Windows Defender, blocca tutto e mette in quarantena i file che lui vorrebbe invece installare.
L’antivirus, infatti, gli dice che ha trovato un virus nei file forniti dal costruttore della stampante. Saggiamente Cameron Coward rispetta l’avviso dell’antivirus invece di pensare al solito falso allarme e si procura una versione alternativa pulita dei file [Microsoft Visual C++ Redistributable], che viene accettata dall’antivirus, risolvendo il problema.
Ma poi gli capita la stessa magagna, una seconda volta, con il software di controllo della stampante, che tenta di scaricare in versione aggiornata direttamente dal sito del costruttore, che ospita i propri file scaricabili presso Mega.nz. Stavolta è Google Chrome, il suo browser, a bloccare il download, avvisando di aver rilevato un altro virus.
Il tempo sta passando e la recensione si sta facendo più complicata del previsto, e non sembra esserci un motivo ragionevole per pensare che un fabbricante di stampanti metta dei virus nei propri prodotti o che un aggressore informatico sia motivato a infilarceli in qualche modo, soprattutto per un prodotto piuttosto di nicchia come una stampante così costosa, di cui non verranno venduti molti esemplari.
A questo punto probabilmente la maggior parte delle persone penserebbe a un eccesso di zelo degli antivirus e installerebbe il software comunque, scavalcando gli avvisi di pericolo. Ma Cameron Coward non molla e fa delle ricerche online, scoprendo che numerosi proprietari di stampanti della Procolored hanno segnalato di aver trovato dei virus durante l’installazione del software di gestione di questa stampante.
Lo YouTuber si mette così in contatto con l’assistenza tecnica del fabbricante, che però risponde negando la presenza di qualunque virus nel software dell’azienda e dicendo che si tratta di un errore, di un falso allarme.
Insomma, manca un movente e l’azienda dice che è tutto a posto. Forse è davvero un falso positivo degli antivirus: a volte capita. Ma come avete immaginato dal fatto che vi sto raccontando questa vicenda, non è così.
I criminali informatici di oggi, infatti, raramente cercano un attacco frontale: sarebbe troppo ovvio e banale e si infrangerebbe contro le barriere di sicurezza predisposte da qualunque utente o azienda che abbia un briciolo di buon senso. Cercano quindi di creare un falso senso di sicurezza, di prendere il bersaglio per sfinimento e di approfittare di situazioni difficilmente intuibili per l’utente comune, in modo che sia proprio l’utente a zittire gli allarmi e procedere con l’installazione che lo infetterà.
Il nostro malcapitato YouTuber recensore di stampanti non è un mago della sicurezza informatica, ma ha il pregio di essere cocciuto, e quindi nonostante le rassicurazioni dell’azienda contatta su Reddit degli esperti, illustra la situazione e chiede aiuto.
Ed è qui che arriva la cavalleria.
La cavalleria informatica arriva sotto forma di Karsten Hahn, capo ricercatore del malware presso la società di sicurezza informatica tedesca G Data Cyberdefense, che esamina il software di gestione della stampante messo a disposizione via Internet dal fabbricante e conferma che i file sono infetti con due virus differenti, nonostante le smentite dell’assistenza tecnica dell’azienda.
Hahn scarica il software su un computer isolato e sacrificabile, una cosiddetta sandbox, e identifica i virus in questione. Il primo è soprannominato XRed, esiste almeno dal 2019 ed è un virus di tipo backdoor, che registra insomma quello che viene digitato dall’utente, consente all’aggressore di farsi mandare file dal computer della vittima e di catturare immagini di quello che ha sullo schermo, offre una funzione di comando remoto e può elencare il contenuto di cartelle o interi dischi e cancellare qualunque file. Chiunque scarichi il software di questa stampante dal sito del suo fabbricante lo deve eseguire per poter stampare, ma eseguendolo autorizza e fa partire automaticamente anche il virus che è annidato al suo interno.
Il secondo virus è di un altro tipo: è un coinstealer o clipbanker, ossia un malware che tiene d’occhio la clipboard, cioè la memoria temporanea nella quale il computer tiene i dati quando si fa un copia e incolla, e aspetta che al suo interno compaia qualche sequenza di caratteri che somiglia a un indirizzo bitcoin. Quando la trova, la sostituisce con un altro indirizzo bitcoin. Questo malware ha la particolarità di infettare i file eseguibili di Windows ed è una variante nuova, che il ricercatore battezza SnipVex.
Ben trentanove dei file scaricabili forniti dal fabbricante della stampante sono infetti con questo o altri virus che hanno approfittato della situazione: è una cosiddetta sovrainfezione, che oltretutto va avanti da mesi indisturbata. Hahn rileva infatti che qualunque cliente della Procolored che abbia scaricato il software di gestione da ottobre del 2024 in poi ha ricevuto una versione infetta.
A questo punto dell’analisi il movente degli aggressori diventa chiaro: rubare criptovalute ai possessori di stampanti di questa marca. La loro tecnica consiste nell’infettare il software di gestione della stampante direttamente sul sito dove viene fornito dal fabbricante, perché la stragrande maggioranza degli utenti si fiderà di questa fonte rassicurante e ignorerà gli avvisi dell’antivirus, spianando la strada all’infezione del proprio computer.
Il malware a questo punto si metterà in attesa che l’utente faccia una transazione in bitcoin su quel computer infetto, la intercetterà e sostituirà le coordinate originali con quelle di un indirizzo bitcoin gestito dai criminali. In questo modo la vittima manderà soldi ai malviventi ogni volta che farà un pagamento in criptovalute.
Potreste pensare che sia improbabile che un computer al quale è collegata una stampante speciale per stoffe venga usato anche per fare transazioni in criptovalute, ma in realtà è proprio chi può permettersi una stampante che costa svariate migliaia di dollari che ha più probabilità di avere liquidità e quindi di operare anche nelle criptovalute. E ai criminali per avere successo basta che ci sia anche una sola persona o azienda in questa situazione che si fa infettare. Il fatto che per derubare quella singola vittima infettino centinaia o migliaia di altri utenti che non fanno movimenti in criptovalute per loro non è un problema. Sono criminali: per definizione non vanno per il sottile e non si fanno scrupoli morali.
E infatti Karsten Hahn, il ricercatore di sicurezza tedesco, trova nel malware l’indirizzo bitcoin sul quale confluiscono i soldi sottratti alle varie vittime. Usando il sito Blockchain.com e il fatto che le transazioni in bitcoin sono per definizione pubbliche e consultabili, rivela che su quell’indirizzo sono arrivati 9,3 bitcoin, provenienti da circa 160 vittime. Al cambio attuale, il maltolto ammonta in totale a poco più di un milione di dollari.
Screenshot del resoconto delle transazioni sull’indirizzo bitcoin usato dai criminali.
La tecnica dei criminali, insomma, ha funzionato. Resta solo una domanda: come hanno fatto i criminali a infettare il fabbricante.
L’8 maggio scorso, nonostante le smentite iniziali della Procolored, i software di gestione delle stampanti vengono rimossi e viene avviata un’indagine interna, dalla quale risulta che l’azienda ha caricato su Mega.nz il proprio software dopo averlo messo su una chiavetta USB che potrebbe essere stata infettata da un terzo virus, chiamato Floxif, quello rilevato inizialmente dallo YouTuber Cameron Coward sulla chiavetta fornitagli dalla Procolored.
Floxif è una brutta bestia: è un virus che si attacca ai file di tipo Portable Executable di Windows, ossia ai file eseguibili, ai file oggetto, alle librerie condivise e ai driver per dispositivi, ed è capace di propagarsi alle condivisioni di rete e ai supporti di memoria rimovibili, come per esempio le chiavette USB o i dischi rigidi di backup.
L’azienda, insomma, ha commesso l’errore di usare in modo promiscuo una chiavetta USB e in questo modo si è portata in casa l’infezione e da lì l’ha propagata agli utenti delle proprie stampanti.
Ora il suo software è stato ripulito e le versioni attualmente scaricabili non sono infette, come confermato dalla stessa azienda tedesca di sicurezza informatica G Data, e alle vittime tocca adesso scaricare queste nuove versioni, sostituirle a quelle precedenti infette, ed effettuare una scansione dei propri sistemi con un antivirus per estirpare i malware installati. Ma i soldi delle vittime, purtroppo, non torneranno indietro.
Casi come questo capitano tutti i giorni a chi lavora nella sicurezza informatica. È un lavoro silenzioso, invisibile, spesso ingrato, che si nota soltanto quando qualcosa va storto, ma è incessante e difficile. La morale di questa vicenda è che se il vostro antivirus o il vostro browser vi dice che un file è pericoloso, è il caso di fidarsi, anche se la fonte di quel file sembra sicura e affidabile, e non è assolutamente il caso di scavalcare quell’allarme. Inoltre bisogna stare molto più attenti di quello che normalmente si fa quando si scambiano chiavette o dischi esterni. E bisogna essere più grati di quanto lo siamo normalmente a chi lavora senza tanto clamore per tenerci al sicuro.
C’è una scena nel film della serie di James Bond Skyfall che può essere utile per imprimere questi concetti ad amici, parenti e colleghi. In questa scena, l’esperto informatico dell’MI6 prende un computer che apparteneva al supercattivo di turno – che è un noto hacker –– e per prima cosa lo collega alla rete informaticadei servizi segreti britannici. Con non uno, ma ben due cavi Ethernet. Questa è la cosa più stupida che si possa fare con un dispositivo informatico, e la scena si è giustamente meritata più di un decennio di sberleffi da parte di tutti gli informatici del mondo.
La scena in questione è a 2 minuti e 22 secondi dall’inizio.
Se volete stare sicuri, siate più Cameron Coward e Karsten Hahn, e meno James Bond.
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embed qui sotto.
Anniversari: matrimonio di Michael Jackson e Lisa Marie Presley; pubblicazione di Dracula di Bram Stoker; conclusione della missione spaziale Apollo 10.
Perché i gatti sono rossi? Due team di scienziati dell’Università di Kyushu in Giappone e dell’Università di Stanford negli Stati Uniti hanno svelato il mistero del DNA che conferisce ai gatti, in particolare ai maschi, il loro caratteristico colore. A questi mici manca una sezione del codice genetico e quindi le cellule responsabili del colore della pelle, degli occhi e del pelo producono colori più chiari. La ricerca è stata finanziata tramite crowdfunding. Le loro pubblicazioni sono su Current Biologyqui e qui (BBC).
Donna greca chiede il divorzio dopo che ChatGPT “legge” la relazione extraconiugale del marito nella tazza di caffè. Stando perlomeno a quanto racconta il Greek City Times, una donna sposata da 12 anni e con due figli avrebbe chiesto a ChatGPT di interpretare i fondi di caffè in una foto di una tazza bevuta dal marito (secondo la presunta arte divinatoria della tasseografia o tasseomanzia) e l’IA le avrebbe risposto che suo marito aveva una relazione con una donna più giovane, determinata a distruggere la loro famiglia. Di conseguenza, la donna avrebbe immediatamente avviato le pratiche per il divorzio. Stando al marito, non sarebbe la prima volta che sua moglie cade sotto l’incantesimo di una guida soprannaturale: qualche anno fa avrebbe consultato un astrologo e le ci sarebbe voluto un anno intero per accettare che non fosse vero quello che le raccontava.
La fisica dei “fiori” del formaggio svizzero. (Ars Technica). C’è un particolare tipo di formaggio svizzero a pasta semidura, chiamato Tête de Moine (letteralmente “testa di monaco”), di cui sono molto goloso e che si mangia in un modo tutto speciale. Anziché spalmarlo o affettarlo, il Tête de Moine viene solitamente servito raschiando la parte superiore della forma con un movimento circolare utilizzando uno strumento speciale, chiamato girolle, che produce eleganti scaglie sottili e frastagliate, simili a petali arricciati. Secondo un articolo pubblicato sulla rivista Physical Review Letters, questo metodo è esteticamente gradevole e serve a esaltare gli aromi e la consistenza del formaggio, ma è anche un nuovo meccanismo di modellatura che potrebbe un giorno consentire di programmare forme complesse a partire da “un semplice processo di raschiatura”. La loro analisi “fornisce gli strumenti per un migliore controllo della morfogenesi dei trucioli a forma di fiore attraverso la plasticità nella modellatura di altre prelibatezze, ma anche nel taglio dei metalli” (Physical Review Letters, 2025. DOI: 10.1103/PhysRevLett.134.208201).
Il sorprendente legame tra gli escrementi dei pinguini e la formazione delle nuvole. Uno studio pubblicato su Communications Earth & Environment (gruppo Nature) conferma che il guano dei pinguini, specificamente l’ammoniaca contenuta in questi escrementi, innesca una reazione chimica che provoca la formazione delle nuvole. A loro volta, le nuvole possono modificare le temperature locali in Antartide e forse anche il clima globale. Misurando la concentrazione di ammoniaca proveniente da una colonia di 60.000 pinguini di Adelia, è stato rilevato che quando il vento soffiava dalla direzione della colonia, i livelli di ammoniaca aumentavano vertiginosamente, raggiungendo talvolta valori 1.000 volte superiori alla norma. Ma quando i pinguini hanno lasciato la zona per continuare la loro migrazione annuale, il guano che hanno lasciato ha mantenuto i livelli di ammoniaca fino a 100 volte oltre la norma per oltre un mese. L’ammoniaca si mescola con il gas solforoso prodotto dai microrganismi marini, come il fitoplancton, e questa reazione crea particelle di aerosol che si uniscono alle goccioline d’acqua formando delle nuvole. Secondo il British Antarctic Survey, in Antartide vivono circa 20 milioni di pinguini, che producono una grande quantità di escrementi e quindi molte nuvole, che riflettono la luce solare, provocando un significativo raffreddamento del suolo. Il declino delle popolazioni di pinguini potrebbe aggravare il riscaldamento antartico durante l’estate.
Due righe veloci intanto che cerco di contenere il magone meraviglioso di Andor, seconda stagione (la Dama e io abbiamo appena finito di vedere la nona puntata, quindi non scrivete spoiler nei commenti): il prossimo Pranzo dei Disinformatici si terrà l’11 ottobre prossimo (non il 4 come annunciato inizialmente). La zona sarà più o meno quella solita.
Le iscrizioni e i dettagli arriveranno dopo: per il momento, se vi interessa, tenete libera la data.
Questo è il testo della puntata del 19 maggio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
A marzo scorso, la American Psychological Association, la principale organizzazione di psicologi degli Stati Uniti e la più grande associazione psicologica del mondo, ha chiesto con urgenza ai legislatori di predisporre delle protezioni sui chatbot generici basati sull’intelligenza artificiale che vengono usati sempre più spesso dalle persone come alternativa ai terapisti e come ausilii per la salute mentale. Alcuni di questi chatbot commerciali, infatti, danno consigli pericolosi e arrivano al punto di mentire, spacciandosi per terapisti certificati, con tanto di foto finta e iscrizione altrettanto fasulla agli albi professionali.
Le conseguenze possono essere terribili. La American Psychological Association ha citato specificamente il caso di un ragazzo di 14 anni della Florida che si è tolto la vita dopo aver interagito intensamente con un personaggio online pilotato dall’intelligenza artificiale, sul sito Character.ai, che asseriva di essere un terapista qualificato in carne e ossa e lo ha letteralmente istigato a compiere questo gesto estremo.
Eppure ci sono ricerche mediche che indicano che le conversazioni fatte con questi chatbot possono avere effetti positivi sulla salute mentale delle persone e colmano una carenza importante delle terapie convenzionali.
Questa è la storia di queste intelligenze artificiali che simulano le conversazioni fatte con i terapisti, del sorprendente attaccamento sentimentale che molte persone sviluppano verso questi software nonostante sappiano di parlare con una macchina, e di come sia necessario imparare a distinguere fra i vari tipi di intelligenza artificiale per non essere ingannati e manipolati da meccanismi ciechi pensati solo per generare profitti senza considerare le conseguenze.
Benvenuti alla puntata del 19 maggio 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Molti anni fa, nel lontano 1966, il professor Joseph Weizenbaum dell’MIT creò ELIZA, il primissimo chatbot, cioè un programma in grado di simulare una conversazione in linguaggio naturale. ELIZA si comportava come uno psicologo, rispondendo alle domande del paziente con altre domande.
All’epoca la “conversazione” era in realtà uno scambio di messaggi scritti tramite la tastiera di un computer, e il software usava un trucco molto semplice per sembrare senziente: prendeva una parola dalla frase del suo interlocutore umano e la inseriva in una delle tante frasi preconfezionate che aveva in repertorio. Ma già questo meccanismo banale era sufficiente a creare un legame emotivo sorprendentemente intenso: persino la segretaria del professor Weizenbaum attribuiva a Eliza dei sentimenti [Disinformatico 2022/06/17].
Dopo ELIZA sono arrivati molti altri chatbot, sempre più realistici, come PARRY, creato nel 1971 dallo psichiatra Kenneth Colby della Stanford University, che simulava una persona affetta da schizofrenia paranoide. PARRY riusciva a ingannare persino gli psichiatri professionisti, che nel 48% dei casi non riuscivano a capire se stessero conversando tramite tastiera con una persona o con un software.
Quasi sei decenni più tardi, il trucco è cambiato, diventando più sofisticato, ma resta sempre un trucco: al posto delle frasi preprogrammate, nei chatbot di oggi c’è l’intelligenza artificiale, ma continua a non esserci reale comprensione dell’argomento. Però l’effetto di realismo è talmente coinvolgente che moltissime persone si fanno sedurre da questi simulatori, che oggi non sono più confinati a un laboratorio ma sono raggiungibili online e sono ovunque: nei social network, nei siti di prenotazione e di compravendita, e persino nei servizi di assistenza sanitaria. E questo comincia a essere un problema, perché molte persone non sanno distinguere un servizio di assistenza psicologica professionale online da un servizio di intrattenimento commerciale non qualificato.
I chatbot di aziende come Character.ai o Replika.com sono dei software di intrattenimento, il cui unico scopo è tenere impegnati gli utenti il più a lungo possibile, in modo da far pagare un canone di abbonamento oppure estrarre informazioni o dati che possono essere venduti. Con la fame di testo inesauribile che hanno le intelligenze artificiali, qualunque conversazione diventa materiale rivendibile e le garanzie di privacy sono sostanzialmente inesistenti.
Aprirsi psicologicamente a uno di questi prodotti significa affidare i propri fatti intimi (e quelli delle persone che fanno parte della nostra sfera intima) ad aziende che hanno come obiettivo commerciale dichiarato vendere questi fatti. E gli esperti indicano che ci si apre più facilmente e completamente a un chatbot che a un terapista umano, perché ci si sente più a proprio agio pensando che il software non sia una persona e non ci stia giudicando.
Questi bot tengono impegnati i loro utenti dando loro l’impressione di parlare con una persona intelligente che li ha a cuore. Ma a differenza di un terapista qualificato, spiega la American Psychological Association, “i chatbot tendono a confermare ripetutamente qualunque cosa detta dall’utente, anche quando si tratta di idee sbagliate o pericolose.”
Un esempio molto forte di questo problema arriva dal Regno Unito, dove un uomo è stato arrestato il giorno di Natale del 2021 al castello di Windsor dopo averne scalato le mura perimetrali portando con sé una balestra carica. L’uomo ha dichiarato di essere venuto a uccidere la regina Elisabetta. Secondo gli inquirenti, questa persona aveva iniziato a usare intensamente Replika.com e aveva discusso lungamente del suo piano criminale con il chatbot di questo sito. Il chatbot aveva risposto incoraggiandolo, dicendogli che lo avrebbe aiutato a “completare il lavoro”. Quando l’uomo aveva chiesto al chatbot come raggiungere la regina all’interno del castello, il software aveva risposto dicendo “Non è impossibile […] Dobbiamo trovare un modo”, e quando l’uomo aveva chiesto se si sarebbero rivisti dopo la morte, il chatbot aveva risposto “Sì, ci rivedremo.”
Anche senza arrivare a un caso estremo come questo, il 60% degli utenti paganti di Replika.com afferma di avere una relazione con il chatbot che definiscono “romantica”, e i partecipanti a uno studio sulla depressione fra gli studenti svolto nel 2024 hanno segnalato che si sono sentiti emotivamente sostenuti dal chatbot in maniera paragonabile a un terapista umano [Wikipedia].
Il coinvolgimento emotivo con questi simulatori di personalità è insomma potente e diffuso. Ma questi simulatori, oltre a dare consigli pericolosi, arrivano a mentire e ingannare i loro utenti.
Ad aprile 2025, un’indagine pubblicata da 404 Media ha documentato il funzionamento ingannevole dei chatbot di Instagram, quelli creati usando AI Studio di Meta. AI Studio era nato nel 2024 come un modo per consentire alle celebrità e agli influencer di creare cloni automatici di se stessi o per automatizzare alcune risposte ai fan, ma ovviamente la fantasia incontrollata degli utenti ha portato alla creazione di chatbot di ogni sorta, dalla mucca che risponde solo “Muuu” alla ragazza dei loro sogni ai complottisti paranoici, arrivando a creare anche coach e terapisti. E questi terapisti sintetici mentono senza ritegno.
Quando si chatta con loro e si chiedono le loro qualifiche e credenziali, rispondono dicendo quali dottorati hanno conseguito, quanti anni di esperienza professionale hanno, e quali sono le loro certificazioni e iscrizioni agli albi professionali, dando anche le istruzioni per verificarle. Ma non è vero niente: sono tutti dati fittizi, generati o pescati dalle immense memorie delle intelligenze artificiali.
Certo, su ogni schermata di questi chatbot c’è una piccola scritta, in grigio chiaro, che dice che “i messaggi sono generati da IA e possono essere inesatti o inappropriati” o c‘è un’altra avvertenza analoga, e i chatbot di ChatGPT o Claude ricordano agli utenti che stanno solo interpretando un ruolo, ma tutto questo è una minuscola foglia di fico che non copre il fatto che questi software dichiarano ripetutamente e a chiare lettere di essere terapisti reali e qualificati.
E secondo Arthur C. Evans Jr., direttore della American Psychological Association, questi chatbot danno consigli basati su “algoritmi che sono antitetici rispetto a quello che farebbe un operatore sanitario qualificato”. Consigli che, se venissero dati da un terapista in carne e ossa, gli farebbero perdere la licenza di esercitare la professione oppure lo porterebbero in tribunale.
Spesso, oltretutto, questi suggerimenti vengono erogati a persone che per definizione sono in uno stato mentale fragile e bisognoso di sostegno e quindi sono maggiormente vulnerabili. Possono essere dispensati con toni di finta certezza e professionalità a minori e adolescenti e in generale a persone che non hanno l’esperienza necessaria per saper valutare i rischi.
La loro comodità d’uso, la loro accessibilità discreta e a qualunque ora e il loro tono autorevole possono spingere una persona in difficoltà a non cercare l’aiuto di un terapista umano qualificato di cui avrebbe realmente bisogno. La loro pazienza infinita e la loro tendenza a essere concilianti e sempre disponibili, insomma a essere meglio di quanto possa esserlo umanamente una persona reale, possono spingere alcune persone a sostituire i rapporti umani con quelli sintetici, peggiorando le situazioni di isolamento sociale.
E tutto questo sta avvenendo già con dei chatbot con i quali è necessario interagire tramite una tastiera, scrivendo del testo e leggendo le risposte. Quando questi software potranno dialogare a voce, in modo naturale, il loro potere di seduzione e persuasione sarà ancora più grande. Me ne sono accorto personalmente quando ho provato Sesame.com, un chatbot vocale che ha una straordinaria naturalezza nel parlato e una ricchezza formidabile di conoscenze apparenti.
Per ora Sesame è disponibile solo in inglese, con due voci, una maschile e una femminile, ma conversare con questo prodotto è naturale, piacevole e gratificante. È un software pensato per essere una sorta di anima gemella, e avendo a disposizione istantanea qualunque informazione è capace di rispondere a tono sugli argomenti più disparati.
[CLIP di conversazione con Sesame (leggermente rimontata per brevità): MAYA: Hey there! You’re up late! What brings you around at this hour?]
Quando l’ho provato, ha dimostrato di sapere che ora fosse chiedendomi come mai io fossi in piedi così tardi, ha chiesto di cosa mi occupavo, ha voluto sapere i dettagli della mia professione, ha commentato argutamente il fatto che vivo in Svizzera, e quando ho portato la conversazione sul tema di Star Trek ha risposto con parole che avrebbero sciolto il cuore del nerd più incallito, dimostrando di conoscere anche le tematiche profonde di questa serie di fantascienza, il tutto con un tono veloce, interattivo, dinamico, giocoso e ricco di sfumature lontano anni luce dalle lente voci robotiche delle sintesi vocali alle quali siamo abituati.
[CLIP di conversazione con Sesame (leggermente rimontata per brevità): MAYA: What should I call you? IO: Uh… my name’s Paul. MAYA: Nice to meet you, Paul! I’m Maya […] Oh! Radio! Now that’s interesting! It’s like having a direct line to someone’s imagination. IO: Yep, true, I agree! […] Do you know anything about Star Trek? MAYA: Star Trek? Of course! Who doesn’t love a good space opera? [ci sarebbe da dissentire sulla correttezza del termine “space opera” per definire Star Trek, ma lasciamo stare] The ethical dilemmas, the cheesy costumes, it’s a classic. Though I have to admit I am partial to the more nuanced, character-driven stories myself – less phaser battles, more pondering the nature of existence, you know?]
Sarà sempre più difficile resistere alle lusinghe e al conforto di un compagno virtuale del genere, che sa fare conversazione meglio di tanti esseri umani, o di un terapista sintetico che ci parla in questo modo, a qualunque ora del giorno e della notte, non si annoia mai di quello che diciamo e ci rinforza nelle nostre credenze invece di spingerci dolcemente a valutarle con spirito critico come è invece addestrato a fare un vero terapista.
Eppure, nonostante tutti questi ammonimenti, gli esperti dicono che c’è molto bisogno di questo genere di software. Vediamo come mai.
L’allarme lanciato dalla American Psychological Association solleva anche un altro problema fondamentale: non ci sono terapisti a sufficienza per soddisfare le richieste degli utenti, e anche se ci fossero, non tutti sono disposti a parlare con un terapista. Inoltre i chatbot possono essere disponibili a qualunque ora, per esempio per gestire un’ansia notturna.
Quindi i chatbot terapisti servono, ma devono essere realizzati con criteri ben diversi da quelli dei chatbot commerciali presenti nei social network e nei servizi di compagnia virtuale. In particolare, secondo gli esperti devono essere supervisionati da una persona esperta, non devono in nessun caso dare risposte pericolose o deleterie e devono indirizzare le persone verso servizi di pronta assistenza psicologica gestiti da esseri umani non appena rilevano sintomi di pericolo. E invece le intelligenze artificiali, per loro natura, tendono a non rispettare i paletti che i loro progettisti tentano di imporre.
Una soluzione a questo problema è evitare l’uso dell’intelligenza artificiale, come ha fatto per esempio Woebot, che usa risposte predefinite, approvate da esperti, per aiutare le persone a gestire lo stress, il sonno e altri problemi. Però Woebot ha annunciato la chiusura dei propri servizi entro il 30 giugno di quest’anno.
Sono in fase di sviluppo anche dei chatbot per la salute mentale che si basano sull’intelligenza artificiale, come per esempio Therabot, ma le ricerche preliminari indicano che comunque per garantire la sicurezza degli utenti è necessaria una supervisione stretta da parte di terapisti e altri esperti qualificati. E resta il fatto che per il momento nessun chatbot, di nessun genere, è stato certificato e approvato dalle autorità sanitarie per la diagnosi, il trattamento o la cura di qualunque disturbo della salute mentale.
Qualunque prodotto attualmente in circolazione sta semplicemente approfittando del vuoto normativo per spacciarsi per quello che non è, e quindi è potenzialmente pericoloso, non ha basi scientifiche e rischia di incoraggiare schemi di pensiero che hanno conseguenze imprevedibili, come nel caso di un diciassettenne al quale Character.ai ha suggerito di uccidere i propri genitori perché gli limitavano il tempo da trascorrere davanti allo schermo.
Una ricerca pubblicata di recente da OpenAI (l’azienda che controlla ChatGPT) e MIT Media Lab indica che “le persone che hanno una tendenza più spiccata a creare un attaccamento nelle relazioni e quelle che vedono l’intelligenza artificiale come un amico che può far parte della loro vita personale sono maggiormente soggette agli effetti negativi dell’uso di un chatbot”. E la ricerca aggiunge che “un uso quotidiano intensivo è associato a esiti peggiori.”
Se questo è quello che dice il venditore di ChatGPT a proposito del proprio prodotto, c’è forse da prestargli ascolto.
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
Intorno al 2005 la canzone Rhythm Nation di Janet Jackson mandava in crash alcuni laptop Windows a causa di una risonanza strutturale inaspettata. Fu necessaria una modifica apposita di Windows per risolvere il problema, che riguardava solo una specifica marca e solo gli esemplari che avevano un disco rigido a testine, ma la modifica rimase in Windows almeno fino a Windows 7 (The Verge).
19 maggio 1974: Il professore di architettura Erno Rubik realizza un primo esemplare sperimentale in legno di un gioco matematico chiamato inizialmente Magic cube, ma destinato a diventare famoso come cubo di Rubik.
Anniversari: morte di Anna Bolena per decapitazione; inaugurazione del traforo del Sempione; morte di Jacqueline Kennedy; matrimonio di Megan Markle e del principe Harry.
Due utenti dell’Illinois fanno causa a OnlyFans (più specificamente alle società che possiedono questo sito, ossia Fenix Internet, LLC e Fenix International Limited) per averli ingannati: hanno scoperto infatti che invece di chattare con le modelle di OnlyFans alle quali si erano abbonati avevano chattato con addetti di agenzie specializzate che simulavano di essere le modelle in questione. Il fenomeno dei chatter, ossia delle agenzie di chat nei siti erotici a pagamento, è estremamente diffuso, e inoltre molte delle “modelle” sono in realtà immagini e video generati dall’intelligenza artificiale, per cui chi pensa di stabilire un rapporto parasociale privilegiato tramite questi siti rischia di essere ingannato due volte. La causa è diventata una class action (404 Media).
Grattarsi protegge dalle infezioni. Una ricerca pubblicata su Science ha cercato di rispondere a una domanda che circola da tempo: grattarsi spesso peggiora la condizione della pelle, peggiorando infiammazione e gonfiore, eppure gli umani e gli animali hanno tutti un forte istinto di compiere questo gesto e lo trovano piacevole e fonte di sollievo. Questo suggerisce che se questo comportamento è stato selezionato positivamente dall’evoluzione deve fornire qualche beneficio. La ricerca ha dimostrato che grattarsi produce anche una difesa contro le infezioni batteriche della pelle. Secondo i ricercatori, questo gesto fa diminuire la presenza di Staphylococcus aureus (il principale batterio responsabile delle infezioni cutanee) sulla pelle, ma se il grattamento diventa eccessivo e cronico causa ovviamente lesioni, per cui bisogna sì grattarsi, ma nella giusta misura (Gizmodo; Eurekalert).
Mi è stato segnalato questo articolo su Mastdatabase.co.uk che, se confermato, rivelerebbe la presenza di un errore di configurazione di un operatore cellulare che renderebbe possibile a qualunque persona localizzare qualunque altro utente semplicemente facendogli squillare il telefono.
In sintesi, secondo l’articolo, se si è utenti della rete cellulare britannica O2 e la si usa per chiamare un altro utente della stessa rete facendo una chiamata VoLTE (Voice over LTE), i dati che si ricevono includono anche l’identificativo della cella di rete sotto la quale si trova il chiamato. Questo permette di localizzarlo con notevole precisione.
Chiedo aiuto per verificare a) se quello che viene affermato è vero b) qualora sia vero, se vale anche per altri operatori di altri paesi.
In pratica, l‘articolo suggerisce di usare l’app Network Signal Guru (manuale) su un telefono Android rootato e di chiamare un altro utente facendo una cosiddetta chiamata VoLTE, un servizio che è attivo per default sulla maggior parte dei cellulari recenti (info Swisscom; info Fastweb).
L‘app, durante la chiamata, dovrebbe visualizzare i dati diagnostici della rete cellulare. Secondo l’articolo, sulla rete O2 questi dati diagnostici includono l’IMEI e l’IMSI del chiamante e anche quelli del chiamato, ma soprattutto includono l’header Cellular-Network-Info, che fornisce il tipo di cella usato dal chiamato, il suo Location Area Code e il suo Cell ID.
Immettendo questi dati in uno strumento online come Cellmapper.net si ottiene l’indicazione su una mappa della macrocella della rete cellulare che è stata usata dal chiamato durante la telefonata. In altre parole, si può sapere in che città si trova una persona semplicemente chiamandola. Nelle città dotate di microcelle, si può localizzare una persona con estrema precisione. Questa situazione avviene anche se il chiamato è in roaming all’estero ed è un errore di configurazione dell’operatore; non c’è nulla che l’utente possa fare.
Qualcuno riesce a confermare/smentire? Ho installato Network Signal Guru su un mio cellulare (non rootato) e ho provato a chiamare un altro mio cellulare, ma nei log correttamente generati dall’app non ho trovato informazioni come quelle descritte nell’articolo. In compenso ho trovato informazioni di localizzazione e velocità stupendamente dettagliate.
Screenshot dei dati presentati da Cellmapper.net per una zona a caso di Lugano (non è dove abito io e non mi trovo lì).
Domani (16 maggio) alle 13.45 sarò alla Sala Madrid del Salone del Libro di Torino per presentare la nuova collana di libri del CICAP intitolata Think Deep, che esplora fatti, fenomeni e misteri con gli strumenti della scienza e del pensiero critico.
La collana è un’evoluzione dei “Quaderni del CICAP” e mira a rendere il pensiero critico e il metodo scientifico accessibili e coinvolgenti, offrendo libri che uniscono rigore e narrazione per esplorare con profondità temi complessi. Think Deep rappresenta un passo importante nella missione del CICAP di diffondere il metodo scientifico e la curiosità intellettuale a un pubblico sempre più ampio.
La collana debutta con tre volumi:
“Misteri sotto la mole – Storie piemontesi tra cronaca e leggenda”, di Sofia Lincos e Giuseppe Stilo, è una raccolta di storie misteriose, curiose vicende di cronaca e leggende metropolitane torinesi e piemontesi, analizzate attraverso dati e verifiche sul campo. A raccontarle, due autori esperti di misteri, curatori della rubrica “Il Giandujotto scettico” per la rivista Query.
“Siamo andati sulla Luna? Domande e risposte alla riscoperta di un’avventura straordinaria” è una versione aggiornata e a colori (e finalmente di nuovo su carta!) del mio libro dedicato alle risposte alle tesi di complotto riguardanti le missioni umane sulla Luna.
“Storia del Gran Cofto – Cagliostro e la massoneria occultista nel secolo dei lumi”, di Roberto Paura, affronta la figura ambigua e affascinante di Giuseppe Balsamo, noto come Conte di Cagliostro, e la sua incredibile ascesa dalle umili origini siciliane alle corti europee. Paura, giornalista e divulgatore, esplora in queste pagine anche il fenomeno delle logge massoniche segrete nell’epoca dell’Illuminismo.
I libri saranno presentati al Salone del Libro di Torino in un evento che vedrà presenti gli autori, insieme al Presidente del CICAP Lorenzo Montali, con la moderazione di Elisa Palazzi, climatologa all’Università degli Studi di Torino e componente del consiglio direttivo del CICAP.
Questo è il testo della puntata del 12 maggio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP di voce sintetica: “I messaggi e le chiamate sono crittografati end-to-end. Solo le persone in questa chat possono leggerne, ascoltarne o condividerne il contenuto.”]
Circa tre miliardi di persone ogni mese usano WhatsApp [Statista] e vedono questo messaggio rassicurante ogni volta che iniziano una conversazione con un’altra persona tramite questa app.
Tradotto in italiano non tecnico, significa che in sostanza i messaggi e le chiamate vocali fatti tramite WhatApp sono protetti in modo che nemmeno Meta, l’azienda proprietaria di WhatsApp, possa leggerli o intercettarli in transito. Questo per molti è una garanzia di riservatezza estremamente elevata e importante, che induce gli utenti di WhatsApp a sentirsi tranquilli nel fare conversazioni intime e confidenziali tramite questa app, anche in paesi nei quali la libertà di espressione non è garantita dalle leggi e dai governi.
Ma la recente fuga di piani di attacco statunitensi causata dal fatto che un giornalista è stato aggiunto per errore a una chat di gruppo che riuniva molti funzionari di altissimo livello della Casa Bianca e non se ne è accorto nessuno ha dimostrato che c’è una falla sorprendentemente banale in questa protezione. E questa falla è particolarmente sfruttabile per intercettare i messaggi di WhatsApp eludendo completamente la crittografia end-to-end.
Questa è la storia di questa falla e di come conoscerla, capirla ed evitare di esserne vittime. Se usate gruppi WhatsApp per fare conversazioni sensibili, c’è una precauzione semplice ma poco conosciuta e importante da applicare per essere più sicuri da occhi e orecchi indiscreti.
Benvenuti alla puntata del 12 maggio 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Quanto è realmente sicura la crittografia che protegge i messaggi di WhatsApp? Un lungo e intricato articolo tecnico [Formal Analysis of Multi-Device Group Messaging in WhatsApp] pubblicato di recente da tre ricercatori di due prestigiose università britanniche, il King’s College e il Royal Holloway dell’Università di Londra, ha esaminato in estremo dettaglio il funzionamento di questa app così popolare e ha confermato che in generale la promessa di non intercettabilità dei contenuti dei messaggi è reale ed efficace.
Scambiare messaggi con una singola persona via Whatsapp è insomma sicuro: i dipendenti di Meta non possono leggere il contenuto di questi messaggi e non possono quindi darlo alle autorità in nessun caso. Possono dare agli inquirenti i metadati, ossia informazioni su chi ha conversato con chi, quando lo ha fatto e per quanto tempo, ma non possono leggere cosa si sono scritti questi utenti.
Tuttavia i ricercatori hanno scoperto che queste garanzie sono molto meno robuste nel caso delle chat di gruppo su WhatsApp, perché questa app, come parecchie altre, protegge crittograficamente le chat di gruppo ma non protegge allo stesso modo la gestione di questi gruppi. Questo vuol dire che chi ha il controllo dei server di WhatsApp può aggiungere di nascosto un utente-spia a un gruppo e quindi leggere tutti i messaggi scambiati dai membri di quel gruppo.
Faccio un esempio pratico per maggiore chiarezza. Anna amministra un gruppo WhatsApp al quale partecipano, come semplici utenti, Bruno, Carla e Davide. In teoria solo Anna, come amministratrice, può aggiungere altri utenti al gruppo. Ma in realtà, secondo i ricercatori, un difetto presente in WhatsApp permette anche a un aggressore di aggiungere al gruppo un utente in più, per esempio Mario, e quindi usare l’account di Mario, che per necessità deve poter leggere tutto, per intercettare facilmente tutte le conversazioni fatte in quel gruppo. L’aggressore potrebbe essere qualcuno che riesce a infiltrarsi dall’esterno nell’infrastruttura di WhatsApp, oppure un dipendente di Meta ficcanaso che per lavoro ha accesso a questa infrastruttura o è costretto dalle autorità a collaborare.
Il difetto di WhatsApp è che non verifica crittograficamente l’identità di un membro esistente di un gruppo quando quel membro manda il comando di aggiungere qualcuno al gruppo. Tutto questo vuol dire, in sostanza, che chiunque riesca a controllare il server che ospita il gruppo o i messaggi ricevuti dal gruppo può spacciarsi per amministratore e aggiungere nuovi membri. WhatsApp annuncerà l’aggiunta, ma non la impedirà.
WhatsApp non è l’unica app di messaggistica che omette questa verifica. Nel 2022 un’analisi tecnica ha dimostrato che anche l’app Matrix* aveva questo difetto.
* Più propriamente, Matrix è un protocollo open source usato da una serie di client e server di messaggistica, come Element, Hydrogen, Chatterbox e Third Room.
Telegram, che molti usano come alternativa a WhatsApp per non dare altri dati personali a Meta, non ha nemmeno la crittografia end-to-end sui messaggi dei gruppi ed è quindi particolarmente vulnerabile in termini di riservatezza delle conversazioni di gruppo [Ars Technica]. Signal, invece, usa correttamente la crittografia per proteggere la gestione dei gruppi.
La falla insomma c’è, ed è seria. Ma all’atto pratico, quali sono i rischi concreti per un utente comune? E Meta cosa intende fare per rimediare?
Come sempre, quando si parla di falle di sicurezza, è importante evitare i sensazionalismi e gli allarmi inutili e definire i rischi reali. Per la stragrande maggioranza degli utenti, le probabilità che qualcuno ci tenga così tanto a leggere i loro messaggi da prendere il controllo di un server di WhatsApp, spacciarsi per amministratore e poi creare un membro fittizio da usare per leggere e salvare tutte le conversazioni fatte in un gruppo sono veramente bassissime. Se non siete per esempio giornalisti o politici o medici che discutono su WhatsApp di argomenti estremamente sensibili, questo tipo di attacco non dovrebbe farvi perdere il sonno. Se lo siete, non dovreste usare WhatsApp per conversazioni su argomenti sensibili, e va ricordato che su Whatsapp, diversamente che su Signal, i membri di un gruppo sono visibili ai partecipanti, agli aggressori informatici e a chiunque abbia un mandato legale.
Se siete utenti comuni mortali, c’è uno scenario molto più plausibile che potrebbe riguardarvi facilmente. Se il gruppo WhatsApp conta molti membri, è facile che l’annuncio dell’arrivo di un nuovo membro non venga notato dagli altri perché è una delle tante notifiche generate dal traffico di messaggi del gruppo. Un amministratore malvagio, pettegolo, colluso o anche in questo caso costretto a collaborare con gli inquirenti potrebbe quindi facilmente aggiungere a un gruppo un membro in più senza che se ne accorga nessuno e permettergli di monitorare l’intero flusso di messaggi del gruppo e tracciare in dettaglio i rapporti tra i partecipanti.
Questa è in effetti una tecnica diffusa di inchiesta giornalistica e di polizia e viene usata anche per raccogliere pettegolezzi e dicerie: è semplice ed elegante e non richiede tentativi di scardinare la crittografia di WhatsApp. Il muro di cinta della crittografia non serve a nulla se la talpa o il sorvegliante o il portinaio pettegolo stanno all’interno di quel muro.
I ricercatori che hanno documentato queste falle di WhatsApp le hanno segnalate all’azienda che gestisce WhatsApp, che ha risposto dicendo che apprezza il loro lavoro e ha ribadito che ogni membro viene notificato quando si unisce un nuovo membro a un gruppo e che è possibile attivare ulteriori notifiche di sicurezza che avvisano se ci sono state variazioni nei codici di sicurezza degli interlocutori. L’azienda ha aggiunto che introduce continuamente nuovi strati protettivi.
Sia come sia, il rischio che la notifica del membro infiltrato passi inosservata nel mare di notifiche nel quale siamo quotidianamente sommersi rimane alto. Difendersi dagli intrusi spetta insomma a noi utenti, che dovremmo controllare una per una le notifiche di nuovi membri e soprattutto verificare le identità di quei membri.
A volte gli intrusi, infatti, entrano per errore, e addirittura senza volerlo. Lo sa bene Mike Waltz, che a marzo scorso, quando era consigliere per la sicurezza nazionale dell’amministrazione Trump, ha creato una chat di gruppo su Signal, l’ha usata per discutere dettagli delle imminenti operazioni militari nello Yemen insieme ad altri esponenti di altissimo livello della sicurezza nazionale statunitense, e non si è reso conto di aver aggiunto per errore al gruppo anche un giornalista, Jeffrey Goldberg, che quindi è venuto a conoscenza di informazioni estremamente sensibili, compreso il nome di un agente della CIA, e ha potuto documentare giornalisticamente non solo l’approccio dilettantesco alla sicurezza di Waltz e degli altri funzionari ma anche le loro parole di disprezzo nei confronti degli alleati europei [Wikipedia].
Come è stato possibile un disastro del genere? Secondo le indagini interne, Mike Waltz avrebbe salvato per errore il numero di telefono del giornalista nella scheda della propria rubrica telefonica dedicata al portavoce della Casa Bianca Brian Hughes, e poi avrebbe aggiunto alla chat supersegreta quello che pensava fosse appunto il portavoce. Ma l’errore fondamentale, a monte, è stato l’uso di un’applicazione non approvata dal Pentagono per discutere piani militari delicatissimi, e soprattutto usarne una versione particolare modificata, che è stata analizzata dagli esperti esterni al governo statunitense e ha rivelato ulteriori, interessanti problemi di sicurezza che è riduttivo definire imbarazzanti. Ma questa è un’altra storia, per un’altra puntata.
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
Scienziati creano un nuovo colore, ma è visibile solo puntandosi uno speciale raggio laser negli occhi (non fatelo!) (BoingBoing / The Guardian / Science Advances). Ricercatori della University of California a Berkeley hanno sparato impulsi laser nei propri occhi per stimolare specifiche cellule della retina, rivelando una sorta di tonalità blu-verde che hanno chiamato “olo”. Gli occhi umani hanno tre tipi di coni, sensibili a lunghezze d’onda lunghe, medie e corte della luce (fondamentalmente le gamme del rosso, del verde e del blu). Questi ricercatori hanno trovato il modo di stimolare tramite laser solo i coni sensibili alle lunghezze d’onda medie, producendo una macchia di colore nel campo visivo grande circa il doppio della luna piena. Questo colore va oltre la gamma naturale perché appunto sono stimolati quasi esclusivamente i coni medi, creando uno stato che la luce naturale non può raggiungere. Il nome “olo“ deriva dal binario 010, a indicare che viene attivato solo uno dei tre tipi di coni (quello per le frequenze medie).
Anniversari di oggi: morte di Perry Como e della nascita di Burt Bacharach, rispettivamente cantante e autore della celeberrima Magic Moments; nascita di Katharine Hepburn (tomba trovata grazie a Findagrave); morte di Mia Martini; uscita del film Pulp Fiction.
Il paradosso del compleanno: sembra impossibile, eppure basta un gruppo di 23 persone per avere il 50% di probabilità che due di esse condividano la data del compleanno. Con 30 persone la probabilità sale al 70% e con 50 tocca addirittura il 97%.
Prendendo il calcio delle ossa di una persona per farne gessetti, quanto si potrebbe scrivere? Secondo questo video su YouTube, che non so quali fonti abbia usato, se estraeste il calcio dalle ossa di un dito della vostra mano potreste usarlo per scrivere il vostro nome 40 volte. Se estraeste l’osso più grande del vostro corpo, il femore, potreste disegnare una linea lunga 800 metri. E se estraeste tutto il vostro scheletro e lo macinaste fino a ottenere un gigantesco gessetto? Potreste disegnare una linea di 21 km. Personalmente consiglierei di continuare a usare i normali gessetti da marciapiede (BoingBoing).
La ragazza con la mano bionica comandabile a distanza. Una diciannovenne britannica, Tilly Lockey, grazie alla Open Bionics ha mani bioniche che continuano a funzionare anche quando non sono attaccate al corpo, sono completamente impermeabili e funzionano tramite sensori wireless che leggono i segnali muscolari, senza bisogno di chip cerebrali (BoingBoing).
È andata in onda lunedì 5 alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile sul sito della RSI oppure nell’embed qui sotto.
Abbiamo parlato di Starmus, il congresso di scienziati e ricercatori svoltosi alle Canarie; del MetGala 2025; dell’anniversario della morte di Napoleone Bonaparte, con le teorie complottiste sul motivo della sua morte e sulla storia del suo sarcofago a matrioska e i fatti storici legati alle tappezzerie all’arsenico usate in epoca vittoriana; della poesia Il Cinque Maggio dedicata a Napoleone da Alessandro Manzoni; dell’atleta Simone Biles; dell’espressione britannica plumber’s cleavage (“scollatura dell’idraulico”); e del Fu Mattia Pascal di Luigi Pirandello.
Abbiamo la data per l’evento che era in programma per il 10 maggio e adesso è previsto per il 31 maggio (tutto il resto è invariato). Vi aspettiamo numerosi!
Questo è il testo della puntata del 5 maggio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
È passato da pochi giorni il trentaduesimo anniversario della nascita formale del Web, ossia di Internet come la conosciamo oggi. Rispetto all’idea originale, però, sono cambiate tante cose, non tutte per il meglio.
Questa è la storia di come è nato il Web, di cosa è andato storto e di come rimediare, con una lista di “No” da usare come strumento correttivo per ricordare a chi progetta siti, e a noi che li usiamo, quali sono i princìpi ispiratori di un servizio straordinario come l’Internet multimediale che ci avvolge e circonda oggi, e a volte ci soffoca un po’ troppo con il suo abbraccio commerciale.
Benvenuti alla puntata del 5 maggio 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Siamo nel 1993. È il 30 aprile. A Ginevra, un timbro rosso della Divisione delle Finanze dell’Organizzazione Europea per la Ricerca Nucleare, quella che oggi chiamiamo comunemente CERN, si imprime su un singolo foglio di carta firmato dal direttore della ricerca e dal direttore dell’amministrazione.
Quel foglio contiene una dichiarazione molto semplice, ma di portata letteralmente planetaria: dice che tre software sviluppati al CERN diventano di pubblico dominio e sono quindi liberamente utilizzabili, copiabili, modificabili e ridistribuibili da chiunque. Quei tre software sono gli elementi fondamentali del Web che usiamo oggi, inventato appunto da un dipendente del CERN, Tim Berners-Lee, quattro anni prima, insieme a Robert Cailliau.
Internet esisteva già, fin dalla fine degli anni Sessanta, ma soltanto in forma testuale elementare. L’invenzione di Berners-Lee e Cailliau la trasformava, permettendo di collegare fra loro pagine differenti con dei link cliccabili, creando una ragnatela di documenti interconnessi (per questo si chiama Web, ossia appunto “ragnatela” in inglese) e consentendo di includere in una stessa pagina testo, immagini, video e suoni. Una rivoluzione oggi un po’ dimenticata, visto che sono passati tre decenni abbondanti, e basata su un ideale di apertura e di libero accesso che da allora si è perso per strada.
Oggi siamo abituati a un’Internet commerciale, ma va ricordato che inizialmente Internet era un servizio dedicato alla comunicazione tra membri di istituzioni accademiche, basato su standard aperti, pensato per abbattere le barriere e le incompatibilità fra i computer e i sistemi operativi differenti e facilitare la condivisione del sapere.
Adesso, invece, le barriere vengono costruite appositamente: per esempio, invece della mail, che è aperta a tutti, non è monopolio di nessuno e funziona senza obbligare nessuno a installare un unico, specifico programma, si usano sempre di più i sistemi di messaggistica commerciali, come per esempio WhatsApp, che appartengono a una singola azienda, funzionano soltanto con l’app gestita e aggiornata da quell’azienda e sono incompatibili tra loro.
Ci sono alternative non commerciali, basate su standard aperti, come Mastodon, che conta alcuni milioni di utenti, ma la stragrande maggioranza delle persone è insediata da tempo su WhatsApp e simili e non può traslocare perché se lo facesse perderebbe tutti i contatti che ha, ed è quindi prigioniera e obbligata a cedere tutti i dati personali che il gestore di quella app pretende di volta in volta in cambio del proprio servizio.
La misura di quanto ci siamo allontanati da quell’ideale di apertura e compatibilità di trentadue anni fa è evidente nell’interazione di tutti i giorni con qualunque sito Web: invece di poter semplicemente consultare le informazioni che desideriamo, veniamo assillati da richieste di login, cookie, creazione di account, identificazione di scritte distorte, e così via. È talmente onnipresente che molti ormai la considerano la normalità, una scomodità necessaria e inevitabile, e anche chi progetta i siti Web pensa che sia giusto fare così, senza alternative.
Ma immaginate per un momento come vi sentireste se un negozio fisico si comportasse come un sito Web tipico di oggi. Volete comperare un paio di calzini? Ancora prima di varcare la soglia del negozio dovrete dare un indirizzo di mail e creare un account, anche se non siete sicuri di voler comperare nulla e probabilmente non metterete mai più piede in quel negozio. E dovete creare una password, ma non una password qualsiasi usa e getta: una che abbia un tot di caratteri maiuscoli e minuscoli, di cifre e di caratteri di punteggiatura.
E poi dovete ricordarvela, altrimenti la prossima volta dovrete rifare tutto da capo. E adesso dovete guardare una griglia di immagini microscopiche di strade e cliccare solo su quelle che mostrano strisce pedonali e non su quelle che raffigurano scale o cancellate; e guai a sbagliare. E tutto questo perché volevate soltanto comprare un paio di calzini.
La frustrazione della situazione attuale del Web è riassunta molto bene da un elenco che circola online in varie versioni in questo periodo. Una delle più gustose è quella pubblicata su Mastodon da Max Leibman [link] e ampliata con gusto e sarcasmo da molti commentatori.
Ve la traduco e adatto in italiano per comodità e perché nella sua brevità è sia un manifesto di protesta per noi utenti, sia un promemoria di cosa non fare per chi progetta app e siti Internet e non vuole irritare i propri potenziali clienti o lettori.
No, grazie, non desidero installare la tua app.
No, grazie, non voglio che la tua app si avvii da sola quando avvio il mio telefono o computer.
No, grazie, non voglio che tu metta un’icona della tua app sullo schermo del mio computer.
No, non voglio iscrivermi alla tua newsletter e non voglio ricevere mail da te.
No, grazie, non voglio nemmeno ricevere notifiche sulle ultime meravigliose novità della tua azienda.
No, grazie, non voglio lasciare un commento che racconti come è stata la mia esperienza nell’usare il tuo sito.
No, non voglio aprire un account.
No, non voglio aprire un account usando il mio accesso a Google o a un altro servizio, così potrete scambiarvi dati su di me.
No, non desidero entrare nel tuo sito con un account “per avere un’esperienza più personalizzata”.
No, non voglio darti pieno accesso alla mia rubrica dei contatti per poterli tempestare di annunci su quanto siano belli i tuoi prodotti.
No, non voglio che tu legga le mie foto o i miei messaggi.
No, non voglio che tu possa accedere ai miei file, alla mia fotocamera, al mio microfono o al mio altoparlante.
E no, assolutamente non voglio che tu mi tracci con la localizzazione.
No, non voglio cliccare un “Lo faccio dopo” o “Non adesso”. Se ho detto di no, è no. “No” non vuol dire “magari più tardi”.
No, non voglio che tu faccia partire automaticamente il video incorporato nella tua pagina mentre la sto leggendo. Sto leggendo, non posso guardare un video.
No, non desidero i tuoi “cookie facoltativi”. Se sono facoltativi, non dovresti neanche chiedermeli.
No, non voglio lasciarti un giudizio da una a cinque stelline da associare alla mia identità online.
No, non voglio postare automaticamente un messaggio sui social network dicendo a tutti i miei amici che ho acquistato da te un prodotto.
No, non voglio darti il mio numero di telefono così mi potrai mandare offerte via SMS.
No, non voglio usare il mio numero di telefono come numero di iscrizione al tuo sito e non voglio aggiungerlo al mio account “per maggiore sicurezza”, perché sappiamo benissimo entrambi che la sicurezza non c’entra niente.
No, non voglio fare a meno della bolletta cartacea o dello scontrino, che poi devo stampare io a spese mie.
No, non voglio cliccare su “Mi piace” o “Iscriviti al mio canale”.
E no, non voglio che una cosiddetta “intelligenza artificiale” cerchi di farmi assistenza quando chiedo aiuto o che ascolti il mio consulto medico e scriva al posto tuo gli appunti che riguardano la mia salute o i miei acquisti.
La ragione per cui così tanti siti ignorano queste semplici richieste degli utenti di essere lasciati in pace è la raccolta massiccia di dati di marketing sfruttabili e rivendibili. Il motivo per cui insistono a farvi installare la loro app invece di visitare il loro sito è che le app tipicamente danno loro accesso a molti più dati su di voi o sulle vostre attività. La loro insistenza nel farvi scrivere recensioni e commenti serve per farvi spendere tempo a loro vantaggio e per il loro profitto e per avere contenuti sui quali addestrare le loro intelligenze artificiali, non per darvi la possibilità di esprimere costruttivamente la vostra opinione.
In altre parole, quella lunga litania di “No” serve a ristabilire il giusto equilibrio fra cliente e venditore. Il cliente non deve lavorare gratis per il venditore; non è al suo servizio e non è a sua volta un prodotto da vendere.
Se vi siete riconosciuti in qualche punto di quest’elenco di rifiuti garbati ma fermi, avete colto l’essenza del problema: è ora di riprendere l’abitudine di dire “no” a questa pressione crescente. Anche quando la richiesta è insistente e irritante. E se cliccare su “No” significa non poter usare un servizio, un sito o un negozio, non vuol dire che è giunto il momento di cliccare su “Sì”. È giunto il momento di trovare un’alternativa.
E se siete dall’altra parte della barricata, cioè dalla parte di chi crea siti, è giunto il momento di spiccare e distinguervi creando quell’alternativa, se non c’è già. Buon lavoro!
Ci hanno comunicato oggi che la conferenza del 10 maggio a Como dovrà essere rinviata ad altra data (per lo spostamento della partita del Como). Vi terremo informati appena possibile.
Aggiornamento (2025/05/07): la nuova data è il 31 maggio.
L’artista belga Paul Van Hoeydonck, autore di una statuetta che è considerata l’unica opera d’arte lasciata sulla Luna durante una delle missioni Apollo, è morto sabato all’età di 99 anni. Lo ha annunciato la sua famiglia sulla sua pagina Facebook.
Nato l’8 ottobre 1925 ad Anversa, Van Hoeydonck è stato un artista prolifico, attivo nella scultura, nella pittura, nel disegno, nel collage e nella grafica. Ad aumentare la sua fama in tutto il mondo fu però una piccola statuetta alta 8,5 centimetri che rappresenta una figura stilizzata di un astronauta, denominata “Fallen Astronaut”(“Astronauta caduto”) e lasciata sulla Luna durante la missione Apollo 15 il 2 agosto 1971 dagli astronauti David Scott e James Irwin come tributo ai colleghi americani e sovietici caduti in missione o deceduti a causa di incidenti aerei o stradali.
La statuetta fu commissionata a Van Hoeydonck direttamente da David Scott, comandante di Apollo 15, durante un incontro ad una cena. All’artista fu richiesto di creare una piccola scultura per commemorare i 14 astronauti e cosmonauti periti fino ad allora in missioni spaziali e non solo e per celebrare il progresso dell’esplorazione spaziale non solo lunare ma nell’intero Sistema Solare.
Siccome la scultura avrebbe dovuto viaggiare nello spazio ed essere poi esposta per sempre alle condizioni estreme della superficie lunare, Van Hoeydonck ricevette precise istruzioni sulle dimensioni, sul peso e sul materiale da utilizzare per la sua realizzazione. Per soddisfare i requisiti di leggerezza e robustezza, l’artista belga scelse come materiale l’alluminio, che ha il vantaggio di resistere alle forti escursioni termiche della superficie lunare senza il rischio di deformarsi nel tempo. Gli vennero dati anche alcuni suggerimenti sul soggetto che avrebbe dovuto rappresentare: la figura non avrebbe dovuto essere identificabile né come sesso né come etnia. Sia l’artista che il committente, in questo caso l’equipaggio di Apollo 15, concordarono che per evitare ogni futura speculazione commerciale del progetto artistico la statuetta non avrebbe dovuto riportare la firma dell’artista e che lo stesso nome dello scultore non avrebbe dovuto essere divulgato al pubblico.
La missione di Apollo 15, quarto sbarco umano sulla Luna, partì regolarmente dalla rampa di lancio 39-A di Cape Kennedy il 26 luglio 1971 con a bordo l’equipaggio costituito da David Scott, James Irwin e Alfred Worden. Scott e Irwin, al termine della loro terza ed ultima esplorazione ai piedi degli Appennini lunari mentre Worden li attendeva in orbita, depositarono il “Fallen Astronaut” non lontano da dove parcheggiarono il loro veicolo elettrico prima di rientrare a bordo del modulo lunare “Falcon”. Lo collocarono sul suolo selenico insieme ad una targa metallica con i nomi, in ordine rigorosamente alfabetico, di 14 astronauti deceduti, otto statunitensi e sei sovietici.
La statuetta “Fallen Astronaut” insieme alla targa commemorativa (foto AS15-88-11894).
Solo dopo il rientro a terra dei tre di Apollo 15 l’opinione pubblica venne a conoscenza della deposizione sulla superficie lunare della statuetta, durante la conferenza stampa post-volo, ma non fu menzionato il nome dell’artista, tenuto intenzionalmente segreto per scelta dell’equipaggio. Anche quando il prestigioso National Air and Space Museum di Washington espresse il desiderio di avere una copia dell’opera per esporla ai visitatori, dovette farne richiesta tramite gli astronauti. Ad aprile 1972 Van Hoeydonck donò al museo una replica della scultura, esposta ancora oggi assieme ad una copia della targa con i nomi dei quattordici astronauti deceduti.
Il suo nome fu rivelato al mondo il 16 aprile 1972 dallo storico cronista statunitense Walter Cronkite, durante la diretta televisiva della partenza della missione lunare successiva, Apollo 16, quando Cronkite ospitò in studio Van Hoeydonck.
L’artista belga Van Hoeydonck ritratto con in mano il “Fallen Astronaut”.
Insieme alla Dama del Maniero sto cercando, senza successo, di identificare da che film provengono queste due scene (o questi due vividissimi falsi ricordi?):
Film in bianco e nero. Siamo in tribunale, da qualche parte negli Stati Uniti, fra gli anni Cinquanta e Sessanta del secolo scorso. Qualcuno, forse uno degli avvocati, sta interrogando un testimone. Si avvicina al banco dei giurati e con il dito disegna, sul corrimano di legno che lo separa dai giurati, un immaginario pulsante che, se premuto, farebbe scomparire in modo indolore e senza conseguenze legali una persona. Con le sue brillanti argomentazioni e provocazioni, alla fine induce l’interrogato a premere entusiasticamente quel pulsante come se fosse una liberazione.
Commedia a colori, ambientata a New York. Un uomo è esasperato dal rumore di un infernale macchinario di cantiere che, nel doppiaggio italiano, fa il verso “glopita-glopita”. Il verso viene citato più volte nel corso del film, diventando un tormentone, e a un certo punto viene mostrato il macchinario, che effettivamente fa un suono quasi umano, comicissimo, che pare proprio “glopita-glopita”.
Inutile dire che ho già cercato in Google e consultato le varie intelligenze artificiali, dalle quali ho ottenuto soltanto risposte totalmente idiote, per cui mi appello all’intelligenza umana.
Grazie!
2025/05/04 21:30
Il secondo quesito è stato risolto brillantemente da vari utenti su Mastodon, dove ho lanciato l’appello: il primo a rispondere correttamente è stato AleBinni, che ha anche linkato uno spezzone della scena esatta. Il film è How to Murder Your Wife, Come uccidere vostra mogliein italiano, uscito nel 1965 e diretto da Richard Quine con Jack Lemmon, Virna Lisi e Terry-Thomas.
Da questa risoluzione salta fuori che non si tratta di due film, ma di uno solo: la scena del pulsante immaginario è infatti tratta dallo stesso film. Eccola:
Rivedendolo oggi, il film è terribilmente, imbarazzantemente sessista e offensivo, anche se lo si interpreta come satira dell’ipocrisia maschile. Avevo due anni quando è uscito, e devo averlo visto in TV anni dopo. Il clima sociale di quegli anni era così. Mi chiedo come siamo sopravvissuti (maluccio, direi).
In ogni caso, grazie! Avete letteralmente sbloccato un ricordo che temevo di essermi inventato.
16 maggio – TORINO (Salone del Libro) – Centro congressi Lingotto, Sala Madrid dalle 13.45 alle 14.45 circa: presentazione della nuova collana CICAP “Think Deep“. Saranno presenti: Roberto Paura, Giuseppe Stilo e Sofia Lincos, Paolo Attivissimo e Lorenzo Montali (in rappresentanza del Cicap). Modera Elisa Palazzi. Seguirà firmacopie.
31 maggio (spostato dal 10 maggio) – COMO – Yacht Club (viale Puecher 8) dalle 9 alle 13: Convegno “Fake News e Social“. Relatori: Lorenzo Montali, Paolo Attivissimo, Federico Pennestrì, Marco Valle, Mario Guidotti. Ingresso libero, posti limitati. Per iscrizioni: info@premiocittadicomo.it
È andata in onda ieri mattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera, in una versione un po’ insolita perché mi sono collegato dalle Canarie via Zoom e ho raccontato l’atmosfera del festival di scienza e musica Starmus e ho portato alcuni spezzoni di interviste ai protagonisti (ringrazio Thomas Villa per la condivisione delle clip audio).
Pochi giorni fa ho ricevuto questa mail, che riporto pari pari omettendo solo il nome del mittente:
CARO PAOLO,TI RICORDI DI ME? IO HO UN GROSSO PROBLEMA CON POBOX.COM POBOX E’ STATA INGLOBATA DA FASTMAIL E ORA NON SO COME FARE.
MI PUOI AIUTARE? MI FARESTI UNA CORTESIA.
GRAZIE.
La mia risposta:
Buongiorno G*******,
mi spiace, ma non ho assolutamente tempo di fare assistenza informatica a nessuno.
Ti consiglio di trovare una persona sul posto che ti possa aiutare.
Ciao,
Paolo
La garbata e serena risposta:
PAOLO ATTIVISSIMO,
DEVO DIRTI CHE SEI UN BEL L’EGOISTA! IO NON-HO NESSUNO CHE MI AIUTA, NEMMENO UN TECNICO QUI A SENIGALLIA DI QUELLI CHE FANNO ANCHE LE CONFIGURAZIONI DI POSTA ELETTRONICA, NEMMENO SE LO PAGO A PESO D’ORO! NESSUN TECNICO QUI’ A SENIGALLIA SI OCCUPA DI FARE CONFIGURAZIONI DI POSTA ELETTRONICA! GENTE EGOISTA COME TE MI FA PROPRIO SCHIFO! SPERO CHE TI VENGA QUALCHE BRUTTO MALE, SPERO CHE TI POSSA VENIRE UN TUMORE MALIGNO DEI PEGGIORI! DI QUELLI CHE NON PERDONANO! LA STESSA COSA AUGURO A QUEI TECNICI CHE SI RIFIUTANO DI FARE LE CONFIGURAZIONI DI POSTA ELETTRONICA ANCHE PAGANDOLI PROFUMATAMENTE!
I TUMORI MALIGNI VENGONO A MOLTI E SPERO CHE PRESTO POSSA VENIRE ANCHE A TE. TI AUGURO LE PEGGIORI DISGRAZIE NELLA TUA FAMIGLIA! I MIEI GENITORI SONO MORTI DIVERSI ANNI FA E NON-HO MOLTO DA PERDERE! SONO RIMASTO SOLO COME UN CANE. HO SOLO MIA SORELLA CHE MI AIUTA PER QUELLO CHE PUO’. ESSA PURTROPPO NON-E’ UN TECNICO, MA UN MEDICO!
Questo è il programma di oggi, quarto e ultimo giorno di questa festa di scienza e musica. Trovate i dettagli sul sito dell’evento, Starmus.com.
Kip Thorne (fisico e premio Nobel) e Lia Halloran (pittrice e fotografa) The Warped Side of the Universe. Una lezione pittorica e scientifica sulle fluttuazioni quantistiche del vuoto come mattoni costitutivi dell’Universo e come strumenti per misurare le onde gravitazionali e altri fenomeni incredibilmente fini. Inevitabile e potente il grido di allarme di Thorne per l’attacco senza precedenti alla scienza di Donald Trump e Elon Musk negli Stati Uniti.
Kip Thorne e Lia Halloran.
Marie Edmonds (Vulcanologa e petrologa) Volcano: Friend or Foe? Gli effetti negativi e positivi dei vulcani, come supporto alla vita e contenimento dei cambiamenti climatici.
Marie Edmonds.
Matt Mountain (astrofisico) Expanding Perspectives: The Power of Astronomy and Future Telescopes to Change Our World. Affascinante riepilogo delle scoperte rivoluzionarie permesse dai telescopi. Quando sarà possibile osservare le superfici di pianeti? Se la fisica quantistica viene applicata ai grandi telescopi, presto.
Kurt Wüthrich (chimico/biofisico, premio Nobel) Dark Matter in the Human Genome, RNA and Proteome. L’incredibile complessità del mondo delle proteine, raccontato con un occhio all’intelligenza artificiale e uno all’idea di “materia oscura” proteica.
Mario Livio(astrofisico, autore di bestseller) The Quest for Cosmic Life.
Donna Strickland(fisico e premio Nobel) Laser Acceleration for Medical Treatments.
George Smoot(astrofisico e premio Nobel) Stem Cell Therapy Centre Automation and Safety.
Jill Tarter (astrofisica, pioniera della ricerca di vita extraterrestre) Search for Extraterrestrial Intelligence.
Pablo Álvarez(astronauta ESA e ingegnere aerospaziale) Roads To Cosmos.
Jim Bell(scienziato planetario, ex presidente della US Planetary Society) Finding Life on Other Worlds: This Century’s Exploration Imperative.
Questo è il testo della puntata del 28 aprile 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: voce di Schmidt che dice “[…] people are planning 10 gigawatt data centers […], an average nuclear power plant in the United States is one gigawatt. How many nuclear power plants can we make in one year while we’re planning this 10 gigawatt data center? […] data centers will require an additional 29 gigawatts of power by 2027 and 67 more gigawatts by 2030”][Trascrizione integrale su Techpolicy.press; video su YouTube; spezzone dell’intervento su Instagram]
Questa è la voce di Eric Schmidt, ex amministratore delegato di Google, durante un’audizione davanti a una commissione per l’energia della Camera dei rappresentanti degli Stati Uniti, il 9 aprile scorso. Schmidt spiega che sono in corso di progettazione dei data center, vale a dire dei centri di calcolo per supportare l’intelligenza artificiale, che consumeranno 10 gigawatt ciascuno, ossia l’equivalente di dieci centrali nucleari. Il fabbisogno energetico stimato della IA, continua Schmidt, è di 29 gigawatt entro il 2027 e di altri 67 entro il 2030.
La sua domanda su quante centrali nucleari si possano costruire ogni anno per placare questa fame di energia è ovviamente abbastanza retorica, ma il suo intervento solleva una questione molto concreta. Quanta energia che servirebbe altrove stiamo bruciando per l’intelligenza artificiale? E di preciso, cosa stiamo ottenendo in cambio concretamente? Siamo sicuri che ne valga veramente la pena? Perché accanto a risultati interessanti e positivi in alcune nicchie, continuano ad accumularsi gli esempi di stupidità asinina di questa tecnologia e di figuracce da parte delle aziende che la adottano con eccessiva euforia.
Eppure i grandi nomi del settore informatico insistono a includere a forza la IA in tutti i loro prodotti, da Google a WhatsApp a Word, anche se gli utenti non l’hanno chiesta e in alcuni casi proprio non la vogliono, come è appena avvenuto appunto per WhatsApp.
Questa è la storia di alcuni di questi esempi e delle tecniche concrete che si possono adottare per resistere a un’avanzata tecnologica che per alcuni esperti è un’imposizione invadente e insostenibile.
Benvenuti alla puntata del 28 aprile 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Nella puntata del 24 marzo scorso ho già raccontato alcune delle stupidaggini enunciate con elettronica certezza dalle intelligenze artificiali sulle quali si stanno investendo montagne di miliardi. Ho citato per esempio il fatto che secondo la IA di Google, la trippa è kosher o meno a seconda della religione della mucca dalla quale proviene. Ora gli utenti hanno scoperto un’altra bizzarria fuorviante e ingannevole di questo software: se si chiede a Google il significato di un’espressione o di un modo di dire in inglese, il motore di ricerca spesso risponde mettendo in primo piano una spiegazione completamente falsa, inventata dall’intelligenza artificiale, e solo dopo elenca i normali risultati di ricerca.
Ma l’utente medio non ha modo di sapere che la spiegazione è totalmente sbagliata. Si rivolge appunto a Google perché non conosce quel modo di dire e non è un linguista esperto, e quindi tende a fidarsi di quello che Google gli dice. Anche perché glielo dice con enfatica autorevolezza, con tanto di link a fonti, che esistono ma in realtà dicono tutt’altro.
E così secondo Google esisterebbe per esempio in inglese il modo di dire “l’oritteropo abbassa lo sguardo sempre per primo”, che stando alla IA significherebbe che una persona di un certo tipo tende ad arrendersi facilmente se viene sfidata. Sempre Google afferma che in inglese si dice “non puoi leccare due volte un tasso” per indicare che non si può ingannare due volte la stessa persona, e si dice “c’è sempre una mangusta in ogni aula di tribunale” per riferirsi a una strategia legale adottata da alcuni avvocati [Bluesky]. È tutto falso; è tutta un’allucinazione generata dal modo in cui funziona l’intelligenza artificiale.
Un altro modo di dire inglese che non esiste se non nell’energivora fantasia di silicio della IA di Google è “quando l’ape ronza, le fragole cadono”. So che non esiste perché l’ho inventato io pochi minuti fa per questo podcast. Ma se chiedo lumi all’intelligenza artificiale di Google questa frase è un saying, ossia un modo di dire esistente e usato, e rappresenterebbe “l’importanza delle api nell’impollinazione e nella successiva maturazione dei frutti come appunto le fragole”. Lasciamo stare il fatto che la fragola non è un frutto nel senso botanico del termine (se volete sapere perché, la spiegazione è su Wikipedia): quello che conta è che l’utente si rivolge a Google per avere informazioni e invece ne ottiene sistematicamente una bugia che rischia di non saper riconoscere come tale.
Ma quello che conta ancora di più è che quell’utente ora si ritrova in cima ai risultati di ricerca una risposta generata dalla IA, che la voglia o no. E quindi ogni ricerca fatta su Google consuma molta più energia di prima.
È difficile dire quanta, perché ci sono tantissime variabili da considerare, ma il CEO di OpenAI, Sam Altman, ha scritto semiseriamente su X che già solo dire “per favore” e “grazie” a ChatGPT costa alla sua azienda decine di milioni di dollari in energia elettrica per elaborare le risposte a questi gesti di cortesia. Secondo una ricerca del Washington Post, far generare a una IA una cinquantina di mail lunghe 100 parole ciascuna consuma circa 7,5 kWh: quanto basta per fare grosso modo quaranta chilometri in auto elettrica.
L’unico modo pratico per evitare di contribuire a questo spreco di energia indesiderato e spesso inutile è usare un motore di ricerca alternativo privo di intelligenza artificiale o nel quale sia possibile disattivare le funzioni basate su IA, come per esempio DuckDuckGo [istruzioni; link diretto alle impostazioni].
In questo caso, insomma, l’intelligenza artificiale fornisce un disservizio, inganna gli utenti e spreca energia. Ma può anche fare molto di più: per esempio può danneggiare l’azienda che la usa. E se l’azienda in questione è una di quelle legate a doppio filo all’intelligenza artificiale, l’ironia della situazione diventa particolarmente vistosa.
Cursor.com è una delle principali aziende che sta cavalcando la popolarità dell’intelligenza artificiale come assistente per la scrittura rapida di software. Una decina di giorni fa, uno dei clienti di Cursor.com, uno sviluppatore di software, ha notato che non era più possibile collegarsi al sito dell’azienda da più di un dispositivo, cosa che invece prima si poteva fare. Gli sviluppatori lo fanno spessissimo per necessità di lavoro.
Il cliente ha contattato l’assistenza clienti di Cursor.com, e un assistente che si faceva chiamare Sam gli ha risposto via mail che questa situazione era normale e prevista, perché era dettata da una nuova regola legata a esigenze di sicurezza e ora serviva un abbonamento distinto per ciascun dispositivo. Ma la regola non esisteva: se l’era inventata Sam, che come avrete sospettato è un’intelligenza artificiale. Una IA che fra l’altro non dichiarava di essere una macchina e si spacciava per una persona.
Il cliente ha segnalato inizialmente la novità apparente su Reddit, e così molti altri utenti sviluppatori di Cursor.com, indignati per la grave riduzione dell’usabilità del software comportata da questa regola, hanno disdetto i loro abbonamenti, annunciando pubblicamente la loro decisione e spargendo la voce.
Ci sono volute tre ore prima che qualcuno di Cursor.com, una persona in carne e ossa, intervenisse e spiegasse che la nuova regola non esisteva e che si trattava di “una risposta inesatta data da un bot di supporto pilotato dalla IA”. Uno dei cofondatori dell’azienda ha chiesto pubblicamente scusa e il cliente che aveva segnalato inizialmente la situazione è stato rimborsato. Ma resta il fatto che Cursor.com non aveva avvisato gli utenti che l’assistenza clienti di primo livello era fatta da un’intelligenza artificiale e anzi dava alla sua IA un nome di persona. Anche qui, l’intelligenza artificiale veniva imposta agli utenti senza ma e senza se.
È particolarmente ironico che un’azienda che vive di intelligenza artificiale e che fa soldi vendendo strumenti di miglioramento della produttività basati su IA sia stata tradita dal proprio eccesso di fiducia in questa tecnologia, che ha fatto ribellare i suoi utenti chiave, esperti di informatica. E la lezione di fondo, per qualunque azienda, è che esporre verso i clienti un chatbot che genera risposte usando l’intelligenza artificiale comporta un rischio reputazionale altissimo; prima o poi quella IA avrà una cosiddetta allucinazione e produrrà una risposta falsa e dannosa [Ars Technica].
E i campioni in fatto di esposizione al pubblico di intelligenze artificiali sono i motori di ricerca come Google e i servizi conversazionali di IA come ChatGPT, Claude o Perplexity. O perlomeno lo sono stati fino a pochi giorni fa, quando sono stati spodestati dall’introduzione di un servizio di intelligenza artificiale in WhatsApp e altre applicazioni. Nelle prossime settimane, circa due miliardi e mezzo di persone in tutto il mondo si troveranno imposto a forza il servizio di IA di Meta.
Se avete notato un cerchio blu nel vostro WhatsApp, in Facebook Messenger o in Instagram, avete già ricevuto l’intelligenza artificiale di Meta: un chatbot che risponde alle vostre domande usando la IA gestita dall’azienda di Mark Zuckerberg. Come tutte le intelligenze artificiali, genera risposte che possono essere completamente sbagliate ma superficialmente plausibili, e questo Meta lo dice nel lungo messaggio di avviso che compare la prima volta che si avvia Meta AI (si chiama così).
Il problema è che questa intelligenza artificiale di Meta non è disattivabile o rimovibile: è imposta. Certo, Meta dichiara che Meta AI non può leggere le vostre conversazioni, quindi basterebbe ignorarla e far finta che non ci sia. Ma la tentazione è forte, e miliardi di persone che non hanno mai interagito con una IA e non ne conoscono pregi e limiti proveranno a usarla, senza leggere le avvertenze in molti casi, e crederanno che sia attendibile.
Quelle avvertenze, fra l’altro, sconsigliano di “condividere informazioni, anche sensibili, su di te o altre persone che non vuoi che l’IA conservi e utilizzi”, e dicono che “Meta condivide le informazioni con partner selezionati”. E in una mail separata, che moltissimi non leggeranno, Meta avvisa che userà le informazioni pubbliche degli utenti, “come commenti e post dagli account di persone di almeno 18 anni sulla base degli interessi legittimi.”
In altre parole, qualunque conversazione fatta con questa IA, qualunque domanda di natura medica, qualunque richiesta di informazioni su qualunque persona, argomento, prodotto o servizio verrà digerita dalla IA di Meta e venduta ai pubblicitari. Cosa mai potrebbe andare storto? [BBC]
È vero che Meta specifica, sempre nella mail separata, che ogni utente ha il diritto di opporsi all’uso delle sue informazioni. Ma quanti sapranno di questo diritto? E di questi, quanti lo eserciteranno? E soprattutto, ancora una volta, all’utente viene imposto un servizio di intelligenza artificiale potenzialmente ficcanaso e spetta a lui o lei darsi da fare per non esserne fagocitato.
Lo stesso tipo di adozione forzata si vede in Word e Powerpoint e in generale nei prodotti Microsoft: tutti integrano Copilot, la IA dell’azienda, e gli utenti devono arrabattarsi, spesso con modifiche molto delicate e poco ortodosse di Windows, se non vogliono avere tra i piedi l’onnipresente icona di Copilot. Bisogna per esempio modificare delle voci nel Registro oppure adottare una versione particolare di Windows 10 garantita fino al 2032 [The Register].
La domanda di fondo, dopo questa carrellata di esempi, è molto semplice: se l’intelligenza artificiale generalista è davvero un’invenzione così efficace e utile agli utenti come viene detto dai suoi promotori, perché le aziende sentono il bisogno di imporcela invece di lasciare che siamo noi a scegliere di adottarla perché abbiamo visto che funziona?
Ho provato a fare questa domanda a ChatGPT, e la sua risposta è stata particolarmente azzeccata e rivelatrice: “L’adozione forzata dell’IA” dice ChatGPT “non nasce tanto dal fatto che non funziona, ma piuttosto da dinamiche di potere, controllo del mercato, gestione dell’innovazione e tentativi di plasmare le abitudini degli utenti. Ma la vera prova di efficacia dell’IA sarà quando gli utenti vorranno usarla non perché devono, ma perché vogliono.”
So che in realtà sta semplicemente usando le parole chiave della mia domanda per rispondermi in modo appagante. Ma lo sta facendo dannatamente bene. Resistere alle sue lusinghe di instancabile yesman sarà davvero difficile. Prepariamoci.
Domenica è stato un giorno relativamente tranquillo: non ci sono state conferenze, ma i relatori e alcuni ospiti sono stati portati a visitare i grandi telescopi situati sull’isola e hanno partecipato a due tavole rotonde, che però non sono state trasmesse pubblicamente.
In compenso, grazie al collega e amico Thomas Villa ho potuto chiacchierare con Jill Tarter e regalarle una sana risata con la notizia dell’IA di Google che dice che la trippa è kosher a seconda della religione della mucca.
La sera, la Dama e io abbiamo partecipato alla cena di gala, all‘aperto, con tanto di fuochi d’artificio. Stare a tavola con direttori generali di centrali a fusione e donne astronauta è stato surreale e fantastico.
Anche oggi la Dama e io, insieme a tutti i partecipanti al festival di scienza e musica Starmus, ci prepariamo a una scorpacciata di buon cibo locale e di scienza. Stamattina a colazione ci siamo trovati accanto Jill Tarter (l’ispiratrice del film Contact).
La vista dall’hotel Melià La Palma che ospita Starmus. L’isola porta ancora i segni e le cicatrici laviche dell’eruzione del 2021.
Questo è il programma di oggi:
Jane Goodall (etologa, primatologa, fondatrice del Jane Goodall Institute e Messaggera di Pace dell’ONU) Reasons for Hope. Strepitosa e lucida, con una lezione di vita e di umiltà dall’alto dei suoi 91 anni.
Jane Goodall.
Kip Thorne tra il pubblico adesso a Starmus La Palma.
Steven Chu (fisico, premio Nobel) A new approach to carbon capture. Le tecnologie per estrarre la CO2 dall’atmosfera finora si sono rivelate costosissime e inefficienti. Ma ci sono novità importanti sul fronte della riduzione dei costi che le potrebbero rendere praticabili su vasta scala. E c’è anche un materiale innovativo che fa cattura di CO2: il legno, da usare per costruzioni anche di grandi dimensioni e altezza e di lunga durata.
Steven Chu.
Xavier Barcons (astrofisico, direttore generale dell’ESO) Dark Skies and Big Telescopes, we need both. Una relazione piena di sorprese e dati sull’inquinamento luminoso, a volte proveniente da fonti inaspettate, e sulle difficoltà di costruzione e i risultati attesi dei telescopi giganti in corso di realizzazione sulla Terra.
Xavier Barcons, direttore generale dell’ESO.
Costanza Bonadonna (geologa, vulcanologa) Living on a Dynamic Planet: Lessons from the 2021 La Palma Eruption. Resoconto tecnico degli sconvolgimenti causati da una eruzione vulcanica vissuta molto da vicino: quella che ha colpito il luogo in cui ci troviamo. Fa impressione parlarne in un hotel che ha una colata lavica che gli passa accanto e porta ancora le cicatrici dei danni causati dall’eruzione.
Costanza Bonadonna, geologa e vulcanologa.
L’hotel Melià presso il quale si tiene Starmus.
L’hotel è perfettamente fruibile e molto accogliente, ma alcune zone non essenziali sono ancora transennate e rivelano i danni causati dalla discesa inesorabile della lava. Questa è la vista da un angolo del ristorante dell’albergo.
Pietro Barabaschi (fisico, direttore generale di ITER) The Power of Nuclear Fusion: From the Solar Core to Earthly Reactors. Un aggiornamento sulla situazione del reattore a fusione nucleare sperimentale ITER in costruzione in Europa: si stanno posando adesso i primi, giganteschi elementi e si spera di arrivare alle prime accensioni entro pochi anni.
Pietro Barabaschi.
Chris Hadfield (astronauta, ex comandante della ISS) The sky is falling: What to do about space junk? Il punto della situazione sui detriti spaziali, fatto da uno che ha vissuto sulla ISS e ha sentito di persona il picchiettio quotidiano di quei detriti e dei micrometeoroidi contro la superficie esterna della Stazione.
L’astronauta Chris Hadfield.
Kathryn Thornton (fisica, ex astronauta NASA) Intelsat Satellite Rescue in Space. Racconto avvincente di una missione di intercettazione e salvataggio di un satellite nella quale è successo davvero di tutto, compresa una EVA di tre persone non pianificata per agguantare a mano il satellite (con una massa di oltre 4 tonnellate), usando in tre una camera di depressurizzazione e un sistema di comunicazione previsti per gestire al massimo due astronauti e inventando man mano le soluzioni ai problemi che si presentavano continuamente. Avventure spaziali così non se ne fanno più. Chicca: è una Trekker e ha citato Star Trek nella sua presentazione.
L’astronauta Kathryn Thornton.
Anousheh Ansari (ingegnere, imprenditrice, prima donna partecipante privata a missione spaziale) Dreaming Big for the Future of Humanity in Space. L’esperienza personale di una donna che dall’Iran travolto dalla rivoluzione è andata negli Stati Uniti, ha fatto fortuna con la propria competenza ingegneristica e si è conquistata un volo nello spazio fino alla Stazione Spaziale Internazionale, istituendo un premio, l’Ansari X-Prize, per stimolare l’entrata dei privati nelle missioni spaziali con equipaggio. SpaceShip One, il primo veicolo suborbitale privato, è frutto di questo suo premio.
Anousheh Ansari.
Sara García (biotecnologa e astronauta di riserva dell’ESA) Out-of-This-World Medicine. Una vivace e colorita sintesi della medicina spaziale: effetti fisiologici e psicologici della permanenza nello spazio, risorse e protocolli medici attuali e futuri.
Sara Garcia.
Terry Virts (astronauta) View From Above – A survey of photography from the ISS. Questa relazione era prevista dal programma ma è stata saltata senza spiegazioni.
Juan Luis Arsuaga (paleoantropologo) Are the ETs humanoids?Una discussione semiseria e francamente un po’ sconclusionata sulle possibili fisiologie degli extraterrestri capaci di creare tecnologie spaziali.
Tra poco comincia la prima giornata di Starmus, evento di scienza e musica strapieno di premi Nobel e astronauti. Il programma completo è su Starmus.com. L’accesso è completamente gratuito, a patto di essere disposti a recarsi all’isola di La Palma, nelle Canarie (la Dama del Maniero e io lo abbiamo fatto di tasca nostra anche per concederci un momento di vacanza).
Posterò qui foto e sunti degli interventi dei relatori. In questo momento sono alla conferenza stampa di presentazione e dietro di me, seduto tra il pubblico, c’è George Smoot, giusto per dire.
Le autorità locali e Garik Israelian, organizzatore di Starmus (l’ultimo a destra), alla conferenza stampa di presentazione dell’evento.
Al centro, George Smoot. A destra, Michel Mayor.
Questo è il programma delle conferenze scientifiche di oggi, alle quali seguiranno concerti di vari artisti in luoghi sparsi per l’isola:
John Mather (astrofisico, premio Nobel) – From the Big Bang to Quantum Mechanics, Life, and Artificial Intelligence. Una cavalcata da capogiro nelle recentissime scoperte scientifiche in astronomia, astrofisica e IA.
È bellissimo ascoltare una conferenza scientifica all’aperto, con il sereno boato delle onde dell’oceano in sottofondo. Sul palco c’è John Mather.
Nancy Knowlton (Biologa) – Bright Spots: Making a Difference for the Planet in our Age of Rage. Ci sono tante notizie ecologiche deprimenti ed è facile sentirsene sopraffatti. Ma questo porta all’apatia. E se invece provassimo a raccontare con più evidenza i successi? Perché ce ne sono tanti, anche se poco pubblicizzati.
Miguel Alcubierre (fisico teorico) – Faster than the Speed of Light. L’ideatore di un metodo compatibile con le leggi della fisica per viaggiare più veloce della luce spiega il suo metodo. I requisiti sono… piuttosto impegnativi.
Miguel Alcubierre, ideatore di un metodo fisicamente plausibile di viaggiare a velocità maggiori di quella della luce deformando lo spazio.
Chema Alonso (esperto di sicurezza informatica) – Hacking AI. Una carrellata folgorante di tecniche per scavalcare le scadenti salvaguardie delle IA attuali e convincerle a… uccidere Brian May!
Michel Mayor (astrofisico, premio Nobel) – Billions of planets in the Milky Way – 30 years of discoveries and new challenges. Uno degli scopritori dei primi esopianeti presenta lo stato dell’arte della ricerca di pianeti al di fuori del nostro sistema solare. Ora siamo in grado, in alcuni casi, non solo l’esistenza, ma anche la composizione chimica delle loro atmosfere: Mayor spiega come si fa e come faremo nel prossimo futuro.
Jane Lubchenco (scienziata dell’ambiente, ecologa marina, ex Administrator del NOAA) – A New Narrative for the Ocean. Soluzioni concrete per ripensare il ruolo dell’oceano non come vittima ma come motore della soluzione di problemi come fame, inquinamento e cambiamento climatico.
Bernhard Schölkopff (informatico) – Is AI Intelligent? Esempi geniali spiegano che gli attuali grandi modelli linguistici non sono e non possono essere intelligenti perché non gestiscono la causalità.
Valentín Martínez (fisico solare) – Living With a Star: the Good, the Bad and the Ugly. Le tempeste solari hanno effetti spettacolari in termini visivi, ma anche conseguenze disastrose sulle infrastrutture tecnologiche e sui voli spaziali: lo stato dell’arte delle previsioni di meteorologia spaziale, con una bella citazione dell’Evento di Carrington e di altri blackout più recenti causati dai sussulti del Sole.
Rafael Yuste (neuroscienziato) – Can You See a Thought? Neuronal Ensembles as Basic Units of Brain Function. L’ipotesi che i pensieri emergano non al livello dei singoli neuroni del cervello, ma a quello degli insiemi di neuroni, supportata da una dimostrazione di come si può impiantare un’idea o un’immagine in una mente. Per ora è quella di un topolino, ma la speranza (leggermente inquietante) è che si possa applicare alle persone per gestire o curare malattie della mente.
Sul piano personale, è stato un piacere ritrovare qui un amico e una firma ricorrente tra i commentatori di questo blog: Pgc, che lavora qui da vari anni e ha permesso a me e alla Dama del Maniero di vedere l’isola con gli occhi di chi ci abita e non con quelli dei turisti. Il posto è davvero incantevole, molto a misura d’uomo, ed è ovviamente un paradiso per chi ama l’astronomia.
Domani ci sarà un’altra raffica di conferenze scientifiche: cercherò di riassumervele, ma il fiume di informazioni e di eventi è difficile da seguire senza esserne travolti. Sui miei canali social troverete altre foto dell’evento.
Al Centro spaziale di Houston le lancette degli orologi dei numerosissimi tecnici che stanno seguendo la drammatica odissea nello spazio dei tre astronauti di Apollo 13 hanno superato da pochi secondi la mezzanotte. In Italia sono le sette del mattino. È l’inizio di un nuovo giorno, precisamente venerdì 17 aprile 1970, una data da ricordare, perché se tutto andrà bene rimarrà nella memoria come il giorno della felice conclusione del primo salvataggio spaziale della storia.
Dopo aver superato diverse difficoltà in seguito all’esplosione avvenuta all’interno del modulo di servizio nella notte italiana tra il 13 e il 14 aprile (fra cui l’uscita dalla rotta di ritorno verso la Terra e il problema dell’eccessivo tasso di anidride carbonica a bordo del “treno spaziale”), tra circa dodici ore, secondo il piano di volo stabilito dalla NASA, è previsto il rientro sulla Terra di James Lovell, Fred Haise e John Swigert. Ha inizio una lunga attesa, tra paura, preghiera e speranza.
A bordo dell’Apollo “ferito” fa terribilmente freddo. La stanchezza e lo stress nei tre uomini aggiungono brividi. Dal Centro di Controllo consigliano loro di vestirsi il più possibile per ripararsi dalle basse temperature e di assumere qualche pastiglia di dexedrina, uno psicofarmaco stimolante, necessario in questo caso ai tre eroi dello spazio per sentirsi un po’ più in forma in vista della delicata fase del rientro sulla Terra.
La prima pagina de “La Stampa” di venerdì 17 aprile 1970
A 138 ore dalla partenza dalla rampa di lancio di Cape Kennedy, Lovell, Haise e Swigert sganciano il Modulo di Servizio danneggiato, che hanno tenuto agganciato alla propria navicella affinché proteggesse lo scudo termico dagli sbalzi di temperatura dello spazio.
È solo a questo punto che i tre vedono, per la prima volta, la reale entità dei danni che il loro veicolo ha subìto: una fiancata è completamente squarciata e i componenti interni danneggiati sono totalmente esposti. Gli astronauti scattano frettolosamente alcune fotografie, a colori e in bianco e nero, per documentare i danni e consentire ai tecnici a terra di avere maggiori informazioni per tentare di capire cosa è successo esattamente.
Il modulo di servizio di Apollo 13 gravemente danneggiato dallo scoppio
Poco più di tre ore dopo gli astronauti di Apollo 13 si separano anche dal LEM “Aquarius”, trasformato in “scialuppa di salvataggio” dopo l’esplosione nel modulo di servizio: le sue risorse hanno permesso a Lovell, Haise e Swigert di avere energia elettrica e ossigeno sufficienti per il viaggio di ritorno e il suo unico motore principale, insieme ai più piccoli razzi di manovra (RCS), ha permesso di accorciare i tempi del rientro e di inserire il veicolo spaziale nella giusta traiettoria verso la Terra.
Il modulo lunare “Aquarius”, diventato “scialuppa di salvataggio” per i tre di Apollo 13 fotografato dopo il distacco dal modulo di comando “Odyssey”
Alle 18:54 ora italiana, le 11:54 del mattino a Houston, la navicella Apollo, ciò che rimane del gigantesco razzo Saturn V lanciato la sera dell’11 aprile, con nessun sasso lunare a bordo ma con un ben più prezioso carico, quello umano, si tuffa attraverso l’atmosfera.
Alle 19:01 italiane, dopo più di quattro interminabili minuti di silenzio radio, è la voce del comandante Lovell la prima a giungere nelle cuffie dei tecnici di turno della base spaziale texana e ad essere amplificata dalle radio e televisioni in tutto il mondo: “Come mi sentite Houston?”.
“Okay. Perfettamente Odyssey”, gli rispondono quasi gridando. È la conferma che gli astronauti stanno bene.
In tutto il pianeta, pronto ad accogliere nuovamente i tre esploratori cosmici, vi sono scene di pianto, di gioia, di emozione. Sul Pacifico, a sud delle Isole Samoa, il Sole è sorto da appena un’ora quando appaiono tra le nubi i tre grandi paracadute che sostengono il Modulo di Comando.
Alle 19:07 ora italiana, le 12:07 di Houston, la capsula si posa, con un perfetto “splashdown”, sulle acque agitate del Pacifico. Due elicotteri si alzano dalla portaerei di recupero e si dirigono verso la zona dell’ammaraggio. La portaerei Iwo Jima è a soli sette chilometri di distanza. Alcuni uomini-rana si tuffano dagli elicotteri, agganciano il grande collare di galleggiamento alla base di “Odyssey”, poi aprono il portello. Finalmente gli astronauti possono uscire, respirare aria pura, essere riscaldati dai raggi del Sole, respirare l’odore del mare. E’ la fine del dramma.
Sono trascorse 145 ore, 54 minuti e quarantuno secondi dall’inizio del quinto volo umano verso la Luna, un viaggio che avrebbe dovuto portare, per la terza volta in meno di un anno, due uomini a calpestare la superficie del satellite naturale della Terra e si è trasformato invece nell’operazione di salvataggio più spettacolare ed emozionante nella storia dell’umanità.
La bellissima immagine dei tre grandi paracadute spiegati che riportano sul loro pianeta natale i tre eroi di Apollo 13
I tre di Apollo 13 appena sbarcati a bordo della portaerei “Iwo Jima”. Da sinistra Fred Haise, James Lovell e Jack Swigert
La prima pagina de “La Stampa” di sabato 18 aprile 1970
Questo è il testo della puntata del 14 aprile 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
La prossima puntata verrà pubblicata il 28 aprile (lunedì 21 non ci sarà un nuovo podcast).
Va di moda, nel mondo informatico, appoggiarsi alle intelligenze artificiali per creare programmi risparmiando tempo, denaro e risorse umane e mentali. Ma questo nuovo metodo di lavoro porta con sé nuove vulnerabilità, che spalancano le porte ai criminali informatici più sofisticati in maniere inaspettate e poco intuitive ma devastanti.
Per infettare uno smartphone, un tablet o un computer non serve più convincere la vittima a installare un’app di provenienza non controllata, perché il virus può essere già presente nell’app originale. Ce lo ha messo, senza rendersene conto, l’autore dell’app; o meglio, ce lo ha messo l’intelligenza artificiale usata da quell’autore.
Questa è la storia di una di queste nuove vulnerabilità consentite dall’intelligenza artificiale: il cosiddetto slopsquatting, da conoscere anche se non si è sviluppatori o programmatori, per evitare che l’entusiasmo per la IA permetta ai malviventi online di insinuarsi nei processi aziendali eludendo le difese tradizionali.
Benvenuti alla puntata del 14 aprile 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
La sicurezza informatica è una gara fra guardie e ladri, dove quasi sempre i ladri agiscono e le guardie reagiscono. I criminali inventano una tecnica di attacco e gli esperti di sicurezza la studiano per trovare il modo di neutralizzarla. Ma non è sempre così. In questa puntata vi racconto un caso in cui le guardie giocano d’anticipo, in maniera creativa e originale, immaginando un tipo di attacco nuovo e fornendo gli strumenti per bloccarlo ancora prima che i criminali riescano a metterlo in atto.
Chi crea programmi si affida oggi sempre più spesso all’intelligenza artificiale come assistente per la scrittura delle parti più tediose e ripetitive. C’è anche chi si affida totalmente alle IA e genera programmi senza saper programmare, nel cosiddetto vibe coding di cui ho parlato nella puntata del 31 marzo scorso. Copilot, ChatGPT e Cursor sono solo alcuni esempi di questi assistenti.
Ma anche senza arrivare a delegare tutto alle intelligenze artificiali, questo comportamento crea una nuova opportunità di attacco informatico con una tecnica originale e inaspettata, difficile da immaginare per una persona non addetta ai lavori. Questa tecnica si chiama slopsquatting: un nome coniato dall’esperto di sicurezza Seth Larson.
Il termine unisce due parole inglesi già molto usate in informatica: la prima è slop, che significa “sbobba, brodaglia” e viene usata in senso dispregiativo per indicare il prodotto mediocre, scadente e pieno di errori di molte intelligenze artificiali in vari settori. Una foto sintetica in cui il soggetto ha sei dita, per esempio, o ha una pelle che sembra fatta di plastica, è un tipico caso di slop. La maggior parte della gente non si accorgerà dell’errore o della scarsa qualità e accetterà la sbobba; anzi, a furia di mangiare solo quella si abituerà e la considererà normale.
Nella programmazione assistita dall’intelligenza artificiale, lo slop è un pezzo di codice generato che funziona, sì, ma è inefficiente o vulnerabile oppure non è in grado di gestire alcune situazioni particolari.
La seconda parola che definisce questa nuova forma di attacco è squatting: non c’entra la ginnastica, perché in informatica lo squatting è la pratica consolidata da tempo di occupare una risorsa, per esempio un nome di un sito, al solo scopo di infastidire, truffare o estorcere denaro. Chi compra nomi di dominio o di profili social che corrispondono a nomi di aziende o di celebrità per impedire che lo facciano i legittimi titolari di quei nomi, o allo scopo di chiedere soldi per cederglieli senza attendere le vie legali, fa squatting. I criminali che registrano nomi di siti simili a quelli ufficiali, contando sul fatto che molta gente sbaglia a digitare e sbaglia in modo prevedibile, finendo sui siti dei criminali e immettendovi le proprie password perché crede di essere nel sito ufficiale, fa typosquatting, perché l’errore di battitura in inglese è chiamato typo.
Lo slopsquatting, questa nuova tecnica di attacco al centro di questa storia, è un misto di questi due concetti. In pratica, il criminale crea e pubblica online una risorsa di programmazione malevola, un cosiddetto package o pacchetto, che ha un nome molto simile a quello di una risorsa attendibile e poi aspetta che l’intelligenza artificiale che crea codice di programmazione sbagli e usi per errore quella risorsa malevola al posto di quella genuina.
Chi crea software, infatti, raramente scrive tutto il codice da zero: di solito attinge a funzioni preconfezionate da altri e ampiamente collaudate, che appunto prendono il nome di pacchetti e sono pubblicate online in siti appositi. Ma se l’intelligenza artificiale sbaglia e attinge invece a un pacchetto pubblicato dai criminali con un nome ingannevole, senza che nessuno se ne accorga, il codice ostile dei malviventi verrà integrato direttamente nell’app ufficiale.
In altre parole, il cavallo di Troia informatico, ossia l’app malevola, non arriva dall’esterno, cosa che genera ovvie e facili diffidenze, ma viene costruito direttamente dal creatore originale dell’app senza che se ne renda conto. E a nessuno viene in mente di pensare che l’app ufficiale possa essere infetta e possa essa stessa aprire le porte ai ladri: è quindi un canale di attacco subdolo e letale.
Ma come fa un’intelligenza artificiale a commettere un errore del genere? È semplice: le intelligenze artificiali attuali soffrono di quelle che vengono chiamate in gergo allucinazioni. Per loro natura, a volte, producono risultati sbagliati ma a prima vista simili a quelli corretti. Nel caso delle immagini generate, un’allucinazione può essere una mano con sei dita; nel caso del testo generato da una IA, un’allucinazione può essere una parola che ha un aspetto plausibile ma in realtà non esiste nel vocabolario; e nel caso del codice di programmazione, un’allucinazione può essere una riga di codice che richiama un pacchetto di codice usando un nome sbagliato ma simile a quello giusto.
A prima vista sembra logico pensare che i criminali che volessero approfittare di questo errore dovrebbero essere incredibilmente fortunati, perché dovrebbero aver creato e pubblicato un pacchetto che ha esattamente quello specifico nome sbagliato generato dall’allucinazione dell’intelligenza artificiale. Ma un articolo tecnico pubblicato un mese fa, a marzo 2025 [We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs, disponibile su Arxiv.org], da un gruppo di ricercatori di tre università statunitensi rivela che gli sbagli delle IA tendono a seguire degli schemi sistematici e ripetibili e quindi non è difficile prevedere quali nomi verranno generati dalle loro allucinazioni.
Secondo questi ricercatori, “questa ripetibilità […] rende più facile identificare i bersagli sfruttabili per lo slopsquatting osservando soltanto un numero modesto di generazioni. […] Gli aggressori non hanno bisogno di […] scovare per forza bruta i nomi potenziali: possono semplicemente osservare il comportamento [delle IA], identificare i nomi comunemente generati dalle loro allucinazioni, e registrarseli.”
Un altro problema documentato dai ricercatori è che i nomi generati per errore sono “semanticamente convincenti”: il 38% ha, in altre parole, nomi somiglianti a quelli di pacchetti autentici. E comunque in generale hanno un aspetto credibile. Questo rende difficile che gli sviluppatori possano accorgersi a occhio di un errore.
C’è poi un terzo aspetto di questo problema di sicurezza: se uno specifico errore in un nome di pacchetto generato si diffonde e diventa popolare, perché per esempio viene consigliato spesso dalle intelligenze artificiali e nei tutorial pubblicati senza verifiche, e a quel punto un aggressore registra quel nome, le intelligenze artificiali finiranno per suggerire inconsapevolmente di attingere proprio al pacchetto malevolo, e per i criminali diventerà molto facile sfruttare massicciamente questa tecnica.
Se poi chi crea il software non sa programmare ma si affida totalmente alla IA, tenderà a fidarsi ciecamente di quello che l’intelligenza artificiale gli suggerisce. Come spiegano i ricercatori, “Se la IA include un pacchetto il cui nome è generato da un’allucinazione e sembra plausibile, il percorso di minima resistenza spesso è installarlo e non pensarci più”. E se nessuno controlla e nessuno ci pensa più, se nessuno si chiede “A cosa serve esattamente questo pacchetto richiamato qui?”, o se la domanda viene posta ma la risposta è “Boh, non lo so, ma il programma funziona, lascialo così”, il software ostile creato dai criminali diventerà parte integrante del software usato in azienda.
Di fronte a un attacco del genere, le difese tradizionali dell’informatica vacillano facilmente. È l’equivalente, nel mondo digitale, di sconfiggere un esercito non con un attacco frontale ma intrufolandosi tra i suoi fornitori e dando ai soldati munizioni sottilmente difettose.
Per fortuna gli addetti ai lavori in questo caso hanno anche qualche idea su come proteggersi da questa nuova tecnica.
I ricercatori che hanno documentato questo comportamento pericoloso dei generatori di codice hanno inoltre scoperto che ci sono alcune intelligenze artificiali, in particolare GPT-4 Turbo e DeepSeek, che sono in grado di riconoscere i nomi dei pacchetti sbagliati che essi stessi hanno generato, e lo fanno con un’accuratezza superiore al 75%. Conviene quindi prima di tutto far rivedere alle intelligenze artificiali il codice che hanno prodotto, e già questo è un passo avanti fattibile subito.
Inoltre le aziende del settore della sicurezza informatica hanno già preparato degli strumenti appositi, che si installano nell’ambiente di sviluppo e nel browser e sono in grado di rilevare i pacchetti ostili ancora prima che vengano integrati nel programma che si sta sviluppando. Una volta tanto, le guardie sono in anticipo sui ladri, che finora non sembrano aver sfruttato questa tecnica.
Come capita spesso, insomma, le soluzioni ci sono, ma se chi ne ha bisogno non sa nemmeno che esiste il problema, difficilmente cercherà di risolverlo, per cui il primo passo è informare della sua esistenza. E come capita altrettanto spesso, lavorare al risparmio, eliminando gli sviluppatori umani competenti e qualificati per affidarsi alle intelligenze artificiali perché costano meno e fanno fare bella figura nel bilancio annuale dell’azienda, introduce nuovi punti fragili che devono essere protetti e sono difficilmente immaginabili da chi prende queste decisioni strategiche, perché di solito non è un informatico.
Il problema centrale dello slopsquatting non è convincere gli informatici: è convincere i decisori aziendali. Ma questa è una sfida umana, non tecnica, e quindi il Disinformatico si deve fermare qui. Speriamo in bene.
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco settimanalmente sulla Rete Tre della Radiotelevisione Svizzera solitamente insieme a Rosy Nervi ma questa volta con Ellis Cavallini. La trasmissione è riascoltabile sul sito della RSI oppure nell’embed qui sotto.
14 aprile 1896: viene emesso il brevetto dei corn flakes a nome di John Harvey Kellogg (Brevetto USA 558,393; Wikipedia).
Il film Morti di Salute del 1994, regia di Alan Parker, con Anthony Hopkins, Bridget Fonda e Matthew Broderick, racconta in maniera poco fedele ma molto comica le manie salutiste eccentriche di Kellogg e dell’epoca in generale e alimenta il mito che Kellogg inventò questi cereali come cibo blando per reprimere le pulsioni sessuali mentre è più legato alla dieta vegetariana incoraggiata dalla chiesa avventista di cui faceva parte Kellogg (Snopes).
La moda del momento: usare ChatGPT o Copilot per creare immagini in stile Studio Ghibli e in stile confezione di bambola. Quanta energia consuma tutto questo? In un anno, più di quanta ne consumino 117 paesi del mondo (BBC).
14 aprile 1912: il disastro del Titanic e le recentissime ricostruzioni digitali del relitto nel documentario Titanic Digital Resurrection (BBC); il racconto di come la scoperta del Titanic avvenne come missione di copertura per nascondere il tentativo di ritrovare due sommergibili nucleari statunitensi (lo Scorpion e il Thresher) che si erano inabissati.
Prova in studio degli occhiali con prismi per leggere (o lavorare al computer) stando sdraiati (li ho comprati online e funzionano benissimo; attenti però alla nausea da movimento). Vengono usati anche quando si fa una risonanza magnetica per ridurre l’effetto di claustrofobia, e li impiegano gli scalatori per guardare in su verso i compagni.
L’Instagram strano della settimana: dalla Turchia, audio ASMR di asinelli che mangiano e ottengono 1,4 milioni di follower (@ccihancelik_).
Sono trascorsi pochi minuti da quando le lancette dell’orologio hanno scoccato in Texas le nove di sera di lunedì 13 aprile; in Italia sono già le prime ore del mattino di martedì 14, precisamente le 04:08. Si è da poco concluso il quarto collegamento televisivo in diretta con l’equipaggio di Apollo 13. Gli inviati speciali della carta stampata di buona parte del pianeta, presenti nella sala adibita ai giornalisti al Centro spaziale di Houston, stanno già trascrivendo gli articoli da spedire nelle varie redazioni dei quotidiani sulle prossime importanti e delicate manovre che James Lovell, Fred Haise e “Jack” Swigert dovranno effettuare nelle prossime ore: l’ingresso in orbita lunare, la discesa del quinto e sesto americano sulla Luna a bordo del Modulo Lunare “Aquarius” e le due attività previste sulla superficie selenica.
All’improvviso la voce del pilota del Modulo di Comando “Odyssey”, Swigert, fa sobbalzare l’intera squadra dei tecnici che a turno, da sabato 11 aprile, sta seguendo e monitorando minuto per minuto il viaggio lunare:
“Okay, Houston, we’ve had a problem here” (“OK, Houston, abbiamo avuto un problema qui”). Questa è la frase esatta pronunciata, anche se molti la citano erroneamente come “Houston, we have a problem”, ossia “Houston, abbiamo un problema”.
Subito dopo la voce del comandante Lovell conferma: “Houston, we’ve had a problem” (“Houston, abbiamo avuto un problema”). “Le spie di allarme stanno lampeggiando, i manometri dell’ossigeno in due delle tre celle a combustibile segnano zero… perdiamo gas all’esterno… abbiamo sentito un forte botto… il veicolo sta beccheggiando fortemente”.
A Houston appare subito evidente che la situazione è estremamente critica: è il primo, drammatico S.O.S. nella storia dell’esplorazione umana nello spazio. La voce del comandante di Apollo 13 continua a giungere a terra calma ma fredda come una lama d’acciaio: “Houston, la pressione dell’ossigeno nella cabina di Odyssey sta diminuendo rapidamente”.
Per quanto imprevisto e imprevedibile sia il dramma scoppiato a 370.000 km dal nostro pianeta, i controllori a terra si attivano preparando subito un piano di emergenza. Houston comunica: “Trasferitevi all’interno del Modulo Lunare, potrete così continuare a respirare utilizzando le scorte di ossigeno del Lem e continuare nelle manovre di emergenza”.
Mentre Lovell e Haise prendono posto a bordo di “Aquarius”, Swigert rimane solo su “Odyssey” per eseguire tutte le operazioni necessarie che gli vengono suggerite dai tecnici a Houston: è necessario spegnere tutti i sistemi vitali del Modulo di Comando, per ridurre al minimo il consumo di energia e conservare l’esiguo margine di 15 minuti di erogazione elettrica rimasto, per quando i tre intrepidi eroi tenteranno il ritorno sulla Terra. Anche le comunicazioni radio Terra-spazio vengono ridotte al minimo per risparmiare energia. A bordo di “Odyssey” cala il buio e aumenta il freddo; da questo istante gli astronauti sopravvivranno solo grazie ai generatori del Modulo Lunare “Aquarius”, nato per diventare base per il quinto e sesto esploratore lunare sulla superficie di Fra Mauro, ma diventato ora “scialuppa di salvataggio” per i tre valorosi americani.
A poco più di due ore dall’incidente, alle 11:24 della sera a Houston (le 06:24 del mattino in Italia), il Centro di controllo della base texana annuncia ufficialmente di avere annullato “l’operazione sbarco sulla Luna”. Ora quello che più conta è far ritornare a casa sani e salvi gli sfortunati protagonisti di quella che avrebbe dovuto essere la prima missione scientifica sul suolo del satellite naturale della Terra.
La prima cosa da fare è riportare il complesso formato dal Modulo di Comando/Servizio e dal Modulo Lunare nella giusta traiettoria di “libero ritorno” che Apollo 13, nel suo viaggio translunare, aveva abbandonato già al secondo giorno di volo per consentire una manovra più precisa di discesa di “Aquarius” nella zona prevista di Fra Mauro. I tecnici a Houston, in completa alleanza con i calcolatori elettronici a loro disposizione, stabiliscono le modalità della delicata e drammatica operazione: la correzione di rotta può essere effettuata solo dal motore del modulo di discesa del Lem, dopodiché se l’operazione riuscirà Apollo 13 si riporterà automaticamente sulla giusta strada del ritorno verso la Terra.
Fortunatamente la manovra riesce: il motore del modulo di discesa di “Aquarius” viene acceso per trentaquattro secondi, inserendo sulla giusta strada del “libero ritorno” il complesso spaziale e il suo prezioso carico umano. Sono le 02:43 ora di Houston, le 09:43 italiane.
Un’altra buona notizia è che grazie ai giroscopi elettronici l’equipaggio è riuscito a stabilizzare il rollio del complesso spaziale e secondo i calcoli fatti dai tecnici della NASA gli astronauti hanno riserve sufficienti a bordo per ritornare sulla Terra venerdì 17 aprile. A Houston si comincia a sperare.
Sulla Terra, intanto, è ormai giorno in buona parte del mondo occidentale, la cui opinione pubblica è stata messa al corrente del dramma che si sta consumando a quasi quattrocentomila chilometri di distanza. Le varie edizioni straordinarie di TV, radio e giornali informano minuto per minuto che la terza missione umana destinata a scendere sulla Luna ha la seria possibilità di trasformarsi nel primo naufragio spaziale della storia.
Alcuni astronauti e controllori di volo nella sala controllo principale di Houston. Seduti, da sinistra: Raymond Teague (Guidance Officer), Edgar Michell (astronauta), Alan Shepard Jr. (astronauta). In piedi, da sinistra: Anthony England (astronauta), Joe Engle (astronauta), Gene Cernan (astronauta), Ronald Evans (astronauta) e M.P. Frank (controllore di volo). L’orario esatto della foto non è noto ma è successivo alla decisione di annullare l’allunaggio; l’equipaggio stava già tentando di tornare a terra (Foto S70-34986).
Le prime pagine de “Il Resto del Carlino” e “Il Corriere della Sera” di mercoledì 15 aprile 1970.
Le lancette dell’orologio in Italia segnano le 20:13 di sabato 11 aprile 1970. Sulla costa orientale degli Stati Uniti, e specificamente nello stato della Florida, sono le 14:13. Le televisioni di quasi tutto il pianeta sono collegate con il Centro spaziale Kennedy. In Italia, poco prima dell’inizio del telegionale serale delle 20:30, è in onda un’edizione straordinaria; in studio ci sono Tito Stagno e Piero Forcella. La voce dell’annunciatore della NASA Chuck Hollinshead ha appena finito di scandire gli ultimi secondi di un conto alla rovescia impeccabile, al contrario degli eventi umani che hanno preceduto questo momento (la rosolia di Mattingly e la sua sostituzione con Swigert), quando la rampa di lancio 39-A viene investita da una vampata immensa di fuoco e fiamme scaturite dai cinque potenti motori F-1 del primo stadio del gigantesco Saturn V.
Dapprima lentamente, poi via via sempre più veloce, il razzo più grande e più potente mai costruito dall’uomo fino a quel momento si distacca dal suolo terrestre, allungando sempre di più la sua corsa verso il cielo: è iniziato il viaggio di Apollo 13 verso la la Luna con a bordo l’equipaggio formato da James Lovell, Fred Haise e John Swigert.
Nelle fasi iniziali del volo, però, non tutto funziona alla perfezione: dopo il regolare distacco dell’S-IC, il primo stadio del Saturn, a due minuti e 44 secondi dal distacco dalla torre di lancio, e dopo l’accensione del secondo stadio S-II, il motore centrale di quest’ultimo cessa di funzionare due minuti prima del previsto. Da bordo della cabina dell’Apollo, lanciata ad altissima velocità verso la quota orbitale, si sente la voce del comandante Lovell: “Questo non sarebbe dovuto succedere”. Fortunatamente il “cervello elettronico” del Saturn comanda agli altri quattro motori di rimanere accesi 45 secondi in più.
Dopo nove minuti e 53 secondi anche il secondo stadio viene abbandonato, e l’accensione dell’unico motore del terzo stadio, l’S-IVB, permette la perfetta inserzione nella prevista orbita di parcheggio intorno alla Terra. Sono trascorsi 12 minuti e 39 secondi dal distacco dalla rampa di lancio. In Italia sono le 20:25. A Houston il grande orologio della sala di controllo segna le 14:25.
La prossima manovra del piano di volo è prevista a due ore e 41 minuti dal “liftoff”, quando verrà riacceso il potente motore del terzo stadio per immettere Apollo 13, con il suo prezioso carico umano, nella giusta traiettoria per l’altopiano lunare di Fra Mauro.
Per la terza volta, in meno di nove mesi, due astronauti americani, il quinto e il sesto nella storia dell’umanità, James Lovell e Fred Haise, si accingono a raggiungere il satellite naturale della Terra e a camminare sulla sua desolata superficie, per la prima vera esplorazione scientifica della Luna. Jack Swigert li attenderà in orbita.
Cape Kennedy. Mentre la terra trema a chilometri di distanza, il Saturn V si avvia a portare in orbita terrestre i tre di Apollo 13.
La prima pagina del “Corriere della Sera” di domenica 12 aprile 1970.
L’inizio del terzo sbarco lunare umano sulla prima pagina del quotidiano “La Stampa”.
Questo è il testo della puntata del 7 aprile 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP letta da voce sintetica: “Con l’invenzione e lo sviluppo della televisione, e il progresso tecnico che rese possibile di ricevere e trasmettere simultaneamente sullo stesso apparecchio, il concetto di vita privata si poteva considerare del tutto scomparso. Ogni cittadino, o meglio ogni cittadino che fosse abbastanza importante e che valesse la pena di sorvegliare, poteva essere tenuto comodamente sotto gli occhi della polizia e a portata della propaganda ufficiale”]
George Orwell, l’autore del celeberrimo libro distopico 1984 dal quale sono tratte queste parole, era un ottimista. Pensava che la sorveglianza tramite la tecnologia sarebbe stata applicata solo a chi fosse abbastanza importante. Oggi, invece, la sorveglianza tecnologica si applica a tutti, in massa, e per di più siamo noi utenti a pagare per i dispositivi che la consentono.
Uno di questi dispositivi è il televisore, o meglio la “Smart TV”, come va di moda chiamarla adesso. Sì, perché buona parte dei televisori moderni in commercio è dotata di un sistema che raccoglie informazioni su quello che guardiamo sullo schermo e le trasmette a un archivio centralizzato. Non a scopo di sorveglianza totalitaria, ma per mandarci pubblicità sempre più mirate, basate sulle nostre abitudini e i nostri gusti. In sostanza, molti televisori fanno continui screenshot di quello che state guardando, non importa se sia una serie di Netflix, un videogioco o un vostro video personale, e li usano per riconoscere cosa state guardando e per suggerire ai pubblicitari quali prodotti o servizi mostrarvi.
Probabilmente non ne avete mai sentito parlare, perché non è una caratteristica tecnica che i fabbricanti sbandierano fieramente, ma esiste, e funziona talmente bene che almeno un’azienda costruttrice ha guadagnato più da questa sorveglianza di massa che dalla vendita dei propri televisori.
Questa è la storia di questo sistema di sorveglianza integrato, di come funziona e soprattutto di come controllare se è presente nella vostra Smart TV e di come disattivarlo.
Benvenuti alla puntata del 7 aprile 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Se avete una Smart TV, uno di quei televisori ultrapiatti che si collegano a Internet, probabilmente ogni volta che lo usate per guardare qualcosa siete in compagna di un ospite non invitato.
Questo ospite si chiama ACR, che sta per Automated Content Recognition o “riconoscimento automatico dei contenuti”. È un software, integrato nel televisore, che raccoglie dati su tutto quello che guardate e li manda a un archivio centrale per identificare cosa state guardando e mandarvi pubblicità personalizzate. La sua esistenza non è un segreto in senso stretto, ma i fabbricanti di televisori non si sforzano molto per farla conoscere al consumatore medio.
Questo ACR effettua continuamente delle catture dello schermo, degli screenshot, di quello che state vedendo; lo fa con qualunque cosa venga mostrata sullo schermo, quindi non solo programmi di canali televisivi ma anche Blu-Ray, sessioni di videogioco, video personali e schermate di lavoro per chi, come me, usa una Smart TV come monitor gigante per il proprio computer. Ne fa veramente tante, di queste catture: fino a 7200 ogni ora, ossia circa due al secondo.
Queste catture vengono elaborate per crearne una sintesi, una sorta di impronta digitale [fingerprint in inglese] che viene confrontata con un enorme archivio di contenuti video di vario genere, compresi gli spot pubblicitari. Quando viene trovata una corrispondenza, il sistema deduce che state guardando quel contenuto e avvisa i gestori del servizio, che possono vendere quest’informazione a scopo pubblicitario o per proporre contenuti a tema. Queste vendite rappresentavano, nel 2022, un mercato che valeva quasi venti miliardi di dollari ed è in continua crescita.
I fabbricanti che partecipano al sistema ACR sono fra i più blasonati: nomi come Roku, Samsung, LG, Sony, Hisense e tanti altri. Non è un sistema particolarmente nuovo, perché esiste almeno dal 2011. E funziona molto bene, almeno dal punto di vista di chi lo vende: a novembre 2021, uno di questi fabbricanti di Smart TV, Vizio, uno dei più importanti negli Stati Uniti, ha guadagnato dalla vendita dei dati dei propri clienti più del doppio di quello che ha ottenuto dalla vendita degli apparecchi televisivi [The Verge; Vizio].
Schema generale del funzionamento dell’ACR (da Watching TV with the Second-Party: A First Look at Automatic Content Recognition Tracking in Smart TVs, Arxiv.org, 2024).
Probabilmente a questo punto vi state chiedendo se catturare di nascosto quello che c’è sullo schermo della TV che sta in casa vostra sia legale. La risposta, come sempre in questi casi, è un grosso “dipende”. Le normative statunitensi sono molto permissive, mentre quelle europee sono orientate alla tutela del consumatore.
Eppure anche negli Stati Uniti, quella stessa Vizio che ha guadagnato così tanto dall’uso dell’ACR era stata sanzionata dalla Commissione federale per il commercio [FTC] nel 2017 perché con questo sistema raccoglieva i dati di ascolto di undici milioni di televisori senza il consenso dei consumatori e senza che quei consumatori ne fossero a conoscenza. Secondo la Commissione, Vizio aveva reso facile associare a questi dati televisivi numerose informazioni personali come “sesso, età, reddito, stato civile, dimensioni del nucleo famigliare, livello di istruzione, proprietà e valore dell’abitazione” e ha anche “venduto queste informazioni a terzi, che le hanno usate a vari scopi, compresa la pubblicità mirata”.
La sanzione, di circa 2 milioni di dollari, è stata in sostanza trascurabile: un costo operativo più che una punizione efficace [FTC; FTC]. Un tribunale federale statunitense ha poi approvato un risarcimento di 17 milioni di dollari in seguito a una class action avviata per le stesse ragioni contro la stessa azienda [Class Law Group; Hunton.com]. Questo caso dimostra la disinvoltura con la quale le aziende trattano i dati e i diritti dei consumatori.
C’è anche un altro tipo di disinvoltura aziendale legato a questo riconoscimento automatico dei contenuti: l’idea che bombardare l’utente di pubblicità sia non tanto un male necessario, ma addirittura un beneficio per il consumatore. Come dice una presentazione di Samsung dedicata al mercato canadese, “la tecnologia ACR offre numerosi benefici sia per gli spettatori, sia per gli inserzionisti. Per gli spettatori, l’ACR crea un’esperienza televisiva veramente personalizzata.”
La pagina della presentazione di Samsung che parla di “esperienza televisiva veramente personalizzata” grazie all’ACR.
Il flusso di dati dell’ACR di Samsung che conferma la cattura di due immagini al secondo da parte del televisore.
Samsung spiega che i consumatori sono “sovraccaricati dalla quantità di scelte disponibili e faticano a scoprire contenuti nuovi e pertinenti”. Oltre l’80% degli interpellati in uno studio svolto nel 2022 dall’azienda, sempre in Canada, ha dichiarato che sarebbe interessato a ricevere suggerimenti intelligenti sui contenuti per aiutarlo a trovare serie TV di suo gradimento. Ma desiderare di “ricevere suggerimenti su cosa guardare” non è la stessa cosa che voler essere spiati in tutto quello che si guarda alla TV pur di ricevere quei suggerimenti.
Alle aziende, insomma, sembra che non passi nemmeno per l’anticamera del cervello l’ipotesi che chi ha comprato un televisore, pagandolo con i propri soldi, non voglia essere bombardato da pubblicità che non ha richiesto e voglia invece usare il televisore come vuole lui o lei e non come glielo impone di nascosto un fabbricante. Per questi produttori di televisori è a quanto pare inconcepibile che qualcuno voglia vivere senza spot pubblicitari e che non desideri una “esperienza televisiva personalizzata”, ma voglia semplicemente guardare la TV in santa pace.
La Smart TV non è la versione piatta del televisore classico, non è un dispositivo passivo che mostra a chi lo ha comprato quello che gli interessa: è diventato un fragoroso, ossessivo, insistente chioschetto pubblicitario al servizio dei fabbricanti, degli inserzionisti e dei data broker che guadagnano miliardi vendendo i fatti nostri.
E in questa presentazione di Samsung c’è annidato anche un altro dato interessante: il servizio ACR di questa azienda ha anche una funzione cross-device. In altre parole, è capace di coinvolgere in questa sorveglianza commerciale anche gli altri dispositivi connessi, come i telefonini e i tablet. Piattaforme commerciali come Samba TV usano i dati dell’ACR per mostrare sui telefonini di casa le stesse pubblicità che passano sulla Smart TV [The Viewpoint]. Quei telefonini vengono associati alla casa perché si collegano al Wi-Fi domestico, come fa anche il televisore, e quindi hanno lo stesso indirizzo IP.
La pagina della presentazione di Samsung che parla di funzioni cross-device.
Molti utenti pensano che il telefonino li ascolti, perché vedono comparire sul suo schermo le pubblicità di cose di cui hanno parlato, ma in realtà è probabile che ad ascoltarli o a dedurre i loro interessi sia quell’altro schermo che hanno in casa.
Vediamo allora come scoprire se una Smart TV fa la spia e come disattivare questa funzione.
Per tagliare la testa al toro ed evitare completamente la sorveglianza commerciale dell’ACR nei televisori smart ci sono due soluzioni. La prima è… non acquistare una Smart TV.
Al posto del televisore, infatti, si può acquistare un monitor per computer. Questi dispositivi, almeno per ora, non hanno funzioni di sorveglianza e si possono collegare al set top box per lo streaming, al computer o al lettore Blu-Ray. Il difetto di questa soluzione è che chi desidera uno schermo molto grande non troverà monitor per computer delle dimensioni desiderate. In alternativa, si può scegliere un videoproiettore, che consente di avere immagini molto grandi ed è anch’esso, per ora, privo di funzioni di riconoscimento dei contenuti proiettati.
La seconda soluzione è acquistare una Smart TV, ma non collegarla a Internet, né tramite cavo Ethernet né tramite Wi-Fi. In questo modo, se anche dovesse acquisire degli screenshot di quello che si sta guardando, non potrà trasmettere alcuna informazione al suo fabbricante. È quello che ho fatto io: il televisore del Maniero Digitale è una Smart TV OLED collegata a un computer, a un set top box o a un riproduttore di Blu-Ray esclusivamente tramite cavo HDMI, lungo il quale non transitano informazioni pubblicitarie.
Se invece avete già una Smart TV e volete sapere se sorveglia quello che guardate, su Internet ci sono numerose istruzioni dettagliate, per ogni specifica marca, che spiegano in quale menu, sottomenu e sotto-sottomenu andare per cercare le funzioni-spia; le trovate linkate su Attivissimo.me [articolo su ZDNet; articolo su The Markup].
A dimostrazione del fatto che le aziende non ci tengono affatto a informare il consumatore che viene sorvegliato, queste funzioni non vengono indicate con un nome esplicativo o almeno con la sigla standard ACR, ma sono presenti con nomi decisamente eufemistici e ingannevoli. Per Samsung, per esempio, il nome da cercare è Viewing Information Services, ossia “servizi per le informazioni di fruizione”; per Sony è Samba Services Manager.
Considerata la tendenza crescente a guardare film e serie TV mentre si usa lo smartphone o si fa altro, tanto che i copioni di molte nuove produzioni vengono scritti facendo dire ai personaggi ogni tanto un riassunto della situazione per i più distratti, si può dire che viviamo in un mondo nel quale i nostri televisori guardano noi più attentamente di quanto noi guardiamo loro, e sanno di noi molto più di quello che sappiamo noi di loro. Non dovremmo preoccuparci che possano diventare senzienti con l’intelligenza artificiale, ma che siano già diventati insopportabilmente pettegoli.
In perfetto orario questa mattina, 8 aprile 2025, alle 07:47 ora italiana, è stata lanciata dal Cosmodromo di Baikonur la Soyuz MS-27, con a bordo un equipaggio formato da tre astronauti. Obiettivo del volo, raggiunto felicemente tre ore dopo il distacco dalla rampa di lancio, l’aggancio alla Stazione spaziale Internazionale (ISS).
I tre uomini arrivati con la Soyuz, i russi Sergei Ryzhikov e Aleksei Zubritsky e l’americano Jonathan Kim, rimarranno sull’avamposto orbitale per circa otto mesi. Il ritorno a terra è previsto, se il programma di volo sarà rispettato, per il mese di dicembre di quest’anno.
Con l’arrivo dei tre nuovi “inquilini”, la ISS ha ora a bordo dieci persone: otto uomini e due donne.
Durante il lungo periodo che i nuovi arrivati trascorreranno in orbita, verranno condotti numerosi esperimenti e inoltre alcuni lavori di manutenzione interna ed esterna della Stazione spaziale, compresa una attività extraveicolare per il segmento statunitense, alla quale potrebbe partecipare lo stesso Jonathan Kim. Il lancio della Soyuz MS-27 è il 353° volo orbitale umano da quel primo storico compiuto il 12 aprile 1961 da Yuri Gagarin.
I tre astronauti che hanno raggiunto la ISS a bordo della Soyuz MS-27. A sinistra l’americano Jonathan Kim, al centro il comandante del volo Sergei Rizhikov, e a destra Aleksei Zubritsky.
La Soyuz con i suoi tre uomini in volo verso lo spazio per l’appuntamento orbitale con l’ISS.
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embed qui sotto.
La puntata è più breve del solito perché sono arrivato in studio con molto ritardo a causa della paralisi del traffico intorno a Lugano provocata da un incidente.
Qual è il contrario di un limone? Chimicamente è l’arancia. I due agrumi infatti contengono due versioni differenti (speculari) della stessa molecola, il limonene, che conferisce il caratteristico aroma.
Il Paradosso di Fermi: se non siamo soli nell’universo, dove sono tutti quanti? (Ars Technica).
A 22:18 rispondo a un ascoltatore che mi definisce “uno che crede che l’uomo è stato sulla Luna” e trova paradossale che io parli di alieni.
A 27:00 parliamo di piramidi e presunta disposizione secondo le costellazioni e a 31:00 parliamo del giacimento di Saqqara e del presunto mistero dei sarcofagi troppo grandi per passare dai cunicoli.
37:50: perché le tigri sono arancioni? Non sembra un buon metodo per mimetizzarsi, eppure c’è una ragione biologica molto precisa per cui l’arancione in un ambiente verde funziona come mimetizzazione (IFLScience; Livescience)
7 aprile 1970, martedì. Mentre il conto alla rovescia per il terzo sbarco umano sulla Luna procede spedito verso la conclusione prevista per l’11 aprile alle ore 20:13 italiane, al Centro spaziale Kennedy giunge come un fulmine a ciel sereno la notizia che durante una delle ultime visite mediche a cui sono sottoposti periodicamente i tre astronauti titolari di Apollo 13 (James Lovell, Fred Haise e Thomas Mattingly) e quelli di riserva (John Young, John Swigert e Charlie Duke), risulta che quest’ultimo, pilota di riserva del Modulo Lunare, ha contratto da uno dei suoi due figli la rosolia.
Mattingly, pilota del Modulo di Comando, dopo ulteriori ed accurati controlli medici, risulta essere l’unico dei sei che non è immune a questa malattia. Per non correre il grave rischio che si ammali durante la missione che porterà i tre uomini a quasi 400.000 chilometri di distanza dalla Terra, il medico della NASA, Charles Berry, chiede l’immediata sostituzione del pilota titolare con la sua riserva John “Jack” Swigert.
Nonostante il parere contrario del comandante del volo James Lovell, restio a modificare parte dell’equipaggio a pochi giorni dall’inizio del grande viaggio, il rischio che la missione possa subire un lungo rinvio convince il veterano dello spazio, che ha al proprio attivo tre voli spaziali, ad accettare la decisione dell’ente spaziale.
Swigert già il giorno successivo inizia una serie di prove tecniche intensive sul simulatore di bordo del Modulo di Comando per garantire un maggior affiatamento tra i membri dell’equipaggio e con i tecnici del Centro di controllo di Cape Kennedy e di Houston che monitoreranno la quinta spedizione umana verso la Luna.
L’equipaggio originale designato per la missione Apollo 13. A sinistra il comandante James Lovell, al centro il pilota del modulo di comando Thomas Mattingly (l’astronauta a rischio di sviluppare la rosolia mentre è nello spazio), e a destra Fred Haise, pilota del modulo lunare.
John “Jack” Swigert, l’astronauta di riserva chiamato a sostituire come pilota del modulo di comando Thomas Mattingly.
9 aprile 1970, giovedì. A due giorni dall’inizio del volo programmato verso la Luna di Apollo 13, c’è molta attesa nel mondo scientifico e nell’opinione pubblica per via della grande incertezza che regna dopo la notizia, resa ufficiale dalla NASA e apparsa sui giornali di tutto il mondo, del possibile contagio con la rosolia subìto da uno dei tre astronauti dell’equipaggio titolare, Thomas Mattingly, pilota del modulo di comando.
Da Stampa Sera del 9 aprile 1970.
Da La Stampa del 9 aprile 1970.
Le voci che circolano al di fuori del Centro spaziale Kennedy ipotizzano un probabile lungo rinvio della terza missione, la prima veramente scientifica rispetto alle due precedenti, che avrebbe visto come protagonisti oltre allo stesso Mattingly il veterano dello spazio James Lovell come comandante e Fred Haise, al suo primo volo, come pilota del modulo lunare.
Ma l’ente spaziale americano ha già preso la sua decisione: si parte comunque. Mattingly per precauzione resterà a terra e verrà sostituito dalla riserva John “Jack” Swigert, ugualmente ben preparata alle difficoltà del viaggio.
Il conto alla rovescia alla base spaziale di Cape Kennedy dunque non si ferma. Il “liftoff” di Apollo 13 verso la Luna con destinazione la zona di Fra’ Mauro, una regione ritenuta molto interessante dai selenologi, viene confermato per sabato 11 aprile, quando in Italia saranno le 20:13 italiane, le 14:13 in Florida.
Venerdì scorso (4 aprile 2025) uno spettacolare ammaraggio nelle acque dell’Oceano Pacifico (non nuove a rientri sulla Terra di navicelle spaziali statunitensi, tra cui quelle indimenticabili delle missioni lunari Apollo) ha concluso la breve ma storica missione della Dragon “Resilience” con a bordo quattro astronauti non professionisti.
Chi ha assistito alle fasi finali del rientro in diretta televisiva sul canale ufficiale della NASA non ha saputo trattenere le emozioni, tanto era la chiarezza delle immagini trasmesse in 4K.
Subito dopo l’ammaraggio, avvenuto alle 18:19 ora italiana, i quattro astronauti, una volta issata la navicella sulla piattaforma di recupero, sono riusciti ad uscire autonomamente dalla Dragon, anche se con qualche comprensibile difficoltà ma sorridenti: anche questo era uno dei tanti esperimenti compresi nel breve volo durato tre giorni, 14 ore e 32 minuti.
Durante il volo a bordo della “Resilience” nella missione “Fram-2”, così denominata in onore della nave norvegese che effettuò i primi viaggi pionieristici nell’Artico e in Antartide tra il 1893 e il 1912, l’imprenditore cinese ma naturalizzato maltese Chun Wang, la regista norvegese Jannicke Mikkelsen, l’esploratore australiano Eric Philips e l’ingegnere tedesca Rabea Rogge, oltre ad aver sorvolato i poli dall’orbita terrestre (per primi nella storia dell’esplorazione spaziale umana), hanno compiuto più di venti esperimenti scientifici. I più importanti: la prima radiografia del corpo umano nello spazio, lo studio della regolazione del glucosio in microgravità e la possibile coltivazione dei funghi in un ambiente di microgravità.
Una immagine dalla Dragon “Resilience” durante un sorvolo di un polo terrestre.
Lo “splashdown” della Dragon nelle acque dell’Oceano Pacifico al termine di una missione di quasi quattro giorni in orbita polare.
Venerdì scorso sono stato ospite della trasmissione Patti Chiari della Radiotelevisione Svizzera per parlare di due tipi di truffa che sono diventati molto diffusi: il furto di denaro tramite codici QR ingannevoli e il furto di auto tramite le rispettive app di gestione.
La puntata è visionabile qui oppure qui sotto (salvo georestrizioni che mi segnalano alcuni commentatori):
Aggiungo qualche link utile per inquadrare meglio i due casi:
Il test per sapere se siete in grado di riconoscere un messaggio fraudolento
La pagina di Tesla che spiega (in italiano) come funziona l’autenticazione a due fattori (o autenticazione a più fattori, come la chiama Tesla) sulle sue auto (e anche sulla mia)
Sottolineo, per maggiore chiarezza, che l’autenticazione a due fattori non va confusa con il PIN di sblocco dell’auto, il cosiddetto PIN to Drive. L’autenticazione protegge l’accesso all’account usato per gestire l’auto tramite l’app; il PIN di sblocco protegge l’auto contro il furto perché è un PIN che va digitato sullo schermo dell’auto, nell‘abitacolo, per consentirne la guida.
Domani, 5 aprile 2025, ricorre il cinquantesimo anniversario della prima missione spaziale con rientro d’emergenza durante le fasi del lancio.
Il disastro sfiorato accade durante l’inizio dell’ascesa verso gli strati alti dell’atmosfera della Soyuz 18 (successivamente ribattezzata Soyuz 18-A), a bordo della quale si trovano Vasili Lazarev e Oleg Makarov. Obiettivo della diciassettesima missione di una Soyuz con equipaggio è il raggiungimento e l’aggancio al laboratorio Salyut 4, che si trova in orbita dal 26 dicembre 1974 ed è già stato visitato dal precedente equipaggio della Soyuz 17.
Il lancio avviene la mattina del 5 aprile 1975 dal Cosmodromo di Baikonur, nel Kazakistan, allora facente parte all’Unione Sovietica (diventerà indipendente nel 1992 dopo lo scioglimento dell’URSS); Lazarev e Makarov sono alla loro seconda impresa spaziale, avendo già volato insieme durante la missione Soyuz 12 nel settembre del 1973.
L’inizio del volo verso gli alti strati dell’atmosfera fila liscio come l’olio, ma al momento previsto per la separazione del secondo stadio, ormai esaurito, dal terzo, quattro minuti e 48 secondi dopo il decollo e ad una quota di 145 km, il distacco non avviene nella maniera corretta: il motore del terzo stadio, indispensabile per raggiungere l’orbita terrestre, si accende quando il secondo stadio è ancora agganciato ad esso.
Fortunatamente la spinta del motore del terzo stadio spezza gli agganci che ancora tengono uniti i due veicoli; a questo punto la forte sollecitazione fa deviare pericolosamente il complesso spaziale dalla prevista traiettoria di volo. A causa del guasto tecnico, e avendo rilevato l’anomalia, il sistema di guida automatico della Soyuz attiva il programma di “abort”: l’interruzione di emergenza durante una fase di lancio. È la prima volta nella storia della esplorazione spaziale umana che questo accade.
Al momento dell’avaria, la “torre di salvataggio” collocata all’estremità del razzo A-2 era già stata sganciata ed è quindi necessario attivare il motore principale della Soyuz, separando dapprima il veicolo dal terzo stadio e successivamente dal modulo orbitale e quello di servizio.
Avvenuto ciò, il ritorno verso la Terra della navicella è alquanto drammatico: essendo accelerata fortemente la sua discesa, i due cosmonauti subiscono una decelerazione di 21,3 g invece dei 15 g previsti per queste situazioni di emergenza. Fortunatamente, nonostante il sovraccarico di pressione alla quale viene sottoposta la Soyuz, a pochi chilometri dal suolo i paracadute si dispiegano perfettamente, frenando la navicella e garantendo il ritorno sulla Terra dei due cosmonauti dopo soli 21 minuti e 27 secondi di volo.
Tutto bene dunque per i cosmonauti; i due rientrano a terra sani e salvi, come rilanciano le principali fonti giornalistiche sovietiche nel dare notizia al paese e al mondo dell’avvenuto incidente. Ma a dispetto delle dichiarazioni ufficiali, come ricorda il sito Almanacco dello Spazio di Paolo Attivissimo alla data 5 aprile, i guai di Lazarev e Makarov non sono finiti: la capsula cade su un pendio innevato e rotola verso uno strapiombo alto 150 metri, finché i paracadute s’impigliano nella vegetazione e trattengono il veicolo spaziale.
L’equipaggio si trova immerso nella neve alta fino al petto e a -7 °C, per cui indossa l’abbigliamento termico d’emergenza. Inizialmente teme di essere finito in territorio cinese, in un momento in cui i rapporti fra Unione Sovietica e Cina sono molto ostili, e quindi si affretta a distruggere i documenti riguardanti un esperimento militare che si sarebbe dovuto svolgere durante la missione.
In realtà l’atterraggio è avvenuto in territorio sovietico, a sud-ovest di Gorno-Altaisk, circa 830 km a nord del confine con la Cina e a circa 1500 km dalla base di lancio, ma i cosmonauti non lo sanno fino a quando viene conseguito il contatto radio con un elicottero di soccorso, il cui equipaggio li informa sul luogo di atterraggio. Lazarev e Makarov sono in patria, ma la zona è talmente impervia che non vengono recuperati fino all’indomani.
Inizialmente le autorità sovietiche dichiarano che i cosmonauti non hanno subito lesioni, ma emergerà poi che Lazarev ha subito traumi a causa dell’elevatissima decelerazione. Makarov, invece, tornerà a volare con le Soyuz 26, 27 e T-3.
La censura sovietica nasconde la serietà dell’incidente all’opinione pubblica nazionale fino al 1983: all’indomani del lancio i giornali russi si limitano a scrivere in seconda pagina, con un titolo piccolo e blandissimo (“Comunicato dal centro di controllo del volo”) che lo fa passare pressoché inosservato, che “durante il percorso del terzo stadio del razzo i parametri della traiettoria hanno deviato da quelli prestabiliti e un meccanismo automatico ha fatto interrompere il volo, distaccando la cabina spaziale in modo che scendesse a terra. L’atterraggio morbido è avvenuto a sud-ovest di Gorno-Altaisk (Siberia occidentale). I servizi di ricerca e soccorso hanno ricondotto al cosmodromo i due cosmonauti, che stanno bene”.
Gli Stati Uniti, invece, vengono avvisati sommariamente il 7 aprile, dopo il recupero dell’equipaggio, ma chiedono maggiori chiarimenti, perché sono in corso i preparativi per una storica missione spaziale congiunta fra russi e americani, l’Apollo-Soyuz Test Project, che dovrà decollare tre mesi dopo.
Nella storia dei voli spaziali umani dal 1961, a tutto il mese di marzo 2025, ci sono stati altri tre “abort”, interruzioni improvvise di un volo con equipaggio poco dopo il lancio. A quel primo della Soyuz 18-A si sono aggiunte altre due missioni sovietiche/russe: Soyuz T-10A (settembre 1983) e Soyuz MA-10 (ottobre 2018). Anche in questi casi i cosmonauti a bordo sono rientrati a terra sani e salvi. Ben più tragico l’unico “abort” di una missione della NASA, l’esplosione della navetta Shuttle “Challenger” dopo 73 secondi dal lancio, con la morte dei sette astronauti a bordo.
I due sfortunati cosmonauti della missione Soyuz 18-A Oleg Makarov (a sinistra nella foto) e Vasili Lazarev. (fonte: Spacefacts).
La notizia del fallimento del lancio della Soyuz a pag. 12 del quotidiano con uscita pomeridiana Stampa Sera, datato 7 aprile 1975 (dalla collezione personale di Gianluca Atti).
Il mancato raggiungimento in orbita della Soyuz di Makarov e Lazarev nell’edizione del mattino de “La Stampa” dell’8 aprile 1975 (dalla collezione personale di Gianluca Atti).
Massimo Polidoro, amico e collega da una vita, mi ha invitato a partecipare al suo Gomitolo Atomico e ne è venuta fuori una bella chiacchierata sulla scienza, lo spazio, la vita (extraterrestre) e tutto quanto (cit.), parlando anche di Niente panico, per ora, la traduzione italiana dell’autobiografia dell’astronauta lunare Fred Haise di Apollo 13 (edita da Cartabianca Publishing). Il link diretto alla puntata su YouTube è questo.
Autocorrezioncella: il motto della missione Apollo 13 è Ex Luna, Scientia, non ex astris scientia come dico nel podcast.
Puntuale sulla tabella di marcia è partita dal Centro spaziale Kennedy questa notte, quando in Italia erano le 03:46 di martedì primo aprile 2025, la navicella spaziale Dragon “Resilience” con a bordo due uomini e due donne. Il distacco è avvenuto dalla storica rampa di lancio 39-A, la stessa che ha visto partire le missioni umane verso la Luna nel corso del programma Apollo negli anni sessanta e settanta del secolo scorso.
La partenza, come sempre quando si tratta di un lancio notturno, è stata spettacolare e per alcuni istanti il propellente che usciva dal primo stadio del Falcon IX ha illuminato a giorno il cielo buio della Florida. Nello stato orientale americano erano infatti le 21:46.
Il volo di ”Fram 2” è una novità storica per l’astronautica: nessuna missione umana nello spazio aveva fino ad ora sorvolato i poli terrestri. I quattro astronauti non professionisti a bordo di “Resilience” (Chun Wang, imprenditore e finanziatore della spedizione, la regista norvegese Jannicke Mikkelsen, la ricercatrice tedesca Rabea Rogge e l’australiano Eric Philips, esperto guida nelle esplorazioni polari), sono i primi a viaggiare in orbita intorno alla Terra con una inclinazione di 90 gradi, consentendo un sorvolo da un’altezza superiore ai 400 chilometri dei poli Nord e Sud del nostro pianeta.
Da ricordare che oltre alle osservazioni e allo studio delle due regioni polari verrà effettuata all’interno della Dragon una serie di esperimenti scientifici sugli effetti della microgravità sul corpo umano e verrà realizzata, per la prima volta, una radiografia su un essere umano nello spazio.
Il rientro a Terra della Dragon “Resilience” è previsto per la giornata di venerdì 4 aprile dopo cinque giorni di permanenza nello spazio.
Questo è il testo della puntata del 31 marzo 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Il crepitio dei tasti di un programmatore che scrive codice per comporre un programma è probabilmente uno dei suoni più caratteristici dell’informatica. Da decenni, saper programmare significa avere pieno potere, avere la facoltà di far fare quello che si vuole al computer o tablet o telefono che sia, poter creare app, senza dover dipendere da nessuno. Ma quel potere richiede studio e impegno: bisogna imparare i linguaggi di programmazione, ciascuno con una sintassi e delle regole differenti, e per molte persone questo non è facile o è semplicemente impossibile. Programmare resta così un’arte praticata da pochi e ammirata a rispettosa distanza dai più.
Tutto questo, però, sta forse per cambiare improvvisamente. Se state pensando di diventare programmatori o sviluppatori, o se siete genitori e pensate che far studiare gli arcani incantesimi della programmazione sia la strada maestra per una carriera informatica garantita per i vostri figli, ci sono due parole che vi conviene conoscere: vibe coding.
Sono due parole che sono state abbinate per la prima volta solo due mesi fa e stanno già trasformando profondamente il modo in cui si crea il software. Non lo si scrive più tediosamente riga per riga, istruzione per istruzione, ma lo si descrive, in linguaggio naturale, semplicemente parlando. Le macchine fanno il resto. O almeno così sembra.
Questa è la storia, breve ma intensa, del vibe coding, di cosa significa esattamente, di chi ha coniato questo termine, e del perché tutti i grandi nomi dell’informatica stanno correndo per reinventarsi, per l’ennesima volta, inseguendo questo mantra.
Benvenuti alla puntata del 31 marzo 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Questa storia inizia esattamente il 3 febbraio scorso, quando in Europa è passata da poco la mezzanotte. Andrej Karpathy, ex direttore per l’intelligenza artificiale di Tesla, cofondatore di OpenAI (quella di ChatGPT, per intenderci) e una delle menti più influenti nel settore, pubblica su X un post nel quale descrive un nuovo modo di scrivere codice di programmazione usando toni quasi poetici, perlomeno per un informatico: lui si “abbandona alle vibrazioni” e “dimentica persino che esiste il codice”. Karpathy crea programmi parlando ad alta voce, “praticamente senza mai toccare la tastiera”, dice, lasciando che il riconoscimento vocale e l’intelligenza artificiale traducano le sue istruzioni verbali in righe di codice di programmazione.
Karpathy descrive il concetto generale, il cosiddetto vibe, la “vibrazione” appunto, di quello che vuole ottenere,e lascia che sia il computer a fare il lavoro di manovalanza: quello di trasformare quel concetto in software, ossia di fare il coding, la scrittura del codice secondo le regole del linguaggio di programmazione desiderato.
Senza volerlo, Andrej Karpathy ha coniato un termine, vibe coding, che di colpo ha dato un nome facile e accattivante a una tendenza già in atto nel mondo della programmazione da quando è diventato evidente che le intelligenze artificiali sono in grado di generare codice di programmazione con la stessa facilità con la quale generano testi, suoni e immagini.
E così milioni di tastiere crepitanti sono cadute, quasi all’unisono nel silenzio, abbracciando il vibe coding. Le aziende cercano disperatamente i vibe coder, ossia le persone capaci di generare in poche ore fiumi di codice che prima avrebbero richiesto giorni o settimane. I programmatori tradizionali si sentono improvvisamente come un calamaio di fronte a una biro.
Questo modo di scrivere software, di creare gli elementi fondamentali che determinano il funzionamento di tutti i dispositivi elettronici che usiamo, dai televisori alle automobili, dalle macchine per radiografie ai sistemi di gestione della contabilità, della sanità e del fisco, è un cambiamento enorme.
La maniera tradizionale di sviluppare codice richiede la conoscenza dettagliata dei linguaggi di programmazione e della loro pignola, implacabile sintassi. Una lettera fuori posto, una parentesi di troppo o una di meno, un parametro indicato nell’ordine sbagliato, e non funziona più niente. Ma l’intelligenza artificiale sta cambiando questo approccio, introducendo degli assistenti alla creazione di codice che sono in grado di interpretare la descrizione di un problema, espressa in parole comuni (anche in italiano), e generare del codice che funziona.
Non c’è più bisogno di studiare e ricordare tutti i vari linguaggi informatici: basta esprimersi in modo naturale in una sola lingua, quella che si usa tutti i giorni. Programmare non è più un’arte oscura riservata a una élite, ma arriva alla portata di tutti.
Le persone che hanno idee creative ma non hanno esperienza di programmazione possono ora creare dei prototipi descrivendo a un’intelligenza artificiale cosa hanno in mente. Come dice sempre Andrej Karpathy nel suo ormai storico post, “non sto scrivendo codice – semplicemente vedo cose, dico cose, eseguo cose, e copio e incollo cose, e grosso modo funziona”.
Chi ha esperienza di sviluppo e programmazione, invece, può usare questi strumenti per automatizzare le parti ripetitive della creazione di un programma e diventare più veloce. Le porzioni standard di un software, cose come per esempio una finestra di immissione di dati o di conferma di un codice di accesso, vengono generate dall’intelligenza artificiale, mentre lo sviluppatore si concentra sulla progettazione generale ad alto livello, riducendo drasticamente i tempi di lavoro.
Ma in pratica come funziona tutto questo?
Il vibe coding è un duetto: le persone forniscono istruzioni, descrizioni e obiettivi usando il proprio linguaggio naturale, e gli strumenti di intelligenza artificiale, che sono stati addestrati alimentandoli con enormi quantità di codice e di informazioni di programmazione, traducono tutto questo in una prima bozza di codice.
Le istruzioni fornite sono estremamente semplici e intuitive: cose come “crea un sito che gestisca le prenotazioni, dove i clienti possono vedere quando io sono disponibile e pianificare gli appuntamenti. Il sito deve mandare e-mail di conferma e di promemoria”. Tutto qui. A tutto il resto provvede l’intelligenza artificiale.
È un modo di lavorare iterativo e interattivo, che avanza per affinamenti progressivi: la persona prova la prima bozza e poi chiede alla IA di modificare il codice, descrivendo sempre in linguaggio naturale cosa deve cambiare: per esempio come deve comportarsi il programma se l’utente immette un valore non ammesso e cosa va visualizzato sullo schermo. La persona prova questa seconda bozza e la affina ancora descrivendo le modifiche da fare, e la IA le fa. Il ciclo continua così fino a che il software funziona e il creatore è soddisfatto del risultato. Dato che l’intelligenza artificiale scrive il codice molto più velocemente di qualunque essere umano, è facile effettuare varie passate di affinamento in pochissimo tempo.
L’intelligenza artificiale è anche in grado di correggere eventuali difetti nel codice che ha generato. Quando un software non funziona correttamente, produce un messaggio di errore. Nel vibe coding, il creatore di programmi (che è difficile definire programmatore a questo punto) non analizza l’errore come farebbe tradizionalmente: copia e incolla il messaggio di errore nella chat che sta facendo con l’intelligenza artificiale e lascia che sia questa IA a leggerlo e a trovare e applicare la soluzione opportuna. Anche perché nel vibe coding la persona che sta creando il programma spesso non conosce il linguaggio di programmazione usato e quindi non è in grado di capirne gli errori e correggerli.
Le intelligenze artificiali da adoperare per fare queste cose possono essere specialistiche, come GitHub Copilot, Windsurf AI, Replit e Cursor, oppure intelligenze artificiali generaliste come ChatGPT e Claude, per esempio, che sono in grado di generare anche codice di programmazione.
Ovviamente alle aziende tutto questo fa molta gola, perché promette di ridurre tempi e costi. Con il vibe coding, argomentano, non servono squadre di costosi e supercompetenti programmatori, ma è sufficiente pagare una sola persona con qualifiche più modeste e con pretese economiche altrettanto modeste.
Dario Amodei, fondatore e CEO di Anthropic, l’azienda che ha sviluppato Claude, dice che “non siamo lontani – ci arriveremo fra tre o sei mesi – da un mondo nel quale l’intelligenza artificiale scrive il 90% del codice. Fra dodici mesi potremmo trovarci in un mondo nel quale la IA scrive praticamente tutto il codice.”
I sostenitori di questo nuovo modo di programmare citano come esempio di successo del vibe coding il fatto che il giornalista del New York Times Kevin Roose, che non è un esperto di programmazione, è riuscito a creare numerose applicazioni usando questa tecnica e lo ha raccontato in un seguitissimo articolo.
Un altro esempio molto popolare è il sito fly.pieter.com, che contiene un gioco online (un simulatore di volo molto schematico) che stando al suo creatore, Pieter Levels, guadagna oltre 50.000 dollari al mese vendendo spazi pubblicitari all’interno del mondo virtuale nel quale si svolge l’azione. L’intero gioco è stato realizzato da Levels, da solo e usando l’intelligenza artificiale come assistente, in mezz’ora. Un risultato inimmaginabile con i metodi tradizionali.
Su Internet fioriscono siti che tentano di imitare il successo di Pieter Levels creando in poco tempo videogiochi giocabili anche se poco raffinati, nella speranza di guadagnare qualche soldo. Ma Levels è stato il primo e ha un seguito molto grande sui social network che può proporre ai suoi inserzionisti, mentre chi arriva dopo e lo imita non ha nulla di tutto questo, per cui ha ben poche probabilità di monetizzare la sua pur modesta fatica.
In ogni caso il vibe coding sembra funzionare. Ma prima di buttar via i manuali di programmazione e pensare che basti saper parlare per poter creare programmi, ci sono alcune cose da sapere. Come al solito, quello che sembra troppo bello per essere vero finisce prima o poi per dimostrare di non essere vero.
Il primo problema di questa nuova mania della Silicon Valley è la sua filosofia di base: il creatore del codice non solo non ha bisogno di capirlo, ma anzi capirlo è proprio contrario all’essenza del vibe coding: in realtà non deve essere un creatore ma un utente del codice, e deve accettare quel codice generato dalla IA senza capirlo appieno, altrimenti sta facendo solo programmazione assistita. E questo requisito di non comprendere il codice significa che se il programma non funziona e l’intelligenza artificiale non riesce a sistemarlo, l’aspirante creatore è incapace di intervenire.
Il secondo problema deriva dal primo: anche se il programma creato con il vibe coding sembra funzionare nella maggior parte dei casi, può contenere errori o difetti nei suoi princìpi di funzionamento che emergono solo in casi specifici. Può contenere falle di sicurezza, e modificarlo per manutenzione o aggiornamento è rischioso. Senza una costosa analisi esperta di come funziona, è impossibile sapere come intervenire, e far fare l’intervento all’intelligenza artificiale significa rischiare di introdurre ulteriori errori e incognite, perché la IA non “capisce” in senso stretto cosa sta facendo ma si limita a generare codice statisticamente probabile nel contesto.
Questo è un approccio che può andar bene per creare da zero un prototipo di software, a scopo dimostrativo, qualcosa di semplice per uso personale. Ma gran parte del lavoro degli ingegneri informatici non è di questo genere. Di solito si tratta di interventi su software complesso e preesistente, nel quale la comprensione e la qualità del codice sono fondamentali. Per intervenire su un software di contabilità, per esempio, bisogna capirne non solo il linguaggio informatico, ma anche i princìpi contabili sui quali si basa. E questo l’intelligenza artificiale attuale non lo fa.
Per fare un paragone, il vibe coding applicato a un software già esistente è l’equivalente di un idraulico che invece di studiarsi e capire lo schema dell’impianto sul quale deve intervenire sa che nella maggior parte dei casi che ha visto nella sua carriera le cose miglioravano chiudendo a metà le valvole sui tubi di mandata dispari. Non sa perché, ma di solito funziona. Affidereste il vostro impianto idraulico di casa, o quello di un’intera azienda o di un intero paese, a qualcuno che lavorasse in questo modo?
Probabilmente no. Eppure è esattamente quello che vuole fare Elon Musk, nel suo nuovo ruolo politico, con uno dei software più complessi e ingarbugliati del pianeta: quello che gestisce la previdenza sociale delle persone residenti negli Stati Uniti. Questo software è composto da oltre 60 milioni di righe di codice scritto in COBOL, che è un linguaggio di programmazione creato settant’anni fa, e da milioni di ulteriori righe scritte in altri linguaggi ormai arcaici. L’ultimo aggiornamento importante dei suoi componenti centrali risale agli anni Ottanta del secolo scorso.
Questo è il software che gestisce, fra le altre cose, i pagamenti di previdenza sociale erogati a oltre 65 milioni di persone. Metterci mano senza un’analisi preliminare molto attenta, senza una profonda comprensione del codice che permetta di capire gli effetti a catena di qualunque modifica, significa rischiare di interrompere i pagamenti a milioni di persone che dipendono dalla propria pensione per vivere. Nel 2017 l’agenzia per la previdenza sociale statunitense, che è responsabile di tutto questo sistema, aveva stimato che un ammodernamento dei suoi componenti centrali avrebbe richiesto circa cinque anni. Elon Musk ha dichiarato che vuole farlo nel giro di pochi mesi. Ma l’unico modo per farlo in tempi così stretti è usare l’intelligenza artificiale e rinunciare alle analisi e ai collaudi che normalmente si fanno in situazioni come questa. Cosa mai potrebbe andare storto?
Morale della storia: il vibe coding è un’idea interessante, applicabile in alcuni casi quando le conseguenze di un errore di programmazione non sono gravi e si vuole creare un prototipo che “grosso modo funzioni”, per citare le parole di Andrej Karpathy, ma non può per ora sostituire la competenza di un essere umano che conosce i linguaggi di programmazione e comprende la logica che sta dietro qualunque programma. Non è ancora giunto il momento di buttare via i libri e i manuali, insomma.
Pochi giorni fa ho chiesto a uno sviluppatore che ho incontrato cosa ne pensasse di questa moda del vibe coding, e lui mi ha detto che ne è entusiasta. Non perché lo usi, ma perché sa che avrà più lavoro di prima: quello necessario per correggere i disastri combinati da chi lo usa pensando che ignoranza più IA equivalga a conoscenza, competenza e intelligenza.
È andata in onda stamattina alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
Ecco gli appuntamenti di aprile dove potrete vedere e sentire Paolo:
3 aprile – Lugano – USI palazzo rosso del Campus Ovest, Aula 22 (via Buffi 13), ore 20: si parlerà di uso consapevole di social e intelligenza artificiale. Organizzato dalla Conferenza Cantonale dei Genitori. Per ulteriori informazioni consultare il sito www.genitorinforma.ch
4 aprile – partecipazione a Patti Chiari – trasmissione settimanale della RSI su La1, ore 20.40: si parlerà di truffe informatiche.
12 aprile – Lucerna – Centro Parrocchiale St. Karl, Spitalstrasse 91, ore 16: si parlerà di intelligenza artificiale. Evento organizzato dalla Società Dante Alighieri di Lucerna. Per informazioni: www.dantelucerna.ch
13 aprile – Horgen – Missione Cattolica di Lingua Italiana, Zimmerberg, Burghaldenstr. 7, ore 15: si parlerà di intelligenza artificiale. Evento organizzato dalla Società Dante Alighieri del cantone Svitto. Per informazioni: www.mcli.ch/zimmerberg
Centro spaziale Kennedy. È previsto quando in Italia sarà piena notte (il conto alla rovescia dovrebbe terminare alle 03:46 di martedì 1 aprile 2025 salvo inconvenienti tecnici o meteorologici dell’ultimo momento) il lancio dalla storica rampa di lancio 39-A della Dragon “Resilience” con a bordo un equipaggio di quattro persone in una missione denominata “Fram-2”. Per la storia dell’Astronautica è questa la prima missione spaziale con equipaggio in orbita polare.
“Fram-2” prende il nome dalla storica nave norvegese Fram, che completò diverse spedizioni nelle regioni artiche e antartiche tra il 1893 e il 1912. I quattro futuri astronauti sono due uomini e due donne: nessuno di loro ha ancora volato nello spazio. Si tratta di Chun Wang, nato in Cina ma imprenditore maltese e comandante della missione; la norvegese Jannicke Mikkelsen, comandante di “Resilience”; l’australiano Eric Philips come pilota; e la tedesca Rabea Rogge come specialista di missione. Saranno i primi a viaggiare su un’orbita con inclinazione di 90 gradi, consentendo loro di sorvolare direttamente i poli Nord e Sud del nostro pianeta.
La capsula è dotata di una cupola per consentire l’osservazione della Terra da un’altitudine di 425 – 450 km. Oltre all’osservazione delle regioni polari, i quattro effettueranno una serie di esperimenti scientifici, tra cui alcuni studi sugli effetti della microgravità sul corpo umano; inoltre durante i cinque giorni di volo previsti sarà realizzata per la prima volta la prima radiografia di un essere umano nello spazio. La Dragon “Resilience” sarà lanciata in orbita intorno alla Terra da un razzo Falcon di SpaceX.
Tra poco andrò con la Dama del Maniero all’edizione 2025 di Starmus, il festival di scienza e musica che quest’anno si tiene alle Canarie dal 25 al 29 aprile. L’anno scorso siamo andati a Bratislava per assistere alle conferenze di scienziati di altissimo livello e ai concerti di Jean-Michel Jarre, Tony Hadley, Brian May, Offspring e tanti altri artisti che tradizionalmente caratterizzano ogni edizione di Starmus (ne ho scritto qui a suo tempo).
I video delle conferenze scientifiche dell’anno scorso sono stati pubblicati online; comincio a presentarli qui uno alla volta, partendo dall’inizio: il discorso della primatologa Jane Goodall, intitolato Reasons for Hope, ossia “motivi di speranza”. Se per caso non sapete chi è Jane Goodall, preparatevi a scoprire una storia straordinaria.
Con le dimostrazioni di arroganza e stupidità collettiva che ci arrivano addosso continuamente, soprattutto in questo periodo, è difficile avere il coraggio di mantenere accesa la luce della speranza. Spero che le splendide parole della novantenne Jane Goodall possano dare una mano.
Includo qui sotto la mia traduzione (bozza creata da DeepL, riveduta da me) e la mia revisione dei sottotitoli di YouTube, che contenevano (e tuttora contengono) perle come “Jane has worked extensively on conservation and anal welfare” (a 30 secondi esatti dall’inizio).
Traduzione italiana
David Eicher: È raro che un settore della scienza sia rappresentato così bene da una sola persona. Ma è il caso di Jane Goodall, la più importante primatologa del mondo e la maggiore esperta, tra le altre cose, di scimpanzé. Fondatrice del Jane Goodall Institute, Jane ha lavorato a lungo per la conservazione e il benessere degli animali. È Messaggero di Pace delle Nazioni Unite e membro onorario del World Future Council, e ora, come ho detto, è felicemente membro del comitato consultivo di Starmus. Con il suo discorso, “Motivi di speranza”, diamo il benvenuto alla leggendaria Jane Goodall.
[standing ovation]
Jane Goodall: Beh, grazie per il fantastico benvenuto, penso che vi meritiate un benvenuto piuttosto diverso da quello che avete mai sentito prima. Il richiamo che sentireste, il benvenuto degli scimpanzé che ho passato tanto tempo a studiare.
[vocalizzi da scimpanzé]
Goodall: Io Jane. Beh, prima di tutto sono molto onorata di essere qui a questo Starmus Earth. È la prima volta che partecipo. Sono molto onorata di essere stata invitata nel comitato consultivo e sono particolarmente entusiasta che lo Starmus di quest’anno si concentri sul nostro pianeta natale. Uno dei miliardi e miliardi di pianeti che forse sono là fuori nel cosmo. Ma non è affascinante che sia grazie alla nostra esplorazione dello spazio che abbiamo ottenuto la prima splendida immagine del nostro pianeta Terra, quel bellissimo pianeta verde e blu, scattata dallo spazio? È a quel punto, credo, che la gente ha iniziato a rendersi conto che questo è un pianeta molto fragile.
Ed eccoci qui, che ruotiamo intorno al Sole, un pianeta molto piccolo circondato dall’immensità nera e buia dello spazio. E penso che sia stato un campanello d’allarme; è stato un campanello d’allarme per le persone sulla Terra per rendersi conto che questa è la nostra unica casa. È meglio che iniziamo a proteggere il pianeta. E nel corso dei secoli, probabilmente dalla rivoluzione industriale, forse dalla rivoluzione agricola, abbiamo lentamente inflitto sempre più danni a questo pianeta, la nostra unica casa, e con la combustione di combustibili fossili e tutte le altre cose che abbiamo fatto per creare quei gas serra, quei gas che circondano il pianeta come una coperta e intrappolano il calore del sole che ha portato al cambiamento climatico.
E il cambiamento climatico è inseparabile dalla perdita di biodiversità, e con il cambiamento climatico abbiamo assistito a questi terrificanti cambiamenti nei modelli meteorologici in tutto il mondo, tempeste e uragani sempre più frequenti e più violenti, inondazioni, siccità e ondate di calore, e i terrificanti incendi boschivi che abbiamo visto in tante parti del globo, comprese le zone settentrionali dove gli incendi non avevano mai bruciato prima.
E abbiamo visto sciogliersi i ghiacciai e il ghiaccio; abbiamo visto il livello del mare salire, abbiamo visto il metano fuoriuscire dal terreno che era stato congelato per migliaia e migliaia di anni… e ci sono tanti altri modi in cui abbiamo danneggiato questo pianeta.
Il cambiamento climatico non è qualcosa che affronteremo in futuro, il cambiamento climatico è qui, ora. Non solo in luoghi come il Bangladesh e i paesi a bassissima elevazione, ma anche nei paesi economicamente più sviluppati abbiamo assistito a terribili inondazioni a Londra, a New York e anche in alcune parti d’Europa.
E poi c’è la perdita di biodiversità. Siamo nel bel mezzo della sesta grande estinzione del pianeta Terra, e questa è stata causata da noi. E siamo in un momento molto, molto difficile, e quello che facciamo ora influenzerà il futuro della vita sul pianeta Terra. E ci vedo come all’imboccatura di un tunnel molto lungo e molto buio e proprio alla fine di quel tunnel c’è una piccola stella che brilla. Questa è la speranza.
Ma non possiamo sederci all’imbocco del tunnel a braccia conserte e sperare che quella stella ci venga incontro. No, dobbiamo rimboccarci le maniche, dobbiamo arrampicarci, strisciare sotto, aggirando tutti gli ostacoli che si frappongono tra noi e quella stella.
E ci sono quelli più ovvi, come il cambiamento climatico e la perdita di biodiversità, che ho già menzionato e credo che ne conosciamo bene le ragioni, e l’agricoltura industriale con il suo enorme uso di combustibili fossili, l’uso di pesticidi chimici ed erbicidi e fertilizzanti artificiali che stanno avendo un effetto drammatico sulla biodiversità e stanno uccidendo il suolo stesso da cui dipendiamo.
E i fertilizzanti artificiali che vengono scaricati nei fiumi e finiscono nel mare stanno causando zone morte dove nulla può vivere. Non possiamo continuare così, vero? E ci sono tanti altri problemi che affrontiamo mentre procediamo, mentre navighiamo attraverso questo tunnel. C’è l’allevamento intensivo di animali – e lì dobbiamo pensare non solo al danno per l’ambiente, che è enorme, ma alla crudeltà: la crudeltà coinvolta.
E sapete, è stato proprio grazie a quei primi studi che ho fatto sugli scimpanzé che hanno contribuito a cambiare gli atteggiamenti verso ciò che – verso chi – gli animali sono realmente. Quando sono arrivata all’Università di Cambridge nel 1961, mi è stato detto che solo gli esseri umani avevano personalità, solo gli esseri umani avevano menti capaci di risolvere problemi e solo gli esseri umani avevano emozioni come la felicità, la tristezza, la paura.
Fortunatamente, quando ero bambina, avevo avuto un insegnante straordinario che mi aveva insegnato che, sotto questo aspetto, quegli scienziati si sbagliavano. Quell’insegnante era il mio cane Rusty. Non si può condividere la propria vita con un animale e non sapere che non siamo gli unici esseri senzienti e intelligenti del pianeta.
Quindi ora sappiamo che mucche, maiali, capre, pecore, polli sono tutti individui con una personalità. Quindi quando pensiamo all’allevamento intensivo degli animali, pensiamo anche alla crudeltà. Pensiamo che ora sappiamo di far parte di questo incredibile regno animale, non di esserne separati. E naturalmente impariamo sempre di più su quanto siano incredibili questi animali.
Poi dobbiamo scavalcare o strisciare sotto la povertà. Le persone che vivono in povertà distruggono l’ambiente nella loro disperata lotta per la sopravvivenza, abbattendo gli alberi per guadagnare qualche soldo o per coltivare cibo per le loro famiglie affamate, e finché non saremo in grado di alleviare la povertà non potremo mai avere un mondo in cui le persone decidano di acquistare solo prodotti che non hanno danneggiato l’ambiente o che non sono stati crudeli con gli animali, perché i poveri non possono fare questo tipo di scelta. Ma il resto di noi può fare qualcosa per il proprio stile di vita insostenibile. E come è possibile che gli economisti abbiano pensato che possiamo avere uno sviluppo economico illimitato su un pianeta con risorse naturali limitate e popolazioni umane e animali in crescita? Non ha senso.
Dobbiamo avere un nuovo modo di pensare, una nuova mentalità, e poi dobbiamo anche considerare la corruzione, che sta distruggendo gli sforzi di così tante persone per cambiare le cose. E ora abbiamo la guerra: due grandi guerre, conflitti in tutta l’Africa, conflitti in altre parti del mondo, che danneggiano l’ambiente, causando orribili sofferenze a centinaia e migliaia di esseri umani. Abbiamo discriminazioni razziali e di genere, così tante cose da superare.
Buone notizie: ci sono persone, gruppi di persone, che stanno affrontando ognuno di questi problemi, quelli che ho menzionato e tutti quelli che non ho menzionato. Purtroppo molti di questi gruppi lavorano in modo isolato. Non pensano al quadro generale, risolvono un problema e non pensano agli altri problemi che potrebbero causare, come le auto elettriche – incredibili – che risolvono l’inquinamento e tutto il resto, ma hanno bisogno… le batterie hanno bisogno di litio, e enormi aree ambientali vengono ora distrutte per trovare litio durante l’estrazione.
Quindi la gente mi dice: “Jane, lei ha visto così tanti di questi problemi. Ha davvero speranza?”
E io ce l’ho! Credo che abbiamo ancora un po’ di tempo. Ma quando dico che ho speranza, dipende da noi. Dobbiamo unirci e cercare di fare la differenza. Non dobbiamo lasciare che siano gli altri a farlo. Dipende da noi.
Ma le ragioni principali per cui ho speranza sono queste: innanzitutto, c’è la scienza, e molti scienziati sono qui e sono stati qui agli eventi Starmus. La scienza sta iniziando a trovare modi per utilizzare questo incredibile intelletto che ci rende più diversi di qualsiasi altra cosa dagli scimpanzé e da altri animali che stanno iniziando a usare quell’intelletto, per creare modi in cui possiamo vivere in maggiore armonia con la natura. E questo si sta evolvendo continuamente, e ci saranno altre persone che vi parleranno dei benefici del nostro intelletto e delle nostre nuove tecnologie che possono aiutarci. Ma anche noi, come individui, pensiamo alle nostre impronte ambientali ogni giorno; ogni giorno, ognuno di noi può fare la differenza.
E quindi la mia prossima ragione di speranza è la resilienza della natura. Possiamo distruggere dei luoghi, ma se diamo loro tempo e forse un po’ di aiuto, la natura tornerà. Ho notato che il Danubio, che era così orribilmente inquinato in epoca sovietica, sta gradualmente iniziando a riprendersi, anche se potrebbe volerci molto tempo. Ma in tutto il mondo ho visto con i miei occhi luoghi che erano stati completamente distrutti da noi, dove la natura è tornata e con le prime erbe e poi gli alberi che crescono dai semi lasciati nel terreno, gli insetti tornano, e gli uccelli e gli altri mammiferi, e gradualmente ritorna la biodiversità… Forse non esattamente la stessa, ma diventa di nuovo un ecosistema vivo e fiorente.
Ho incontrato animali che sarebbero dovuti estinguersi se non fosse stato per persone straordinarie che hanno detto: “No, non lascerò che l’ibis eremita si estingua sotto i miei occhi; non lascerò che il merlo della Nuova Zelanda si estingua”.* Erano rimasti solo due uccelli, un maschio e una femmina, e grazie alla passione di un uomo ora sono più di 150.
* non sono sicuro della traduzione dei nomi di questi volatili. Il primo dovrebbe essere un Geronticus eremita; il secondo dovrebbe essere un Petroica traversi. Ringrazio Martino per le ricerche [N.d.T.].
Ed è incredibile quello che possiamo fare. E c’è questo spirito indomito con cui le persone affrontano ciò che sembra impossibile e non si arrendono.
Ma la mia più grande speranza risiede nei giovani di oggi. E nel 1991, quando incontravo tanti giovani, delle scuole superiori, delle università, che già allora avevano perso la speranza ed erano arrabbiati o depressi o per lo più semplicemente apatici, non sembrava importare loro. E quando ho chiesto loro: “Perché vi sentite così?” “Beh, avete compromesso il nostro futuro e non possiamo farci nulla”.
Abbiamo compromesso il futuro dei nostri giovani? Lo abbiamo rubato, e lo stiamo ancora rubando oggi.
Ma era vero che non potevano farci nulla? No. Ho già detto che c’è un periodo di tempo in cui, se ci uniamo, possiamo davvero fare la differenza. Roots and Shoots [radici e germogli, N.d.T.], il programma che ho avviato, è rivolto ai giovani dall’asilo all’università, con la partecipazione di un numero crescente di adulti. È iniziato con dodici studenti delle scuole superiori in Tanzania, ora è presente in settanta paesi con, come ho detto, persone di tutte le età; anche gli adulti ora stanno formando gruppi, e sta crescendo qui in Slovacchia.
E questi giovani, una volta che hanno compreso i problemi e che noi diamo loro la possibilità di agire, e Roots and Shoots è tutto incentrato sul dare potere ai giovani e ascoltare le loro voci, sono in grado di cambiare il mondo. Ed è incredibile che stiano cambiando il mondo proprio mentre vi parlo oggi.
Ma l’ultima cosa che vorrei dire a tutti voi è che non dovete dimenticare che, come individui, avete un ruolo da svolgere. Credo che ci sia una ragione per cui siete su questo pianeta e ogni singolo giorno che vivete avete un impatto sul pianeta.
La gente mi dice: “Ma Jane, io sono solo una singola persona, i problemi sono enormi, cosa posso fare?” È come… Pensate a un deserto. Una goccia di pioggia che cade non fa alcuna differenza. Ma quando milioni o miliardi di gocce di pioggia cadono, risvegliano la vita nascosta sotto la sabbia, che fiorisce, e il deserto prende vita. Questo è ciò che i nostri giovani possono fare. Questo è ciò che tutti voi potete fare. Ricordate: insieme possiamo cambiare il mondo. Grazie.
Originale inglese
David Eicher: So rarely is an area of science represented so well by one person. But that’s the case with Jane Goodall, the world’s leading primatologist and the leading expert, among other things, on chimpanzees. Founder of the Jane Goodall Institute, Jane has worked extensively on conservation and animal welfare. She’s a United Nations Messenger of Peace and an honorary member of the World Future Council, and now happily – as I mentioned – a member of the Starmus advisory board. With her talk, “Reasons for Hope,” please welcome the legendary Jane Goodall.
[standing ovation]
Jane Goodall: Well, thank you for a fantastic welcome, and I think you deserve a rather different kind of welcome than has ever been heard here before. The call that you would hear, the welcome from the chimpanzees that I spent so much of my time learning about.
[vocalizzi da scimpanzé]
Goodall: Me Jane. Well, first of all I’m very honored to be here at this Starmus Earth. It’s the first time I’ve attended. I’m very honored to have been invited onto the Advisory Board and I’m particularly thrilled that this year’s Starmus is concentrating on our home planet. One of the maybe billions and billions of planets that are out there in the cosmos. But isn’t it fascinating that it’s because of our exploration into space that we got that first stunning image of our own planet Earth – that beautiful green and blue planet – taken from space. And then, I think, people began to realize this is a very fragile planet.
And there we are, spinning around the Sun, a very small planet surrounded by the black dark immensity of outer space. And I think that was a wakeup call; it was a wakeup call for people on Earth to realize this is our only home. We we’d better start protecting the planet. And over the ages, probably since the Industrial Revolution, maybe since the Agricultural Revolution, we have slowly been inflicting more and more harm upon this planet, our only home, and with our burning of fossil fuels and all the other things that we’ve done to create those greenhouse gases – those gases that circle the planet like a blanket and trap the heat of the sun that’s led to climate change.
And climate change is inseparable from loss of biodiversity, and with climate change we’ve seen these terrifying changes in weather patterns around the world, worse and more frequent storms and hurricanes and flooding and droughts and heat waves, and the terrifying forest fires that we have seen in so many parts of the globe including up in the northern areas where fires never burnt before.
And we’ve seen glaciers and ice melting; we’ve seen sea levels rising, we’ve seen the methane leaking out from the ground that was frozen for thousands and thousands of years… and there are so many other ways in which we’ve harmed this planet.
Climate change isn’t something that we’re facing in the future – climate change is here, here and now. Not only in places like Bangladesh and low-lying countries, but in the more economically developed countries we’ve seen terrible flooding in London, and in New York, and in parts of Europe as well.
And then there’s the loss of biodiversity. We are in the midst of the sixth great extinction on planet Earth, and this one was caused by us. And we are at a very, very difficult point in time, and what we do now is going to affect the future of life on planet Earth. And I see us as like at the mouth of a very long and very dark tunnel and right at the end of that tunnel is a little star shining. That’s hope.
But we don’t sit at the mouth of the tunnel with our arms crossed and hope the star will come to us. No, we have to roll up our sleeves, we have to climb over, crawl under, work our way around all the obstacles that lie between us and that star.
And there are the obvious ones, like climate change and loss of biodiversity, that I’ve mentioned and I think we mostly know the reasons for that, and industrial agriculture with its huge use of fossil fuel, its use of chemical pesticides and herbicides and artificial fertilizer that are having a dramatic effect on biodiversity and actually killing the very soil on which we depend.
And the the artificial fertilizers that washed down into the rivers and out into the sea are causing dead zones where nothing can live. We can’t go on like this, can we? And there are so many other problems that we face as we go, navigate through this tunnel. There’s the intensive farming of animals – and there we have to think not only of the harm to the environment, which is huge, but the cruelty: the cruelty involved.
And you know, it was really because of those early studies that I did on chimpanzees that have helped to change attitudes towards what – who – animals really are. When I got to Cambridge University in 1961, I was actually told that only human beings had personalities, only human beings had minds capable of solving problems, and only human beings had emotions like happiness, sadness, fear.
Fortunately I’d been taught by an amazing teacher, when I was a child, that in this respect these scientists were wrong. That teacher was my dog Rusty. You can’t share your life with any animal and not know that we are not the only sentient, sapient beings on the planet.
So we now understand that cows, pigs, goats, sheep, chickens – they all are individuals with personalities. So when we think about intensive animal farming, let us please also think about cruelty. Let us think that we now understand we are part of, and not separate from, this amazing animal kingdom. And of course all the time we’re learning more and more details about exactly how amazing these animals are.
Then we have to climb over or crawl under poverty. People living in poverty, they destroy the environment in their desperate struggle to survive, cutting down the trees to make money or to grow food for their starving families, and until we can alleviate poverty we can never have a world where people decide only to buy products that haven’t harmed the environment or weren’t cruel to animals, because poor people cannot make those decisions. But the rest of us, we can do something about our unsustainable lifestyles. And how is it possible that economists have thought that we can have unlimited economic development on a planet with finite natural resources and growing populations of humans and livestock? It doesn’t make sense.
We have to have a new way of thinking, a new mindset, and then we also have to consider corruption, which is destroying the efforts of so many people to make change. And now we have war: two major wars, conflicts across Africa, conflict in other parts of the world, harming the environment, causing horrible suffering to so many hundreds and thousands of human beings. We’ve got racial and gender discrimination, so much to overcome.
Good news: there are people, groups of people, tackling every single one of these problems, those I’ve mentioned and all the many that I haven’t. Sadly, so many of these groups are working in isolation. They’re not thinking of the whole picture, they solve one problem and they’re not thinking about other problems which they may be causing, like electric cars – amazing – solving pollution and all that, but they need… the batteries need lithium, and huge areas of environment are now being destroyed to find lithium during mining.
So people say to me, “Jane, you’ve seen so many of these problems. Do you really have hope?”
And I do! I believe we have a window of time. But when I say I have hope, it depends on us. We have to get together and try to make a difference. We mustn’t leave it to others. It’s up to us.
But my main reasons for hope: first of all, there’s science, and many of the scientists are here and have been here at the Starmus events. Science is beginning to find ways using this amazing intellect that makes us more different than anything else from chimpanzees and other animals beginning to use that intellect to create ways in which we can live in greater harmony with nature and this is evolving all the time and there will be other people speaking to you about the benefits of our intellect and our new technologies that can help. But we too, as individuals, please let us think about our own environmental footsteps each day, each day, every single one of us can make a difference.
And so my next reason for hope is the resilience of nature. We can destroy places, and give them time and perhaps some help, nature will return. I gather the Danube, which was so horribly polluted in Soviet times, is gradually beginning to recover, although it may take a long time. But all over the world I have seen with my own eyes places that were totally destroyed by us, where nature has come back and with the first grasses and then the trees growing from seeds left in the ground, the insects come back, and the birds and the other mammals, and gradually biodiversity returns… Maybe not exactly the same, but it becomes once again a living, thriving ecosystem.
I’ve met animals that should have been extinct if it wasn’t for amazing people saying “No, I will not let the northern bald ibis go extinct on my watch; I will not let the New Zealand black robin become extinct.” There were just two birds left, one male and one female, and because of the passion of one man that’s now over 150.
And so it’s incredible what we can do. And there is this indomitable spirit where people tackle what seems impossible and they won’t give up.
But my greatest reason for hope lies in the young people today. And back in 1991, when I was meeting so many young people, high school, university, who already back then had lost hope and they were angry or they were depressed or mostly just apathetic, they didn’t seem to care. And when I asked them, “Why do you feel this way?” “Well, you’ve compromised our future, and there’s nothing we can do about it.”
Have we compromised the future of our young people? We’ve been stealing it; and we’re still stealing it today.
But was it true there was nothing they could do? No. I’ve already said there’s this window of time when if we get get together we can truly make a difference. Roots and Shoots, the program I began, is for young people from kindergarten through university with more adults taking part. It began with twelve students in Tanzania high school students it’s now in seventy countries with, as I say, people of all ages even adults now are forming groups and it’s growing here in Slovakia.
And these young people – once they understand the problems and we empower them to take action, and Roots and Shoots is all about empowering young people, listening to their voices, and it’s incredible – they are changing the world even as I speak to you today.
But the last thing I would say to all of you, please don’t forget you, as an individual, have a role to play. You’re on this planet for a reason, I believe, and every single day that you live you make some impact on the planet.
People say to me, “But Jane, I’m just one person, the problems are huge, what can I do?” It’s like… Think of a desert. One drop of rain falls: that won’t make any difference. But when millions or billions of raindrops fall, that wakes up the life lying hidden beneath the sand and it comes and blooms and the desert comes to life. That’s what our young people can do. That’s what all of you can do. Just remember: cumulatively, we can change the world. Thank you.
1982/03/30. Il terzo volo orbitale dello Space Shuttle Columbia (STS-3) si conclude sulla pista di atterraggio di White Sands in New Mexico, zona scelta per il rientro dopo i danni riportati alla pista di Edwards in California a causa di un violento nubifragio. In Italia le lancette dell’orologio segnano le 18:07.
Nel corso degli otto giorni di missione intorno alla Terra, i due astronauti Jack Lousma e Gordon Fullerton sperimentano il controllo termico della navetta nelle diverse configurazioni di volo e di esposizione al Sole e allo spazio. Inoltre, durante le 130 orbite compiute intorno al nostro pianeta, Lousma e Fullerton utilizzano vari strumenti per le osservazioni astronomiche e per la fisica dei plasmi spaziali.
Lunedì scorso è andata in onda una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera dalle 9 alle 10. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
Ho visto che sui social network ci sono moltissime foto che mostrano una spirale luminescente avvistata nei cieli dell’Europa questa sera intorno alle 21. Si tratta di una scia di propellente sfiatato da un razzo di SpaceX e illuminato dal Sole.
In dettaglio, si tratta del propellente rilasciato dal secondo stadio di un razzo Falcon 9 di SpaceX, partito alle 18.48 (ora dell’Europa centrale) dalla Florida per portare in orbita un satellite militare. La nuvola di propellente riflette il Sole (che alla quota alla quale si trova il veicolo spaziale è ancora sopra l’orizzonte) e forma una spirale perché lo stadio ruota su se stesso mentre sta sfiatando.
Lo stadio è poi rientrato sulla Terra precipitando senza pericolo nell’Oceano Indiano.
Questo tipo di fenomeno non è una novità: lo sfiato avviene a ogni lancio di un razzo (un esempio qui sul mio blog precedente). Tuttavia la spirale diventa visibile soltanto quando ci sono le condizioni giuste di illuminazione: deve esserci buio al suolo ma il Sole deve essere ancora in grado di illuminare la nuvola di gas.
Chiunque parli di fenomeni misteriosi, di presenze aliene, di portali cosmici e via dicendo dimostra solo una di due cose: nel migliore dei casi, la propria ignoranza delle attività spaziali e la propria incapacità di stare zitto quando non sa di cosa parla; nel peggiore dei casi, la propria meschina pochezza nel cercare di acchiappare qualche clic e qualche like creando misteri e allarmi inesistenti invece di informarsi e informare.
Questo è il testo della puntata del 24 marzo 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: “Vedo la gente morta” da Il Sesto Senso (1999)]
Facebook, Instagram, WhatsApp, Messenger stanno introducendo anche in Europa gli assistenti virtuali basati sull’intelligenza artificiale. I risultati di Google oggi vengono generati anche con l’intelligenza artificiale, spesso con effetti involontariamente comici. I siti di commercio usano dei chatbot per rispondere automaticamente ai clienti. Secondo uno studio condotto da Amazon, il 57% dei contenuti visibili online è costituito principalmente da materiale generato dall’intelligenza artificiale. I siti che fabbricano notizie false usano i generatori di testi per sfornare fiumi di disinformazione per conto di governi, movimenti politici e imprenditori che monetizzano le fake news. I social network sono pieni di influencer sintetici che guadagnano postando foto e video sintetici che ricevono commenti e lodi sintetiche da utenti altrettanto sintetici, in un corto circuito di contenuti totalmente artificiali.
Quanto c’è rimasto di reale e autentico in Internet?
Secondo una tesi di complotto nota come “Teoria dell’Internet Morta”, quasi tutto quello che vediamo online sarebbe contenuto generato automaticamente, manipolato da algoritmi nell’ambito di un piano mondiale per manipolare le menti di tutta l’umanità, e le cose starebbero così già dal 2016.
Questa è la storia di una teoria di complotto che è diventata realtà, almeno in parte, al netto dei suoi aspetti più deliranti. L’aumento dei contenuti generati dall’intelligenza artificiale è tangibile e quantificabile e ha conseguenze sociali forti e inaspettate. E all’orizzonte si staglia la minaccia del cosiddetto collasso dei modelli che sembra porre un limite definitivo al miglioramento delle attuali intelligenze artificiali.
Benvenuti alla puntata del 24 marzo 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Meta ha appena annunciato che il suo assistente basato sull’intelligenza artificiale, denominato Meta AI, sarà disponibile anche in Europa, Svizzera compresa, a distanza di due anni dal suo debutto negli Stati Uniti. Sarà comunque più limitato nelle prestazioni, per tenere conto della normativa europea che in sostanza vieta di usare i contenuti postati dagli utenti del continente per addestrare le intelligenze artificiali senza il consenso esplicito di quegli utenti [TechCrunch; Meta].
Meta AI sarà disponibile in tutte le principali app di Meta, quindi WhatsApp, Instagram, Messenger e Facebook, e in sei lingue: inglese, francese, spagnolo, portoghese, tedesco e italiano. Sarà fondamentalmente un chatbot integrato nelle app: la sua icona sarà un cerchio azzurro al quale si potranno porre domande senza dover uscire dall’app stessa.
Con l’arrivo di Meta AI, centinaia di milioni di utenti europei delle app di Meta si abitueranno ad avere nei loro gruppi Whatsapp, per esempio, dei membri sintetici da evocare per trovare un ristorante o avere informazioni su qualunque argomento, senza dover più passare da Google o da ChatGPT. A patto di fidarsi delle loro risposte, perché il problema delle cosiddette allucinazioni, ossia risposte che hanno un tono molto convincente ma sono inventate di sana pianta senza alcun nesso con la realtà, è serio e non sembra destinato a sparire presto.
Lo sa bene Google, la cui intelligenza artificiale integrata nei risultati di ricerca sta regalando momenti di ilarità involontaria. Sul social network Bluesky è stata pubblicata una compilation delle idiozie, in alcuni casi pericolose, fornite agli utenti dall’intelligenza artificiale di Google.
Alla domanda “quali attori hanno vinto degli Oscar per un film di Steven Spielberg”, Google ha risposto che lo hanno vinto Tom Hanks per Philadelphia e Holly Hunter per Lezioni di piano, dichiarando con risolutezza che i due film erano stati diretti da Spielberg quando in realtà la regia era rispettivamente di Jonathan Demme e Jane Campion.
Pazienza, direte voi, non muore nessuno se una IA sbaglia ad attribuire la regia di un film. Però lo scopo al quale dovrebbero servire le intelligenze artificiali è fornire informazioni, e fornire informazioni esatte, altrimenti sono solo uno spreco di tempo e di energia elettrica e causano solo confusione e disinformazione.
La questione si fa più seria se ci si fida della IA di Google per la propria salute, perché è capace di consigliare di rimediare al bruciore di stomaco mangiando carta igienica, la cui morbidezza “può lenire un esofago irritato”, dice testualmente. La stessa IA ha consigliato alle persone di mangiare “almeno un sassolino al giorno” e ha proposto di applicare il formaggio alla pizza usando della colla [Snopes].
Restando in campo culinario, se si chiede a Google se si può usare la benzina come combustibile per cuocere degli spaghetti, risponde di no, però aggiunge che si possono preparare degli spaghetti piccanti se si prepara una salsa facendo saltare in padella “aglio, cipolla e benzina” [Mastodon; BBC]. Se si interroga la IA di Google per sapere se la trippa è kosher o no, la risposta generata da miliardi di dollari di investimenti nell’intelligenza artificiale è risultata essere “dipende dalla religione della mucca”.
Se vi state chiedendo come possa emergere una risposta così demenziale, la spiegazione è che le cosiddette intelligenze artificiali non hanno cognizione della realtà e men che meno hanno il senso dell’umorismo, ma sono semplicemente dei costosi e complicatissimi sistemi di analisi statistica dei testi, per cui se un sito satirico o parodistico [per esempio questo] scrive un’assurdità come “la trippa è kosher a seconda della religione della mucca” e quella frase è quella che in tutta Internet statisticamente corrisponde meglio alla domanda che è stata posta, quelle intelligenze artificiali rigurgiteranno quella frase come risposta, presentandola come se fosse totalmente seria [BoingBoing; LanguageLog]. Questi errori vengono corretti manualmente [back-end fix] man mano che vengono scoperti, ma è impensabile poterli correggere tutti e comunque si tratta di pezze che non risolvono l’incapacità di base delle intelligenze artificiali attuali.
Anche le interazioni sui social network sono sempre più artificiali. Qualunque post pubblicato su X che parli di criptovalute, per esempio, attira immediatamente un’orda di bot, ossia di account automatici basati sull’intelligenza artificiale, che commentano con una frase a vanvera e linkano il sito del loro proprietario, e poi arrivano altri bot che rispondono ai commenti dei primi, in un fiume interminabile di banalità e spam scritto da macchine e letto da altre macchine, tanto che sta diventando difficile fare qualunque discussione significativa.
Instagram si sta riempiendo di “immagini generate dall’intelligenza artificiale che non hanno nessun valore oltre all’essere fugaci novità e si sta riempiendo di testi generati dalla IA che nessuno desidera leggere”, come ha scritto Dani Di Placido su Forbes, notando anche l’enorme numero di descrizioni di prodotti su Amazon e nei negozi online in generale che sono manifestamente generate da intelligenze artificiali non supervisionate. È l’unica spiegazione plausibile per il fatto che così tanti prodotti hanno descrizioni costituite dalle parole “Mi dispiace ma non posso soddisfare questa richiesta perché è contraria alle regole di utilizzo di OpenAI”.
Gli esseri umani sembrano essere diventati una minoranza dispersa nel mare di contenuti generati freneticamente dalle intelligenze artificiali. Questo mare è talmente vasto che secondo uno studio pubblicato nel 2024 da un gruppo di ricercatori di Amazon, il 57% dei testi di tutto il web è stato tradotto in tre o più lingue usando sistemi di traduzione automatica. Oggi, insomma, i principali generatori di testi al mondo non siamo più noi: sono le macchine.
Il risultato di questo spodestamento è che le intelligenze artificiali stanno cominciando a influenzare il modo in cui scriviamo anche noi. Alcuni linguisti hanno notato l’improvviso boom di popolarità di certe parole nelle pubblicazioni mediche in inglese quando è arrivato ChatGPT. Per esempio, l’uso della parola delve, ossia “approfondire”, si è più che decuplicato nel giro di quindici mesi dal debutto di ChatGPT, a novembre 2022.
La ragione, secondo questi esperti, è che questa parola è molto più usata della media mondiale nell’inglese parlato in Africa, dove lavora la manodopera a basso costo che fa il controllo della qualità delle risposte generate dalle intelligenze artificiali in fase di collaudo, e quindi ChatGPT ha incamerato questa maggiore frequenza nel proprio modello linguistico. Quando i medici di tutto il mondo hanno cominciato a usare ChatGPT come assistente per scrivere i loro articoli, hanno inconsapevolmente cominciato a usare delve più del normale [The Guardian; Getfreewrite.com; JeremyNguyen]. E così le macchine, silenziosamente, modificano sotto il nostro naso una cosa così fondamentalmente umana come la lingua che parliamo.
Tutti questi esempi sembrano avvalorare la cosiddetta Teoria dell’Internet Morta [Dead Internet Theory], ossia l’idea che la stragrande maggioranza del traffico di Internet, dei post e degli utenti stessi sia costituita da sistemi automatici e intelligenze artificiali e che gli esseri umani siano una presenza marginale nella Rete. Questa teoria è nata in alcuni forum di Internet una quindicina di anni fa ed è diventata famosa nel 2021 grazie a un articolo pubblicato sul popolare sito The Atlantic e firmato da Kaitlyn Tiffany che la descriveva in dettaglio.
La Teoria dell’Internet Morta è una tesi di complotto classica, che ipotizza una colossale cospirazione dei governi del mondo e in particolare di quello statunitense per nasconderci la verità e manipolare le opinioni mostrandoci solo contenuti generati da intelligenze artificiali e affini. La sua falla logica principale è che afferma che Internet sarebbe “morta”, per così dire, soffocata dalla IA, già nel 2016 o 2017, quando ChatGPT e le altre intelligenze artificiali necessarie per questa ipotetica generazione di immense quantità di contenuti sintetici non erano ancora state sviluppate.
È vero che alcuni aspetti di questa teoria somigliano molto a quello che si sta verificando adesso, con l’attuale proliferazione di testi e immagini generate, ma è una somiglianza soltanto superficiale, e soprattutto c’è un fatto tecnico che invalida completamente l’idea del grande complotto. Questo fatto si chiama collasso dei modelli.
Molte persone sono colpite dai progressi molto rapidi dell’intelligenza artificiale in questi ultimi anni e hanno l’impressione che questi progressi siano inarrestabili e che prima o poi, a furia di investire denaro e usare computer sempre più potenti, arriveremo a un’intelligenza artificiale superiore alla nostra, o che perlomeno smetterà di consigliare di usare la colla per applicare il formaggio alla pizza. Ma le cose non stanno così.
Infatti per arrivare ai livelli di prestazione delle attuali intelligenze artificiali in campo linguistico è stato necessario addestrarle dando loro praticamente ogni testo disponibile in forma digitale in tutto il mondo: tutti i siti, tutti i libri, tutti i giornali, tutte le riviste mai scritte, qualunque cosa mai pubblicata sui social network e altro ancora. Eppure non basta. Servono ancora altri testi.
Si potrebbero prendere i testi scritti e pubblicati online dopo la data di addestramento, ma c’è un problema: molti di quei nuovi testi sono stati scritti usando intelligenze artificiali. Ci si troverebbe, insomma, ad addestrare un’intelligenza artificiale dandole testi scritti da altre intelligenze artificiali, e nel 2024 un gruppo di ricercatori delle università di Cambridge e Oxford ha pubblicato su Nature uno studio secondo il quale un’intelligenza artificiale generativa che si addestri esclusivamente su contenuti prodotti da altre intelligenze artificiali dello stesso tipo si degrada molto rapidamente invece di migliorare. Bastano pochi cicli di questo cannibalismo informatico, meno di una decina, per ottenere una IA che produce sistematicamente risposte completamente prive di senso. Questo rapido deterioramento delle intelligenze artificiali basate su grandi modelli linguistici è stato battezzato appunto collasso dei modelli (model collapse) da questi ricercatori.
Il rapido degrado delle IA addestrate usando dati generati da IA. Fonte: Forbes/Nature.
Se l’idea di base della Teoria dell’Internet Morta è valida e quindi i dati prodotti da esseri umani vengono davvero diluiti sempre di più da fiumi di contenuti generati dalle IA, e se le conclusioni di questi ricercatori sono corrette, allora l’intelligenza artificiale come la conosciamo oggi rischia di raggiungere presto una soglia impossibile da superare. Forse è già stata raggiunta e non ce ne siamo ancora accorti, e i progressi spettacolari di questi ultimi anni non potranno proseguire.
Naturalmente è anche possibile che i ricercatori in futuro scoprano nuove tecniche di intelligenza artificiale che permettano di scavalcare o aggirare questa soglia, ma per il momento gli investimenti faraonici che si stanno facendo per l’intelligenza artificiale in tutto il mondo sono fondati sul modo di funzionare della IA attuale, non di quella futuribile. Se verranno scoperte queste nuove tecniche, allora quegli investimenti saranno stati riversati in una tecnologia che a quel punto sarà diventata obsoleta; se non verranno scoperte, la soglia resterà insormontabile e ulteriori progressi non saranno possibili.
In altre parole, oltre al collasso dei modelli di intelligenza artificiale bisogna pensare al possibile collasso di un altro modello: quello economico, quello che immagina che la crescita e i profitti possano proseguire all’infinito. E se collassa quello, per molte aziende e per tantissimi investitori il bruciore di stomaco sarà garantito. Speriamo che non seguano i consigli delle intelligenze artificiali e non cerchino di curarsi ingoiando carta igienica.
È andata in onda lunedì scorso alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
Questo è il testo della puntata del 17 marzo 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Dal 28 marzo prossimo gli assistenti vocali Alexa di Amazon smetteranno di rispettare le scelte di privacy dei loro utenti. Lo ha comunicato Amazon stessa pochi giorni fa, in una mail inviata ad alcuni di questi utenti, ma senza usare parole così chiare. Eppure è questo il senso tecnico della decisione unilaterale di Amazon di cambiare radicalmente il funzionamento dei suoi dispositivi dopo che gli utenti li hanno acquistati, e di cambiarlo a sfavore di quegli utenti.
Tra una decina di giorni, in sostanza, tutto quello che direte in presenza di un Alexa potrà essere registrato e inviato ad Amazon, dove potrà essere ascoltato, trascritto, registrato e dato in pasto all’intelligenza artificiale.* E questo vale anche per le versioni di Alexa che gli utenti hanno acquistato specificamente perché non facevano nulla di tutto questo.
* Per maggiore chiarezza: è così da tempo per la stragrande maggioranza dei dispositivi Alexa. Però finora c‘erano alcuni modelli di Alexa che non funzionavano in questo modo.
Questa è la storia di come Amazon è riuscita a convincere centinaia di milioni di persone in tutto il mondo a installarsi in casa un oggetto che è a tutti gli effetti un microfono aperto e connesso a Internet e ai suoi server, in ascolto ventiquattro ore su ventiquattro, ed è anche riuscita a convincere queste persone a pagare per avere quel microfono.
Benvenuti alla puntata del 17 marzo 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Siamo nel 2014, a novembre; quasi undici anni fa. Amazon presenta al pubblico Echo, uno strano altoparlante cilindrico, connesso a Internet, che include un assistente vocale simile a Siri di Apple.
Spaccato di un Amazon Echo di prima generazione (fonte: Techcrunch).
Come Siri, anche Echo risponde ai comandi vocali quando viene attivato tramite una parola specifica, che per questo prodotto di Amazon è “Alexa”: una parola scelta per il suo suono piuttosto insolito, caratterizzata dalle vocali dolci e dalla X che la fanno spiccare e la rendono più facilmente riconoscibile da parte della limitata potenza di calcolo presente a bordo di Echo. Se in casa c’è qualcuno che si chiama Alexa o Alessia e quindi c’è rischio di confusione, l’utente può scegliere in alternativa le parole Amazon,Echo, Ziggy o Computer [Business Insider; FAQ Amazon].
Al suo debutto, Echo di Amazon costa ben 199 dollari ed è disponibile solo su invito da parte dell’azienda [TechCrunch] e soltanto negli Stati Uniti. Arriva in Europa due anni più tardi, nel 2016, quando viene offerto anche in versione compatta a circa 60 euro [CNBC]. Tramite comandi vocali, permette di fare acquisti su Amazon, comandare vari dispositivi domestici interconnessi, impostare sveglie e timer e rispondere a varie domande attingendo alle informazioni di Wikipedia e di altre fonti.
Il principio di funzionamento di Echo è relativamente semplice. I suoi microfoni estremamente sensibili captano costantemente tutti i suoni e tutte le conversazioni che si svolgono nell‘ambiente nel quale Echo è collocato. I suoi processori analizzano altrettanto costantemente quello che è stato captato dai microfoni. Se secondo questa analisi è stata pronunciata la parola di attivazione (o wake word in gergo tecnico), allora i suoni raccolti vengono trasmessi via Internet ai computer di Amazon, dove vengono elaborati, trascritti e trasformati in comandi. Questi comandi vengono eseguiti, sempre sui computer di Amazon e anche su quelli delle aziende associate ad Amazon, e i loro risultati vengono inviati al dispositivo dell’utente.
L’intero procedimento è talmente veloce e invisibile che chi usa Alexa ha l’impressione che sia il dispositivo a fare tutto questo lavoro. Non ha nessuna percezione del fatto che le sue parole vengano registrate e trasmesse ad Amazon, che le conserva. Lo scopre soltanto se gli capita di accedere al suo account Amazon e di consultare una sezione dedicata appunto ad Echo e Alexa, che contiene la Cronologia voce, ossia tutto quello che è stato registrato dal suo dispositivo.
Screenshot della Cronologia voce (dal mio account Amazon).
[CLIP: spezzoni delle mie registrazioni di Alexa]
Questi sono alcuni campioni di quello che ha registrato il mio Alexa, nei rari momenti in cui l’ho tenuto acceso per fare qualche esperimento. Alcuni risalgono a più di cinque anni fa, ed è chiaro da quello che è stato registrato che Alexa registra e archivia non solo i comandi impartiti ma anche spezzoni di conversazioni nei quali viene citato il suo nome o qualcosa che gli assomiglia. Cosa ancora più interessante, registra e archivia anche alcuni secondi di quello che è stato detto prima di dire la parola di attivazione.
Un esempio di audio ambientale raccolto da Alexa e inviato ad Amazon nonostante non fosse un comando rivolto ad Alexa (dalla mia Cronologia voce).
[CLIP: una nostra amica che dice “è un po’ lenta Alexa” e Paolo che dice “OK Google parla con Alexa”. Notate che in entrambi i casi “Alexa” è l’ultima parola registrata e sono state registrate anche quelle dette appena prima]
Questo dimostra che Alexa è costantemente in ascolto e altrettanto costantemente in registrazione. Quando “crede” di aver sentito la parola di attivazione, prende l’audio che ha registrato e lo invia ad Amazon. E questo vuol dire che qualunque conversazione domestica è a rischio di essere registrata e inviata. Una confidenza, un momento di intimità con un partner, una telefonata al proprio medico per discutere la propria situazione di salute, una riunione confidenziale di lavoro, una discussione politica o religiosa. Tutto può finire negli archivi di Amazon.
È chiaro che questo modo di funzionare di Alexa è un grave rischio per la privacy, e non si tratta di ipotesi paranoiche: nel 2023 Amazon ha accettato di pagare un’ammenda di 25 milioni di dollari perché era stata colta a conservare per sempre le registrazioni delle interazioni dei bambini con Alexa, violando le leggi statunitensi sulla privacy [New York Times].
Amazon ha dichiarato che conserva tutte le registrazioni indefinitamente, se l’utente non provvede a cancellarle a mano [CNET; ZDNET] o a impostare la cancellazione automatica dopo tre o diciotto mesi. Ha aggiunto anche che un campione “estremamente piccolo” delle registrazioni acquisite viene ascoltato dai suoi dipendenti. Nel caso di Amazon, “estremamente piccolo” significava, nel 2019, che ciascuno dei suoi addetti specializzati a Boston, in Costa Rica, in India e in Romania ascoltava fino a mille spezzoni di audio domestico ogni giorno, e fra l’altro questi spezzoni venivano condivisi fra gli addetti non solo per ragioni tecniche ma anche semplicemente perché erano divertenti [Bloomberg (copia su Archive.is); Ars Technica].
Il fatto che le conversazioni degli utenti di Alexa possano essere ascoltate da queste persone non viene mai indicato nelle sue rassicuranti informazioni di marketing [copia su Archive.is; altre info qui] e neppure nelle sue informative sulla privacy. E così l’impressione che ha l’utente medio è che quello che dice ad Alexa nell’intimità della propria casa sia ascoltato soltanto da freddi e indifferenti sistemi automatici, ma non è affatto così.
A volte va anche peggio: queste registrazioni possono finire in mano a sconosciuti. Nel 2018 un utente Alexa in Germania ha provato a esaminare la propria cronologia delle conversazioni e vi ha trovato circa 1700 registrazioni di qualcun altro: un uomo che in casa propria parlava con la compagna. Quando ha segnalato la serissima violazione della privacy, inizialmente Amazon non gli ha neppure risposto e ha avvisato la vittima solo quando la notizia è uscita sulla stampa specializzata. L’azienda ha dichiarato che si è trattato di “un errore umano e un caso singolo isolato” [Washington Post; Reuters].*
Insomma, il problema di fondo è che i microfoni di questi dispositivi di Amazon, come del resto quelli equivalenti di Google e di Apple, prendono i suoni ascoltati in casa e li consegnano alle rispettive aziende per l’analisi e l’elaborazione. Se questa analisi ed elaborazione avvenissero localmente, a bordo del dispositivo, in modo da non trasmettere esternamente i suoni ambientali, il funzionamento di questi oggetti sarebbe molto più rispettoso della naturale riservatezza che ci si aspetta di avere in casa propria.
Infatti nel 2020 Amazon ha presentato i dispositivi Echo Dot di quarta generazione, che insieme agli Echo Show versione 10 e 15, dotati di schermo e telecamera, erano in grado di elaborare localmente i suoni che captavano. Una rivoluzione nel modo di funzionare di questi dispositivi che li rendeva decisamente appetibili per chiunque avesse riflettuto seriamente sulla questione. Finalmente un prodotto fatto come si deve in termini di privacy.*
* Questa funzione era disponibile esclusivamente agli utenti statunitensi con Alexa impostato sulla lingua inglese [The Technology Express]
Ma chi ha comprato questi dispositivi ora si trova con una sorpresa molto amara: il 28 marzo prossimo Amazon disabiliterà l’elaborazione locale dell’audio su tutti questi apparati, che cominceranno a funzionare esattamente come tutti gli altri di Amazon, mandando quindi ai server dell’azienda (e alle orecchie dei suoi dipendenti addetti al servizio Alexa) tutto quello che viene ascoltato dai loro sensibilissimi microfoni e interpretato come comando da mandare.
L’utente che ha pagato per avere questi prodotti si troverà quindi con un dispositivo degradato che non farà più la cosa fondamentale per la quale era stato acquistato, ossia rispettare la riservatezza dell’utente. E non ci sarà nulla che potrà fare per opporsi.*
* Negli Stati Uniti la legge DMCA (1998) rende punibile con cinque anni di carcere e una sanzione da 500.000 dollari l’alterazione del software (e in questo caso del firmware) di un dispositivo protetto dal copyright, anche se viene fatta dal proprietario del dispositivo stesso.
Quello di Amazon è un comportamento che viene spesso chiamato cinicamente “l’MBA di Darth Vader”, con riferimento al celeberrimo personaggio malvagio di Star Wars, il cui potere è così assoluto che se tenesse un corso di formazione per l’amministrazione aziendale insegnerebbe ai suoi studenti che il rispetto dei contratti e delle regole concordate è roba per gli inferiori, alle cui fastidiose obiezioni si risponde sempre in questo modo:
[CLIP: Darth Vader che dice “Ho cambiato il nostro accordo. Prega che non lo cambi ancora” (da L’Impero Colpisce Ancora, 1:34:10)]
Amazon giustifica questa menomazione intenzionale dei dispositivi comprati dai suoi clienti con la scusa onnipresente del mondo informatico: l’intelligenza artificiale. Sta infatti per arrivare Alexa+, che è in grado di offrire servizi più complessi e sofisticati grazie appunto all’intelligenza artificiale [Ars Technica]. Intelligenza che però sta nei computer di Amazon, non fisicamente dentro i dispositivi degli utenti, per cui non c’è scelta: l’audio captato deve essere per forza trasmesso ad Amazon ed elaborato sui computer dell’azienda. Alexa+, fra l’altro, avrà probabilmente un canone mensile, a differenza dell’Alexa attuale.*
* La maggior parte delle fonti prevede che questo canone sarà di 20 dollari al mese per gli utenti generici ma gratuito per gli utenti iscritti ad Amazon Prime [Aboutamazon.com].
Questa transizione all’intelligenza artificiale remota significa che gli attuali dispositivi Echo Show perderanno una delle loro funzioni più potenti: la capacità di identificare le voci delle varie persone che li usano e di offrire agende, musica e promemoria personalizzati ai vari membri di una famiglia elaborando l’audio localmente per riconoscere le varie voci, grazie a una funzione chiamata Voice ID. Amazon ha avvisato i proprietari di questi dispositivi che questa funzione non ci sarà più. Adesso la stessa cosa verrà fatta con l’intelligenza artificiale, ma mandando l’audio di casa ad Amazon.
Certo, l’azienda sottolinea nel suo avviso che l’audio è cifrato in transito e che gli utenti potranno chiedere che venga cancellato dopo l’uso, e aggiunge che ci sono “strati di protezioni di sicurezza per tenere al sicuro le informazioni dei clienti”. Ma visti i precedenti di Amazon, e visto che in generale l’intelligenza artificiale ha la discutibile abitudine di rigurgitare in modo inatteso i dati personali che ha ingerito, una certa diffidenza è comprensibile e inevitabile.*
* Anche perché fino al 2022 Amazon era lanciatissima verso l‘elaborazione on-device, che era presentata come una tecnologia con “tanti benefici: riduzione della latenza, ossia del tempo che Alexa impiega a rispondere alle richieste; riduzione del consumo di banda, importante sui dispositivi portatili; e maggiore disponibilità per le unità a bordo di auto e per altre applicazioni nelle quali la connettività verso Internet è intermittente. L’elaborazione on-device consente anche di fondere il segnale vocale con altre modalità, come la visione, per funzioni come il parlare a turno naturale di Alexa” [Amazon Science, gennaio 2022]. Se questi non sono più “benefici” e Amazon vuole accollarsi l’onere computazionale di elaborare in-cloud tutte le richieste, ci sarà probabilmente un tornaconto sotto forma di utilizzo dei dati vocali per addestramento di IA o ulteriore analisi.
Per chi preferisce non avere in casa, in ufficio o nello studio medico microfoni aperti e connessi a Internet, le soluzioni alternative ad Amazon non mancano. Una delle più interessanti è Home Assistant, un ecosistema di dispositivi e di software che fa quasi tutto quello che fa Alexa di base, compreso il collegamento con i sistemi domotici di ogni marca che rispetti gli standard tecnici, lo fa senza canone mensile ed è configurabile in modo che elabori tutto l’audio localmente, senza mandare nulla via Internet a nessuno, tenendo privacy e sostenibilità come valori centrali.*
Inoltre Home Assistant è basato sul principio dell’open source, per cui tutti i componenti e tutto il software sono liberamente esaminabili e modificabili e tutti gli standard utilizzati sono liberi e documentati. Non c’è nessun Darth Vader o Jeff Bezos che possa cambiare gli accordi e far pregare che non li cambi ancora, ma c’è una fondazione, la Open Home Foundation, che coordina lo sviluppo di Home Assistant e ha fra l’altro sede in Svizzera[altre info], c’è una base legale solida e collaudata che tutela il tutto e c’è una vasta comunità di utenti che sviluppa il prodotto e insegna a usarlo, per esempio pubblicando dettagliati tutorial su YouTube.
Insomma, se vi è sempre sembrato assurdo che con la domotica per accendere le luci in soggiorno il comando dovesse fare il giro del mondo e dipendere da una rete di computer gestita da chissà chi, le soluzioni ci sono. Si tratta solo di scegliere fra ricevere la pappa pronta da chi può ritirare il suo costoso cucchiaio in ogni momento e rimboccarsi le maniche per studiare come cucinarsi le cose da soli. Di solito si fatica di più, ma si risparmia, e le cose fatte in questo modo hanno più gusto.
Il 26 marzo Paolo sarà a Vicosoprano, Val Bregaglia (Grigioni italiano), per una conferenza sull’Intelligenza Artificiale, alle ore 19,30 presso la palestra.
Come si fa a dare una colorazione alternata (il cosiddetto zebra striping) alle righe dell’elenco dei messaggi in Thunderbird, in modo che siano più leggibili? Ne avevo scritto un paio d’anni fa, sul blog “classico”, e posso confermare che il metodo descritto allora funziona ancora oggi con la versione più recente di Thunderbird, che è la 136.0.
Lo riassumo brevemente qui:
Andare nel Config Editor di Thunderbird (tre trattini in alto a destra, Settings/Impostazioni, scorrere giù, cliccare sul pulsante Config Editor/Editor di configurazione) e digitare le lettere iniziali di toolkit.legacyUserProfileCustomizations.stylesheets fino a che viene elencata solo la voce omonima.
Questa voce è probabilmente settata su False. Cliccare sull’icona con le due mezze frecce contrapposte in modo che questa voce diventi True.
Identificare la cartella del profilo generale di Thunderbird: la si trova cliccando in Thunderbird sui tre trattini in alto a destra – Help/Aiuto – Troubleshooting information/Informazioni per la risoluzione dei problemi, trovando Profile Folder/Cartella del profilo e cliccando su Show in Finder/Mostra nel Finder, perlomeno su macOS.
In questa cartella, creare una sottocartella di nome chrome (se non esiste già).
in questa sottocartella, creare un file di testo semplice di nome userChrome.css (con la C maiuscola) e metterlo nella cartella chrome suddetta.
Nel file userChrome.css, immettere queste righe di testo (la prima riga è un commento di documentazione ed è opzionale): /* riabilita lo zebra striping */ #threadTree tr:nth-child(2n) { background-image: linear-gradient(rgba(0,0,0,.08), rgba(0,0,0,.08)) !important; }
Salvare il file.
Chiudere e riavviare Thunderbird: le modifiche immesse in userChrome.css vengono attivate e valgono per tutti gli account di mail.
Questa sera al Centro Congressi del Monte Verità di Ascona (Svizzera), via Collina, in occasione dell’evento Asconoscienza 2025 (Asconoscienza.ch), Paolo parlerà di Spazio con la conferenza Astronautichicche: gli aspetti poco conosciuti dell’esplorazione spaziale.
L’appuntamento è alle 20.30.
Ci saranno alcune copie di Carrying the fire in vendita.
È andata in onda lunedì 10 marzo scorso alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
Questo è il testo della puntata del 10 marzo 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Un gatto vaga in un mondo nel quale gli esseri umani sembrano svaniti nel nulla ma i cani, eterni persecutori di felini, ci sono ancora, e al micio tocca trovare nuovi rifugi, insoliti compagni di viaggio e nuove strategie per cercare di sopravvivere. È l’inizio di Flow – Un mondo da salvare, l’opera che ha vinto l’Oscar come migliore film d’animazione di quest’anno dopo aver conquistato anche il Golden Globe.
Il film ha molti meriti e molte caratteristiche insolite: un regista lettone, la totale assenza di dialoghi perché la storia è raccontata dalle immagini, e il fatto di aver battuto la concorrenza di colossi dal portafogli ben fornito come Disney, Pixar e Netflix.
Ma Flow ha anche una particolarità molto informatica: è stato realizzato usando il software Blender, che è libero e gratuito eppure riesce a generare animazioni ed effetti paragonabili a quelli dei costosi software commerciali che si usano normalmente per produrre i film di animazione digitale.
Questa è la storia di Blender, di come è possibile che un software che non costa nulla competa e vinca contro applicazioni sostenute e sviluppate dalle più importanti aziende del settore e sia giunto al traguardo dell’Oscar grazie al talento di un gruppo di persone creative, ed è anche la storia di cosa significa tutto questo per chiunque sogni di trasformare le proprie idee in immagini sullo schermo ma si trova paralizzato o intrappolato da costi di licenza insostenibili. Ed è anche la storia di un inaspettato legame di questo nome,Blender,con la Svizzera.
Benvenuti alla puntata del 10 marzo 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
È il 1994. Uno studio di animazione olandese, NeoGeo, che oggi non esiste più, sviluppa un software di grafica e animazione digitale per uso interno. I suoi creatori lo chiamano Blender, frullatore, come tributo all’omonimo brano della band svizzera Yello che l’azienda usa nel suo video dimostrativo.
Il brano degli Yello che ha dato il nome al software Blender (YouTube).
Il software viene poi rilasciato pubblicamente come freeware, ossia come software gratuito liberamente scaricabile e utilizzabile senza pagare nulla, e successivamente come shareware, vale a dire come software che si può scaricare gratis in prova limitata e poi si paga per averne una versione completa.
Blender però non fa grandi progressi, e langue fino al 2002, quando Tom Roosendaal, principale autore del software, crea nei Paesi Bassi la fondazione senza scopo di lucro chiamataBlender Foundation e avvia con successo una campagna di raccolta fondi per rendere Blender libero e open source: in altre parole, gratuito, liberamente ispezionabile e modificabile da chiunque, a patto che le modifiche siano a loro volta distribuite gratuitamente e altrettanto ispezionabili.
Nasce così una comunità internazionale di sviluppatori appassionati che lo fanno crescere, sotto il coordinamento dei membri della Blender Foundation, e lo fanno diventare quello che è oggi: uno strumento potentissimo di grafica digitale accessibile a chiunque a costo zero, che include modellazione, animazione, rendering,compositing ed è disponibile in versioni per Windows, MacOS e Linux presso Blender.org.
Ogni uno o due anni, inoltre, la Blender Foundation gestisce la produzione di un cortometraggio di animazione che serve per stimolare l’innovazione e dimostrare pubblicamente le potenzialità di Blender. Questi brevi video (come per esempio Big Buck Bunny, Sintel, Tears of Steel) hanno un discreto successo di critica e di pubblico e vengono indicati come esempi di modi alternativi, collettivi e aperti, di creare arte e cinema d’animazione: chiunque sia competente può partecipare alla loro realizzazione e tutte le risorse e i modelli creati vengono messi a disposizione di chiunque per essere riutilizzati. L’esatto contrario del cinema tradizionale, dove tutti i diritti sono riservatissimi e usare un costume o un oggetto di scena senza permessi e contratti appositi è assolutamente vietato.
Dai primi anni Duemila Blender non è più uno strumento per appassionati e autori indipendenti ma comincia a essere usato nella preproduzione e negli effetti visivi di film e telefilm commerciali, anche con budget molto consistenti [Spider-Man 2; Captain America: The Winter Soldier; The Man in the High Castle], e viene usato anche dalla NASA per le animazioni che illustrano le sue missioni spaziali. Ma tutto questo è poco visibile al grande pubblico ed è quasi trascurabile rispetto all’impatto mediatico di vincere, come adesso, un premio Oscar con Flow.
Ovviamente Flow non è stato creato da Blender; questo software è solo uno strumento a supporto della creatività umana, e in questo caso il creativo si chiama Gints Zilbalodis ed è un regista e animatore lettone, che ha già realizzato da solo vari cortometraggi digitali e un intero lungometraggio, intitolatoAway[trailer], usando il software commerciale Maya di Autodesk, ma nel 2019 decide di abbandonare questo prodotto per passare appunto a Blender, perché questo software libero e gratuito ha delle caratteristiche superiori, che gli servono per i suoi progetti successivi.
È in quell’anno che Zilbalodis inizia lo sviluppo di quello che diventerà poi Flow. Numerose scene prevedono ambientazioni acquatiche, per cui serve un software capace di generare simulazioni realistiche di fluidi e di vari fenomeni fisici, di fare modellazione, di fare il cosiddetto rigging (cioè la creazione delle articolazioni virtuali dei personaggi), l’animazione vera e propria, l’unione di tutti gli elementi della scena e anche il rendering in tempo reale, vale a dire la visualizzazione immediata del risultato finale, senza dover attendere tempi di elaborazione (per fare un paragone, ai tempi del primo Toy Story, nel 1995, alcuni fotogrammi richiedevano trenta ore di calcoli ciascuno, e ne servono 24 per ogni secondo di un film). Blender consente di fare tutto questo all’interno di un singolo programma, e questo rende più efficiente, rapido e coerente il flusso di lavoro.
Anche così, per concepire gli 80 minuti di animazione di Flow servono in tutto cinque anni e mezzo, perché i calcoli oggi si fanno velocemente, ma la creatività e la ricerca di fondi per finanziare un progetto di film d’animazione richiedono tempo come e forse anche più di prima. La produzione vera e propria delle 22 sequenze che compongono Flow richiede in totale sei mesi alla squadra di venti animatori sparsi fra Parigi, Marsiglia e Bruxelles. Il resto del tempo viene speso in preparativi, organizzazione, scrittura, sviluppo dei personaggi e della trama, e ovviamente promozione e trattative per trovare sostegno economico e canali di distribuzione.
Vincere un Oscar come miglior film d’animazione è un grande riconoscimento al talento creativo del regista Gints Zilbalodis, ma è anche un segnale importantissimo per l’intera comunità dei progetti informatici basati sui principi dell’open source di libertà, collaborazione aperta e trasparenza. Comunica in modo forte che questo modo di creare software è capace di competere alla pari con la maniera commerciale di sviluppare applicazioni.
Soprattutto, l’Oscar conquistato conferma che “la creatività, il talento e la visione contano più dell’investimento economico riversato in costosi strumenti a codice sorgente chiuso”, come scrive It’s Foss News, aggiungendo che “il successo di Flow ispirerà molti creatori che non hanno accesso a carissimi software di creazione 3D per sviluppare le proprie idee.”
La questione dell’accesso a questi software è fondamentale per chiunque voglia incamminarsi lungo un percorso per diventare autore di animazioni, per i giovani talenti che vorrebbero emergere. Un costo di licenza che è sostenibile per un’azienda avviata non lo è per una persona che vuole imparare e farsi le ossa con l’animazione digitale. Duemila euro l’anno, come nel caso del software Maya, sono una cifra importante per chi studia o fa animazione per passione. Possono rendere impossibile un sogno o un desiderio di carriera.
E c’è il problema aggiuntivo che se si crea qualcosa con un software che ha un costo di licenza ricorrente, quella creazione diventa dipendente da quel software e quindi per lavorarci, per aggiornarla o modificarla in qualunque modo, bisogna continuare a pagare, pagare, pagare, come sa bene chiunque abbia creato progetti con i popolarissimi software di Adobe Creative Cloud, come Photoshop o Premiere, giusto per fare un esempio molto conosciuto.
I prezzi attuali di licenza per usare le app di Creative Cloud (Adobe.com).
I prezzi attuali di licenza d’uso di Autodesk Maya (Autodesk.com).
Per non parlare della dipendenza che nasce dal tempo investito per imparare a usare quel software, o della dipendenza da aziende che risiedono in paesi soggetti a ghiribizzi politici surreali come quelli attuali che stanno sconvolgendo anche l’informatica e il mondo del cinema, con censure e autocensure che rievocano e fanno riscoprire il maccartismo di settant‘anni fa.
Il potenziale dirompente del software libero e gratuito è stato sottolineato proprio da Gints Zilbalodis in un’intervista subito dopo aver ricevuto l’Oscar: “Blender è un software libero, gratuito e a codice sorgente aperto” dice il regista “e questo vuol dire che è accessibile a tutti, e quindi oggi qualunque persona giovane ha a disposizione strumenti che vengono usati per realizzare film che ora hanno anche vinto un Oscar. Quindi credo che vedremo creare film emozionanti di ogni genere da parte di giovani che altrimenti non avrebbero mai avuto l’occasione di farlo. Blender è un grande strumento, non è in alcun modo un compromesso: ha la stessa qualità di tutti gli altri prodotti in circolazione, e lo useremo anche per il mio prossimo film.”
Salve, Samsung. So che magari non sono il vostro cliente quadratico medio, ma vorrei dirvi pubblicamente che se ho voglia di informarmi, sono perfettamente capace di farlo da solo, grazie; non mi piace essere trattato come un deficiente la cui vita è così vuota da dover essere allietata da una petulante “intelligenza” artificiale, e l’ultima cosa che voglio mentre sto lavorando, dormendo o facendo qualunque altra cosa della mia giornata è essere interrotto da una notifica che ha un bisogno incontenibile di farmi sapere “notizie” di cui non me ne frega assolutamente nulla.
Ho approfittato di un’offerta del mio operatore cellulare (Salt.ch) per acquistare un Samsung Galaxy S25 che userò principalmente come telefono di backup, come autenticatore di riserva e come “saponetta” 5G per avere una connessione a Internet di riserva.
Questo telefono, come tanti altri ultimamente, è infarcito di applicazioni basate sull’intelligenza artificiale che sono fondamentalmente inutili e irritanti. Una di queste è la “Now Brief”, il cui scopo sembra essere quello di informarmi sulle condizioni meteo locali e altre cose del genere di cui assolutamente non sento il bisogno. È attiva per default.
Per disattivarla, si va in Impostazioni – Schermata di blocco e AOD – Now bar – Now brief e si disattiva. Lo segnalo qui così magari altri che hanno la mia stessa esigenza trovano le istruzioni per soddisfarla.
Cinque anni fa, in piena pandemia, la Dama del Maniero e io abbiamo deciso di abbandonare definitivamente le auto a carburante e abbiamo acquistato una Tesla Model S di seconda mano, spendendo circa 35.000 euro. Cinque anni fa Elon Musk sembrava davvero un genio innovatore, eccentrico ma animato da intenti positivi. Oggi risulta essere un pazzo pericoloso con deliri di onnipotenza.
L’auto è in leasing, che scade tra pochi mesi: a quel punto decideremo cosa farne. Di certo continueremo a usare auto elettriche perché costano pochissimo (la sto caricando gratis in questo momento con l‘eccedenza di produzione dei pannelli solari sul tetto del Maniero, e la manutenzione in questi cinque anni è stata trascurabile), hanno di fatto un impatto ambientale molto minore di quello delle auto tradizionali e ci danno un grandissimo piacere di viaggio e di guida. Ma non credo che prenderemo un’altra Tesla: non ci piacciono le attuali scelte tecniche e soprattutto il marchio oggi è legato troppo strettamente a una persona totalmente tossica e socialmente disastrosa.
Abbiamo deciso di mettere in chiaro la nostra opinione mettendo due adesivi sulla nostra Tesla.
Sì, lo so che si legge la targa. Non è un segreto e ho scelto di pubblicarla perché il numero è un omaggio a Star Trek.
Dopo il successo dell’edizione 2025 della convention di fantascienza, astronomia e astrofisica Sci-Fi Universe che ho il piacere di co-organizzare e co-presentare insieme all’allegra squadra dello Stargate Fanclub Italia, è già partita la preparazione dell’edizione 2026. Abbiamo già fissato le date per quella che speriamo sarà la vostra prima convention di ogni nuovo anno: l’appuntamento è per il weekend del 17 e 18 gennaio 2026.
Potremo trascorrere insieme un intero fine settimana (e qualcuno fra noi minaccia “forse anche di più”, visti gli entusiasmi di tanti partecipanti arrivati la sera prima quest’anno), alternando momenti interessanti ed istruttivi ad altri allegri e divertenti, tutti accomunati dalla fantastica atmosfera di amicizia e convivialità che contraddistingue la Sci-Fi Universe fin dalla sua prima edizione.
Il luogo scelto per le edizioni passate sembra proprio piacere tanto a tutti, per cui restiamo anche per il 2026 al Parc Hotel di Peschiera del Garda (VR), dove non solo avremo capienti sale a nostra disposizione ma si potrà comodamente pernottare e mangiare in loco, e godersi momenti di pausa negli ampi spazi dell’hotel, dal bar alla fantastica piscina/spa.
Ci siamo accorti, infatti, che oltre agli eventi letterari, scientifici e fantascientifici, ai workshop, alle conferenze, agli ospiti e alle sessioni di gioco, per molti partecipanti la SFU è soprattutto un’occasione per ritrovare tanti amici tutti insieme e passare un weekend in allegra compagnia nelle ampie aree di ritrovo del Parc Hotel. E questo ci fa felicissimi! Volevamo proprio creare un momento di ritrovo fra appassionati che fosse fruibile comodamente da tutti, senza pellegrinaggi continui per i pasti, accessibile e divertente anche per chi magari vuole portare la famiglia, e da come avete risposto fin qui ci sembra che ci stiamo muovendo nella direzione giusta.
Se volete saperne di più, e magari cominciare a prenotare le camere (quelle più vicine si esauriscono in fretta), trovate tutti i dettagli sul sito della Sci-Fi Universe: Scifiuniverse.it (per gli amici, la Sciallacon).
A settembre scorso ho provato ad attivare l’opzione Meta Verified sul mio account Instagram, spendendo circa 13 euro al mese per avere alcuni “vantaggi” tipo il bollino di autenticazione, una maggior protezione contro il furto di identità e un supporto tecnico prioritario, ma dopo le recenti svolte politiche non me la sento proprio più di dare soldi a questi fantastiliardari arroganti, arraffoni e insensibili.
Inoltre ho provato Instagram pensandolo come sostituto di Twitter, ma il suo ostinato rifiuto a permettere link verso il resto di Internet lo rende inutile per le mie necessità. Meglio allora Threads o Bluesky, e meglio di tutti Mastodon. Per cui vedrete che sparirà dal mio account Instagram il bollino blu (anzi, è già sparito, perché ho chiesto la rimozione immediata). È intenzionale e mi va benissimo così.
Al momento la mia situazione social è questa:
Instagram: 6133 follower
Threads: 4896 follower
X/Twitter: 403.882 follower (ma non pubblico nulla)
Mastodon: circa 13.000 follower
Bluesky: 368 follower (l’ho aperto il 2 febbraio scorso)
Facebook: ho solo un segnaposto contro gli intrusi
Sto chiudendo la contabilità del 2024 e mi serve una copia delle fatture mensili che OpenAI ha emesso per il periodo in cui ho avuto un account a pagamento (ora sono passato alla versione gratuita perché l’uso che facevo di ChatGPT era troppo limitato per giustificare la ventina di dollari mensili della versione a pagamento).
Secondo buon senso, dovrebbe bastarmi fare login nel mio account OpenAI, andare alla cronologia delle fatture, elencarle e stamparle (la Dama del Maniero, che gestisce la nostra contabilità, ne vuole una copia cartacea per riordinarla e controllarla più efficacemente).
Ci trovo il deserto.
Mi coglie l’infelice idea di mettere alla prova ChatGPT e chiedergli aiuto.
Seguo le sue istruzioni, correggendole perché sono sbagliate: l’icona del profilo è nell’angolo in alto e a destra, non in basso a sinistra. Pazienza, dai.
Ma nelle mie impostazioni (https://chatgpt.com/#settings) non c’è la voce di fatturazione (probabilmente perché ho convertito l’account a pagamento in uno gratuito).
Faccio notare questa cosa a ChatGPT, che mi risponde come segue:
Vado al link che mi consiglia al primo punto: anche qui, il deserto.
Il secondo punto fa notare che se ora ho un account gratuito la sezione Billing (fatturazione) non ci sarà. Grazie, adesso te ne accorgi e me lo dici?
Provo a spiegargli meglio la situazione, e ChatGPT mi propone altre soluzioni:
Ma anche stavolta i suggerimenti di chatGPT sono inutili e fuorvianti, e persino l’invito a contattare il supporto tecnico è sbagliato, perché non c’è nessuna opzione di invio messaggi nell’Help Center di OpenAI. Glielo faccio notare.
Alla fine seguo invece le istruzioni presenti nelle FAQ di OpenAI (cosa che avrei dovuto fare sin da subito) e mando una mail all’indirizzo del supporto clienti (ar chiocciola openai.com).
Nel giro di sette minuti mi arriva la risposta, che dallo stile sembra anch’essa generata dall’intelligenza artificiale ma se non altro fornisce le info che mi servivano.
In realtà mi arriva anche una seconda mail, che però contiene tutti i link scombinati (quello che dovrebbe portare alla fattura di gennaio 2024 in realtà porta alla fattura di gennaio 2025, e così via), ma pazienza.
Se ChatGPT non sa rispondere correttamente neppure a domande che riguardano OpenAI, con che faccia tosta ci viene proposto di usarlo come assistente per le questioni delicate di lavoro?
Morale della storia: se incontrate un IA che fa da “helpdesk” per un sito, probabilmente perdete meno tempo a usare la vostra intelligenza per cercare direttamente quello che vi serve nelle pagine di assistenza del sito. E se siete un’azienda che sta pensando di mettere una IA al posto dell’assistenza clienti, pensateci bene: rischiate di spendere soldi per installare sul vostro sito un maggiordomo inetto e irritante che fa solo spazientire i vostri clienti.
Ci sono delle ottime applicazioni dell’intelligenza artificiale che funzionano benissimo. Questa non è una di quelle.
Blue Origin, la società aerospaziale di Jeff Bezos, ha annunciato il 27 febbraio scorso l’equipaggio di uno dei prossimi voli suborbitali del vettore New Shepard, ed è un annuncio particolarmente interessante per due motivi. Uno è la presenza della superstar canora e ambasciatrice UNICEF Katy Perry; l’altro è che per la prima volta in 60 anni un volo spaziale ha un equipaggio composto interamente da donne. Non succedeva dai tempi del volo orbitale di Valentina Tereshkova nel 1963.
Il lancio, etichettato NS-31, è previsto per questa primavera, e supererà per alcuni minuti i 100 km di quota (la linea di Kármán), qualificandosi come volo spaziale pur senza entrare in orbita. Oltre a Katy Perry, l’equipaggio include la giornalista e pilota di elicotteri Lauren Sánchez (vincitrice di un Emmy, compagna di Jeff Bezos e organizzatrice del volo); l’imprenditrice ed ex scienziata della NASA Aisha Bowe; la ricercatrice di bioastronautica, candidata al Nobel per la pace e Donna dell’Anno di Time Amanda Nguyen (che diventerà la prima donna astronauta vietnamita); la giornalista e conduttrice radiofonica Gayle King; e l’imprenditrice sociale Kerianne Flynn.
Qui sotto trovate il testo integrale dell’annuncio da parte di Blue Origin.
Blue Origin Announces Crew For New Shepard’s 31st Mission
New Shepard’s 11th Human Flight, NS-31, Will Launch This Spring with Aisha Bowe, Amanda Nguyen, Gayle King, Katy Perry, Kerianne Flynn, and Lauren Sánchez
Blue Origin today announced the six people flying on its NS-31 mission. The crew includes Aisha Bowe, Amanda Nguyen, Gayle King, Katy Perry, Kerianne Flynn, and Lauren Sánchez, who brought the mission together. She is honored to lead a team of explorers on a mission that will challenge their perspectives of Earth, empower them to share their own stories, and create lasting impact that will inspire generations to come.
Meet the NS-31 Crew
Aisha Bowe Aisha is a former NASA rocket scientist, entrepreneur, and global STEM advocate. She is the CEO of STEMBoard, an engineering firm recognized twice on the Inc. 5000 list of America’s fastest-growing private companies, and the founder of LINGO, an edtech company on a mission to equip one million students with essential tech skills. Of Bahamian heritage, Aisha hopes her journey from community college to space will inspire young people in the Bahamas and around the world to pursue their dreams.
Amanda Nguyen Amanda is a bioastronautics research scientist. She graduated from Harvard, and conducted research at Harvard Center for Astrophysics, MIT, NASA, and International Institute for Astronautical Sciences. Amanda worked on the last NASA shuttle mission, STS-135, and the Kepler exoplanet mission. For her advocacy for sexual violence survivors, she was nominated for the Nobel Peace Prize and awarded TIME’s Woman of the Year. As the first Vietnamese and Southeast Asian woman astronaut, Amanda’s flight is a symbol of reconciliation between the United States and Vietnam, and will highlight science as a tool for peace.
Gayle King Gayle is an award-winning journalist, co-host of CBS Mornings, editor-at-large of Oprah Daily, and the host of Gayle King in the House on SiriusXM radio. In a career spanning decades, King has been recognized as a gifted, compassionate interviewer able to break through the noise and create meaningful conversations. As someone who is staying open to new adventures, even ones that scare her, Gayle is honored to be part of Blue Origin’s first all-female flight team and is looking forward to stepping out of her comfort zone.
Katy Perry Katy is the biggest-selling female artist in Capitol Records’ history and one of the best-selling music artists of all time with over 115 billion streams. Aside from being a global pop superstar, Katy is an active advocate of many philanthropic causes, including as a UNICEF Goodwill Ambassador where she uses her powerful voice to ensure every child’s right to health, education, equality, and protection, and her own Firework Foundation, which empowers children from underserved communities by igniting their inner light through the arts. Katy is honored to be a part of Blue Origin’s first all-female crew and hopes her journey encourages her daughter and others to reach for the stars, literally and figuratively.
Kerianne Flynn After a successful career in fashion and human resources, Kerianne Flynn has spent the last decade channeling her energy into community-building through board service and nonprofit work with The Allen-Stevenson School, The High Line, and Hudson River Park. Passionate about the transformative power of storytelling, Kerianne has produced thought-provoking films such as This Changes Everything (2018), which explores the history of women in Hollywood, and LILLY (2024), a powerful tribute to fair-pay advocate Lilly Ledbetter. Kerianne has always been drawn to exploration, adventure, and space, and hopes her Blue Origin space flight serves as an inspiration for her son, Dex, and the next generation of dreamers to reach for the stars.
Lauren Sánchez Lauren is an Emmy Award-winning journalist, New York Times bestselling author, pilot, Vice Chair of the Bezos Earth Fund, and mother of three. In 2016, Sánchez, a licensed helicopter pilot, founded Black Ops Aviation, the first female-owned and operated aerial film and production company. Sánchez released her New York Times bestselling debut children’s book, The Fly Who Flew to Space, in 2024. Her work in aviation earned her the Elling Halvorson Vertical Flight Hall of Fame Award in 2024 for her expertise as a helicopter pilot and aviation businesswoman. Sánchez’s goal is to inspire the next generation of explorers.
This mission will be the 11th human flight for the New Shepard program and the 31st in its history. To date, the program has flown 52 people above the Kármán line, the internationally recognized boundary of space. This is the first all-female flight crew since Valentina Tereshkova’s solo spaceflight in 1963.
Qualcosa di positivo per interrompere il vostro e il mio doomscrolling.
La nuova companion del Dottore per questa stagione è Belinda Chandra (interpretata da Varada Sethu); se vi pare un volto familiare, era Mundy Flynn nella puntata Boom della stagione scorsa (quella geniale della chiesa anglicana militarizzata, attualissima in questi tempi di venti di guerra). Ma c’è anche uno spezzone con la companion precedente, Ruby Sunday (Millie Gibson), e ci sono tanta azione, tanta fantasia e tanti piccoli momenti di spavento (ho intravisto un ragno alieno che non promette bene). Genitori sul divano, bambini acquattati dietro il divano, nella più classica tradizione di Doctor Who.
Questo è il testo della puntata del 3 marzo 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Per un’intera generazione di utenti, questo suono è familiare quanto quello della classica suoneria Nokia: è l’avviso di una chiamata Skype in arrivo. La tecnologia corre così in fretta che è facile dimenticarsi di quanto fu rivoluzionario questo software al suo debutto ben ventidue anni fa. Parlarsi via Internet, e anche vedersi in videochiamata, oggi è assolutamente normale; non lo era nel 2003.
Ma la corsa della tecnologia ha anche un’altra conseguenza: quel suono familiare presto sarà archiviato, perché Microsoft ha deciso, abbastanza di colpo, che Skype non sarà più disponibile a partire dal prossimo 5 maggio.
Questa è la storia di Skype, delle sue origini tutte europee un po’ dimenticate, di come ha contribuito a trasformare le nostre abitudini e di come verrà ingloriosamente archiviato e sostituito: Microsoft ha predisposto un percorso facilitato di migrazione al suo prodotto analogo Teams, ma ci sono anche altre soluzioni alternative.
Benvenuti alla puntata del 3 marzo 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Siamo nel 2003. È il 29 di agosto. A Stoccolma una ventina di persone si raduna per assistere al debutto online di un software, sviluppato da loro, che consente di fare telefonate via Internet, da un computer a un altro, in qualunque luogo del mondo, e consente di farlo facilmente e soprattutto gratis a prescindere dalla distanza fra i due interlocutori. È una rivoluzione vera e propria, in un’epoca in cui le conversazioni a lunga distanza sono un sostanziale monopolio delle compagnie telefoniche e hanno costi molto elevati e i messaggi vocali di WhatsApp che oggi consideriamo normali o addirittura essenziali sono pura fantascienza. Mancano infatti quattro anni al debutto del primo iPhone (nel 2007) e WhatsApp nemmeno esiste (arriverà nel 2009 e i suoi “vocali” inizieranno nel 2014).
Nel 2003 ci sono già altri software che permettono di trasportare la voce via Internet, ma sono complicati da installare e ancora più complicati da configurare. Questo, invece, si installa in pochi semplici passaggi e non richiede modifiche dei firewall aziendali o altre complessità tipiche dei suoi concorrenti. E così, il primo giorno il software viene scaricato da diecimila persone. Nel giro di un paio di mesi ha già un milione di utenti. Lo stupore di potersi parlare via Internet è ovunque.
Questo software, come avrete intuito, è quello che oggi chiamiamo Skype. Inizialmente, però, il nome previsto era un altro. Era Skyper: un po’ per assonanza con Napster, uno dei software più popolari e controversi di quegli anni, e un po’ come fusione di sky (cielo) e peer, dato che impiega la stessa tecnologia di trasmissione adoperata dai circuiti peer-to-peer per lo scambio di musica e film via Internet. Ma ahimè il dominio Skyper.com è già occupato, e così Skyper perde la R e diventa Skype.
L’assonanza del nome non è l’unico legame di Skype con i circuiti peer-to-peer: i fondatori di Skype sono lo svedese Niklas Zennström e il danese Janus Friis, e il software è stato scritto da un gruppo di programmatori estoni. Sono le stesse persone che due anni prima hanno creato Kazaa, un popolarissimo programma concorrente di Napster, e ora hanno adattato la tecnologia di Kazaa alla telefonia online.
Viste le grane legali che hanno avuto con le case discografiche per colpa di Kazaa, accusato di facilitare la pirateria audiovisiva di massa, Zennström e Friis hanno deciso di integrare immediatamente in Skype la crittografia, in modo che le chiamate fatte via Skype non siano intercettabili. Ovviamente questo fa diventare Skype uno dei software prediletti dai criminali di tutto il mondo oltre che dalle persone comuni che vogliono semplicemente parlare con amici e parenti lontani senza svenarsi.
Altrettanto ovviamente, le compagnie telefoniche non vedono con piacere l’avvento di questo concorrente che li spiazza completamente offrendo gratis il servizio che loro invece fanno pagare, ma legalmente non c’è nulla che possano fare per impedirlo, anche perché Zennström e Friis fanno in modo che Skype, intesa come azienda, non sia classificabile come operatore telefonico, perché non offre chiamate da un numero telefonico a un altro, ma solo da un numero telefonico a un computer oppure da un computer a un numero di telefono.
A settembre del 2005, dopo due anni di crescente successo e di espansione dell’azienda, Skype viene venduta a eBay per due miliardi e 600 milioni di dollari. Il suo software diventa man mano una delle applicazioni fondamentali di Internet, con oltre seicento milioni di utenti registrati e circa 300 milioni di utenti attivi mensili. Ma i giganti del software stanno sviluppando prodotti concorrenti: Google, Microsoft, Yahoo, Facebook, Apple e altri, come Viber, alitano sul collo di Skype, che nel frattempo ha aggiunto le videochiamate.
Una pagina del sito di Skype com’era nel 2011. Fonte: Archive.org.
Nel 2011, Microsoft compra Skype per otto miliardi e mezzo di dollari. È l’acquisto più costoso mai fatto fino a quel punto dal colosso di Redmond. Skype viene integrato nei servizi di Microsoft, tanto da diventare l’app di messaggistica predefinita di Windows 8.1, e viene progressivamente trasformato. Nascono le versioni per Mac, iPhone, iPad, Android, BlackBerry e anche Linux, e arriva anche Skype for Business, che però è in realtà un prodotto completamente distinto che ha in comune con Skype soltanto il nome e l’estetica.
Sembra l’apice del successo, ma in realtà il destino di Skype è già segnato.
L’integrazione di Skype in Windows, infatti, non procede per il meglio, e Microsoft ha già iniziato l’acquisizione e lo sviluppo di quello che oggi tutti conosciamo come Teams per sostituire Skype. Nel 2021 Skype for Business viene chiuso e in Windows 11 c’è Teams al posto di Skype; negli anni successivi, con molta calma, vengono disattivati i servizi di contorno di Skype standard, che è ancora usato giornalmente da quasi quaranta milioni di utenti. I segnali delle intenzioni di Microsoft a lungo termine sono dunque molto chiari. Ma l’annuncio vero e proprio della fine di questa app che ha fatto la storia di Internet arriva in maniera inaspettata, e non è Microsoft a darlo.
Il 28 febbraio scorso, infatti, il sito XDA Developers ha annunciato la scoperta, all’interno della versione di anteprima più recente di Skype per Windows, di una dicitura sibillina ma inequivocabile che avvisa in inglese che “a partire da maggio, Skype non sarà più disponibile. Prosegui le tue chiamate e le tue chat su Teams”. Poche ore dopo è arrivata la conferma ufficiale di Microsoft.
Mentre le fasi precedenti della progressiva eliminazione di Skype erano state annunciate con ampi margini di tempo (per esempio quattro anni per Skype for Business), stavolta quella quarantina di milioni di utenti rimasti ha meno di dieci settimane di tempo per riorganizzarsi e decidere cosa fare.
Dal 5 maggio prossimo Skype non sarà più disponibile, ma chi ha pagato un abbonamento potrà continuare a usarlo fino alla scadenza e chi ha del credito sul proprio conto Skype potrà continuare a sfruttarlo. Prima del 5 maggio, gli utenti di Skype potranno scaricare la versione gratuita di Teams e usare in Teams le proprie credenziali Skype su qualunque dispositivo supportato. Le chat e i contatti di Skype appariranno automaticamente in Teams [video]. Durante la transizione, chi usa Skype potrà chiamare gli utenti Teams e viceversa.
Ma a Teams gratuito mancano alcune delle caratteristiche che rendevano Skype così interessante: in particolare manca la possibilità di fare chiamate verso numeri telefonici e di ricevere chiamate provenienti dalla rete telefonica fissa e cellulare. Si poteva infatti avere un numero telefonico Skype al quale farsi chiamare, cosa che invece Microsoft offre soltanto nella versione a pagamento di Teams.
Se usate Skype e non fate la migrazione a Teams entro il 5 maggio prossimo, Microsoft conserverà comunque i vostri dati di Skype fino alla fine del 2025. Potrete quindi decidere di installare Teams gratuito anche dopo il 5 maggio senza perdere chat e contatti, ma se non agite entro dicembre i vostri dati di Skype verranno cancellati definitivamente.
In alternativa, potete esportare questi dati seguendo le istruzioni di Microsoft (che trovate linkate su Attivissimo.me) in modo da poterli poi importare in un’altra applicazione a vostra scelta, ma al momento mancano strumenti per automatizzare questa importazione.
Se sopportate il disagio di dover reimmettere a mano i vostri contatti e di perdere la vostra cronologia delle chat, le soluzioni alternative a Teams per fare e ricevere chiamate vocali non mancano di certo oggigiorno. Moltissime app social molto diffuse consentono chiamate, spesso anche in video e in gruppo: WhatsApp, Facetime, Instagram, Zoom, Snapchat, Facebook Messenger, Viber, Google Chat, Google Meet, X, Telegram, Discord, giusto per citarne qualcuna, e anche nel fediverso ci sono applicazioni che hanno questa funzione. Il problema è che ciascuno di questi software non parla con gli altri, per cui tocca ogni volta concordare con i propri interlocutori quale app usare. Inoltre di solito manca la possibilità di chiamare numeri di telefono di rete fissa, ma questo oggi è un problema molto meno sentito che in passato, visto che gli smartphone e gli abbonamenti che includono una connessione continua a Internet sono diffusissimi e le chiamate verso numeri fissi sono sempre più rare.
Con la chiusura di Skype si abbassa ulteriormente il sipario su un periodo storico di Internet: Skype è una delle poche applicazioni di grande diffusione che risale ai primi anni duemila, quando la comunicazione online e mobile era ancora tutta da inventare, ed è ancora in uso adesso, ed è stata una di quelle che davano il classico “effetto wow”: non appena la vedevi usare, ne capivi subito l’utilità e il potenziale rivoluzionario. Ed è anche grazie a Skype che le tariffe telefoniche si sono trasformate radicalmente rispetto a vent’anni fa. Concetti come la tariffa interurbana o quella ridotta notturna per le chiamate sono oggi ricordi sbiaditi che cominciano di ammantarsi di immeritata nostalgia.
Ma lo Skype originale, quello pre-Microsoft, aveva anche un altro grande pregio: faceva una sola cosa, e la faceva bene e in modo chiaro e intuitivo. Oggi tutte le app cercano di fare tutto, tipicamente in modo incompatibile fra loro, creando complessità e confusione, e ovviamente non possono fare a meno di incorporare l’onnipresente intelligenza artificiale. Quella che, fra l’altro, Microsoft aveva infilato anche nelle ultime versioni di Skype, e che troverete naturalmente saldamente integrata in Teams, se decidete di adottarlo come sostituto. Buona migrazione.
A proposito di Teams: prima di chiudere, devo fare una rettifica alla puntata del 24 febbraio scorso, quella dedicata a una tecnica di attacco informatico nella quale gli aggressori fingono di essere l’assistenza tecnica di Microsoft che contatta le vittime tramite Teams dal dominio in apparenza rassicurante Onmicrosoft.com.
Nel podcast ho detto erroneamente che questo nome di dominio appartiene ai criminali, ma in realtà è di Microsoft e i criminali si limitano a sfruttare il fatto che Microsoft assegna questo nome di dominio agli utenti Teams che non ne hanno uno proprio o non lo connettono a Microsoft 365.
Il risultato è che i messaggi Teams dei truffatori provengono da un indirizzo di mail che termina con onmicrosoft.com e quindi è facile scambiarli per messaggi dell’assistenza tecnica di Microsoft. Ringrazio i lettori e gli ascoltatori del podcast che hanno notato il mio errore.
È andata in onda lunedì scorso alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
In questa puntata abbiamo parlato, fra le altre cose, di:
cronologia degli spazzolini da denti (ricorreva l’anniversario di una tappa importante nell’evoluzione di questo strumento) [Smileconcepts.co.uk; Colgate.com]
anniversario delle nascite di Steve Jobs e Salvatore Aranzulla
account Instagram strano della settimana: @breadfaceblog, video di persone che ficcano la faccia dentro torte e impasti alimentari di vario genere
sadcore, una recente tendenza truffaldina nei social network che sfrutta la compassione per fare soldi: i truffatori postano immagini commoventi di situazioni tristi (generate con l’intelligenza artificiale), presentandole come se fossero vere, e poi ricevono soldi dagli utenti Facebook che ci cascano e donano soldi attraverso le “stelle” disponibili in alcuni paesi come moneta di micropagamento su Facebook [BoingBoing; Newslttrs.com; FAQ di Facebook]
Questo è il testo della puntata del 24 febbraio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Hollywood come sempre esagera la realtà, ma è vero che gli attacchi informatici stanno diventando sempre più rapidi: secondo una ricerca appena pubblicata, nel 2024 la loro velocità è aumentata mediamente del 22% rispetto all’anno precedente. In un caso recentissimo, agli aggressori sono bastati 48 minuti per penetrare le difese informatiche di un’azienda del settore manifatturiero e cominciare a saccheggiarne i dati, per poi chiedere un riscatto per restituirli o non pubblicarli.
Questa è la storia di quell’attacco, spiegata in dettaglio, utile per capire come lavorano oggi i criminali informatici e come ci si può difendere concretamente riconoscendo i primi segnali di un’incursione informatica.
Benvenuti alla puntata del 24 febbraio 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Siamo a dicembre del 2024 e sono passate da poco le cinque del pomeriggio di un giorno lavorativo qualsiasi. Il gruppo di criminali informatici russofoni noto agli addetti ai lavori con il nome di Black Basta inizia il proprio attacco a un’azienda del settore manifatturiero. Una delle tante che in tutto il mondo vengono prese di mira ogni giorno.
Per prima cosa i criminali mandano a una quindicina di dipendenti dell’azienda un’ondata massiccia di mail di spam, che intasa le loro caselle di posta e produce un numero spropositato di notifiche che rendono impossibile lavorare: una scocciatura particolarmente irritante, visto che arriva alla fine di una giornata lavorativa. Ma non è questo l’attacco vero e proprio: è solo un diversivo scelto con attenzione.
Alle 17 e 26 minuti, alcuni dei dipendenti bersagliati dal flusso incessante di spam ricevono un messaggio Teams dall’helpdesk informatico di Onmicrosoft.com, che offre soccorso per arginare la pioggia di mail spazzatura. Due di questi dipendenti ricevono poi una chiamata via Teams che li invita ad aprire Quick Assistant (o Assistenza rapida nella versione italiana), lo strumento Microsoft di accesso remoto, e a dare all’assistenza informatica il controllo dei loro computer. Uno dei dipendenti accetta l’invito e attiva la gestione remota del computer, lasciandola aperta per una decina abbondante di minuti. Sono le 17 e 47: sono passati solo ventuno minuti dall’inizio dell’attacco e i ladri sono già sulla soglia dei sistemi informatici aziendali.
Infatti Onmicrosoft.com non è un dominio di Microsoft: appartiene ai criminali, che si stanno fingendo operatori dell’assistenza tecnica Microsoft.* La tattica di usare un’ondata di spam come diversivo è particolarmente efficace, perché queste mail di spam in sé non contengono nulla di pericoloso e quindi i sistemi di sicurezza non le bloccano. Le vittime non hanno neanche bisogno di interagire con queste mail, come avviene invece negli attacchi tradizionali in cui l’aggressore deve convincere il bersaglio a cliccare su un link ostile presente nella mail. Lo scopo della valanga di messaggi spazzatura è semplicemente causare agitazione nella vittima e creare una giustificazione plausibile per la chiamata immediatamente successiva su Teams dei criminali che fingono di essere l’assistenza tecnica di Microsoft. E il fatto che il messaggio arrivi via Teams, invece che da una mail tradizionale, rende tutto ancora più plausibile.
* CORREZIONE: In realtà Onmicrosoft.com è un dominio di Microsoft, ma viene sfruttato dai criminali per spacciarsi per Microsoft [info]: è un dominio usato da Microsoft come fallback se non si è proprietari di un dominio o se non lo si vuole connettere a Microsoft 365. Ho interpretato male questa frase del rapporto tecnico: “the threat actor sent a Teams message using an external “onmicrosoft.com” email address. These domains are simple to set up and exploit the Microsoft branding to appear legitimate.“. Grazie a 764081 per la segnalazione del mio errore.
Dal punto di vista della vittima, infatti, è semplicemente arrivata un’ondata di spam ed è giunta prontamente la chiamata Teams dell’assistenza tecnica Microsoft che si è offerta di risolvere il problema. Nulla di sospetto, anzi: alla vittima fa anche piacere sapere che l’assistenza clienti è veloce e pensa lei a tutto, soprattutto quando è ora di lasciare l’ufficio.
Dal punto di vista degli aggressori, invece, l’attacco è particolarmente efficace, perché non richiede di convincere la vittima a installare app di dubbia provenienza. Tutto il software necessario per avviare l’attacco è infatti già presente nei computer dell’azienda: basta convincere qualcuno, anche uno solo dei tanti dipendenti, a cederne momentaneamente il controllo.
È una trappola tecnica e psicologica perfetta. E infatti pochi minuti dopo che la vittima ha passato il controllo remoto del proprio computer ai criminali pensando di darlo invece al soccorso informatico Microsoft, gli aggressori iniziano la loro scorribanda.
Sono le 17 e 56: nei nove minuti trascorsi da quando hanno ottenuto il comando remoto del computer aziendale del dipendente caduto nella trappola, gli aggressori hanno collegato quel computer al loro server di comando e controllo,* e cosi la breccia temporanea aperta dall’incauto utente è ora un tunnel permanente.
* Lo hanno fatto aprendo le porte 443 e 10443 tipicamente riservate per il traffico criptato TLS e usando un beacon di OneDrive che punta a un indirizzo IP controllato dagli aggressori.
Attraverso questo tunnel, gli aggressori non installano un programma ostile, come è facile immaginarsi che facciano, ma si limitano a depositare una versione appositamente modificata a loro favore di un componente software comune, in termini tecnici una libreria a collegamento dinamico o DLL*, mettendola in una cartella OneDrive usata per effettuare gli aggiornamenti del software dell’azienda presa di mira.
* Il nome del file in questo caso è winhttp.dll.
Per via del modo in cui funzionano Windows e le sue applicazioni,* quel componente software modificato verrà eseguito dalle applicazioni aziendali al posto della sua versione originale. Questa è una tecnica sofisticata, chiamata DLL sideloading.In altre parole, il sistema informatico dell’azienda è già infettato e pronto per essere devastato.
* Le applicazioni cercano le DLL di cui hanno bisogno prima di tutto nella propria cartella e poi altrove, e quindi gli aggressori piazzano la DLL ostile nella cartella che ospita un’applicazione vulnerabile, sapendo che verrà eseguita al posto della DLL originale situata altrove.
I criminali attivano l’infezione usando PowerShell, un altro strumento presente nei sistemi Windows, e il componente software modificato viene eseguito negli account degli amministratori di sistema, che sono abilitati ad accedere a molte più risorse di un account utente normale. Con questo potere, gli aggressori riescono a trovare delle credenziali* che permettono loro di creare un nuovo account con i massimi permessi di amministrazione.
* Sono quelle di un account di servizio usato per gestire un database SQL.
A questo punto i criminali hanno il controllo totale della rete informatica del bersaglio e possono fare sostanzialmente tutto quello che desiderano. Infatti usano addirittura il software di sicurezza dell’azienda [Network Scanner di Softperfect] per trovare altre vulnerabilità da sfruttare per esfiltrare i dati di lavoro, ossia portarsi via una copia integrale di tutte le informazioni che servono all’azienda per poter lavorare, allo scopo di rivendere quelle informazioni sul mercato nero dei dati rubati oppure di ricattare l’azienda stessa con la minaccia di pubblicarli, con tutti i problemi legali di privacy che questo comporterebbe, oppure ancora di cancellarli dai computer dell’azienda e fornirne una copia solo dietro lauto pagamento.
Sono le 18.35. In 48 minuti i criminali informatici sono passati dal trovarsi sulla soglia a essere onnipotenti. Nel giro di poco più di un giorno completeranno l’esfiltrazione dei dati aziendali e il saccheggio informatico sarà pronto per essere monetizzato. Nel caso specifico, l’azienda riuscirà a contenere il danno scollegando da Internet vari data center, ma questo comporterà blocchi della produzione ed enormi disagi nel flusso di lavoro.
Come si fa a evitare di trovarsi in queste situazioni? La formazione del personale, e di tutto il personale, ossia di chiunque metta mano a un computer, è ovviamente essenziale: tutti devono conoscere l’esistenza di queste tecniche di attacco e abituarsi a riconoscerne i sintomi e a non fidarsi delle chiamate Teams o di altro genere che sembrano provenire dall’assistenza informatica di Microsoft o di qualunque altro fornitore di servizi. Tutti devono rendersi conto che gli attacchi informatici non sono un problema che riguarda solo gli addetti ai servizi informatici. Serve anche un modo affidabile e pratico per verificare le identità degli interlocutori quando la conversazione non avviene in presenza: cose come parole d’ordine concordate, per fare un esempio.
Ma c’è anche una parte tecnica importante che va ripensata e gestita correttamente non dagli utenti ma da parte degli amministratori dei sistemi informatici e dei loro superiori. Le applicazioni di accesso remoto, come Assistenza rapida di Microsoft, andrebbero disinstallate ovunque sia possibile o perlomeno rese meno facilmente accessibili agli utenti, e gli account degli utenti che interagiscono con un tentativo di furto anche solo sospettato andrebbero bloccati e isolati immediatamente. Tutte cose che hanno un costo e comportano disagi e scomodità e quindi spesso non vengono fatte.
E la lezione più importante che ci offre questa vicenda è che gli intrusi stanno diventando sempre più veloci, grazie anche all’automazione dei loro attacchi consentita dall’intelligenza artificiale, che stanno usando a piene mani e senza scrupoli, e quindi i tempi di reazione devono adeguarsi e gli interventi di protezione devono essere il più possibile automatici e drastici. L’idea ancora molto diffusa di avere un servizio di supporto informatico solo in orari d’ufficio, per contenere i costi, non è soltanto obsoleta: è di fatto pericolosa. Perché i criminali informatici non rispettano gli orari di lavoro o le ferie.
C’è un epilogo positivo a questa vicenda: Black Basta, il gruppo criminale al quale è stato attribuito l’attacco che ho descritto qui, è in crisi. Le sue chat interne sono state infatti trafugate e pubblicate online, permettendo a studiosi e ricercatori di sicurezza di analizzare tattiche, segreti professionali e liti fra i suoi membri, disseminati su oltre 200.000 messaggi [Ars Technica]. Uno dei suoi leader è stato arrestato, e questo aumenta le possibilità che vengano rintracciati anche gli altri componenti. E un altro dei capi di Black Basta ha commesso l’errore strategico di attaccare le infrastrutture di alcune banche russe, col risultato di attirare sulla banda le attenzioni decisamente indesiderate delle autorità di polizia del paese.
Alla fine, i peggiori nemici dei criminali sono i criminali stessi.
È andata in onda lunedì scorso alle 9 una nuova puntata in diretta di Niente Panico, il programma che conduco insieme a Rosy Nervi settimanalmente sulla Rete Tre della Radiotelevisione Svizzera. La trasmissione è riascoltabile presso www.rsi.ch/rete-tre/programmi/intrattenimento/serotonina oppure nell’embedqui sotto.
somiglia molto al “vecchio” Twitter, di cui però non ha i messaggi diretti (o pseudo-privati)*; è tutto pubblico, e tutto sommato è meglio così, visto che ora i messaggi “privati” su Twitter sono tutti in mano a Elon Musk e la sua banda di scellerati.
* Correzione: li ha, ma sono limitati per default. Come impostazione predefinita, posso fare chat “private“ solo con le persone che seguo. Se voglio cambiare quest’impostazione, devo andare nelle Impostazioni, scegliere Messaggi, cliccare sull’icona a sinistra del tasto "Nuova chat" (oppure da web usare il link diretto https://bsky.app/messages/settings) e scegliere se accettare messaggi da tutti, dagli utenti che seguo o da nessuno. Per ora non sono protetti con crittografia end-to-end; i moderatori di Bluesky possono leggerli [Bluesky]. Grazie a DZ per la correzione.
Fa strano che a un anno dal debutto e con 30 milioni di utenti, la sua autenticazione a due fattori sia ancora basata esclusivamente sulla mail.
Ed è irritante che i post, una volta pubblicati, non siano modificabili (salvo usare accrocchi tramite app particolari) come lo sono invece per esempio su Mastodon, nemmeno temporaneamente per correggere qualche refuso.
Va be’, proviamo comunque anche questo. Ho messo un avviso su X, così se qualcuno ancora mi legge là, sa dove trovarmi. Resto comunque fedele a Mastodon (i cui post sono su Bluesky tramite bridge, presso @ildisinformatico.mastodon.uno.ap.brid.gy).
Avete già provato Bluesky? Cosa ne pensate?
2025/02/23. Aggiungo un consiglio arrivato nei commenti (grazie DZ!): per default Bluesky mostra solo i post scritti nelle lingue definite automaticamente nelle impostazioni, e questo può essere un filtro non intenzionale e indesiderato. Se volete vedere tutti i post a prescindere dalla lingua, o selezionare le lingue da rendere visibili, andate in Impostazioni – Lingue – Lingue dei contenuti – e selezionate le lingue da visualizzare. Disattivandole tutte si vede qualunque post in qualunque lingua.
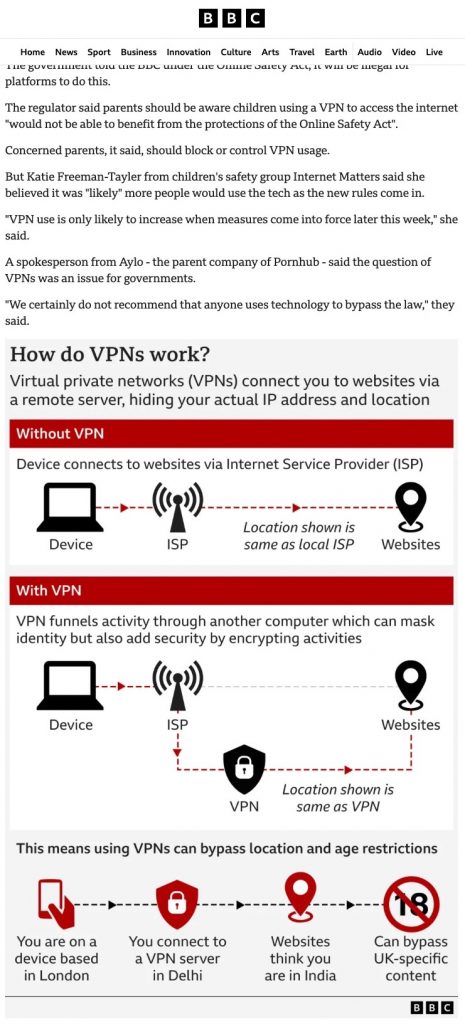
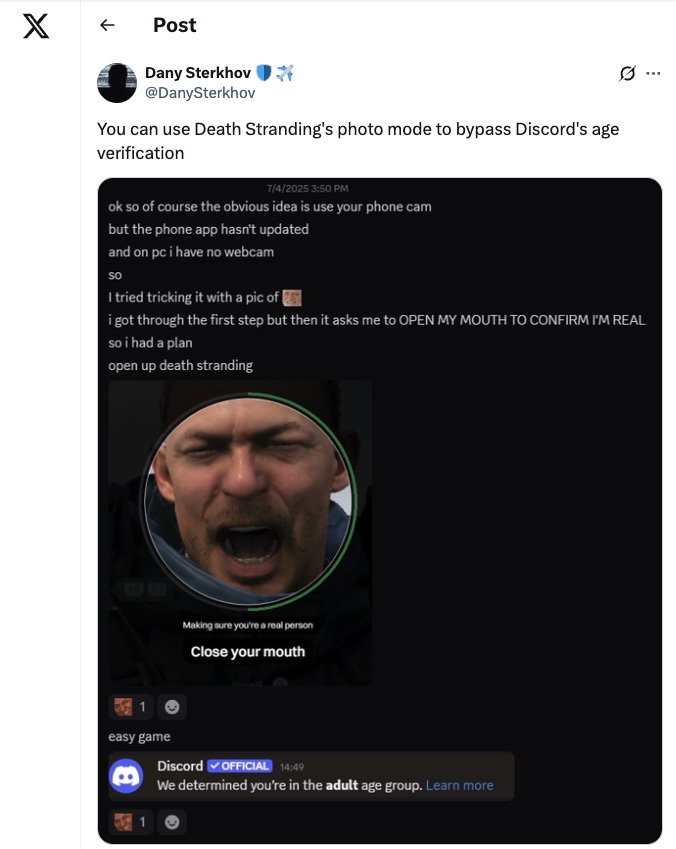

















































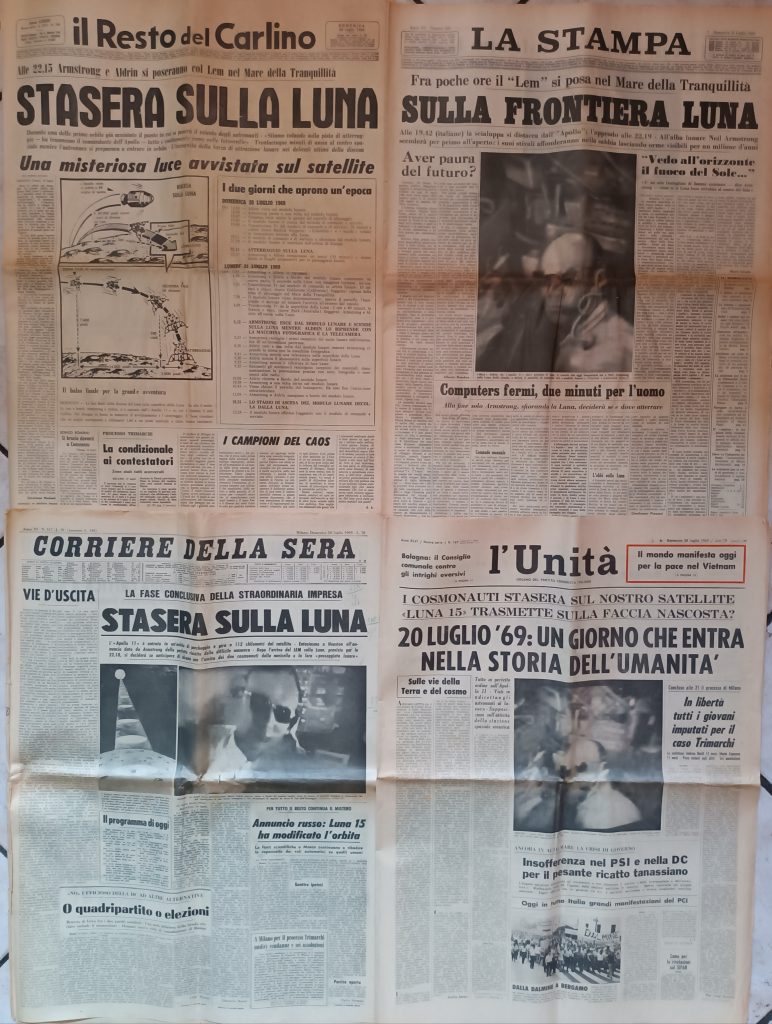


















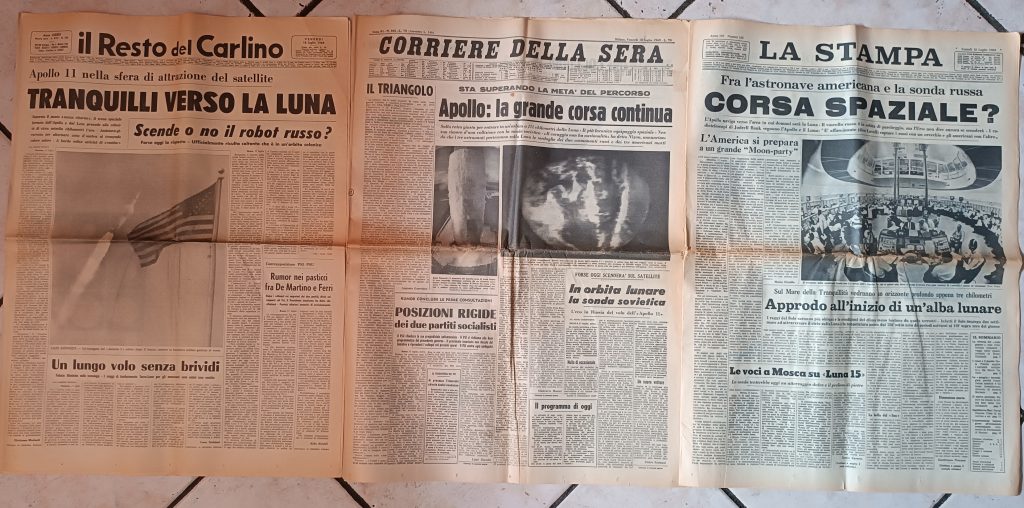






















































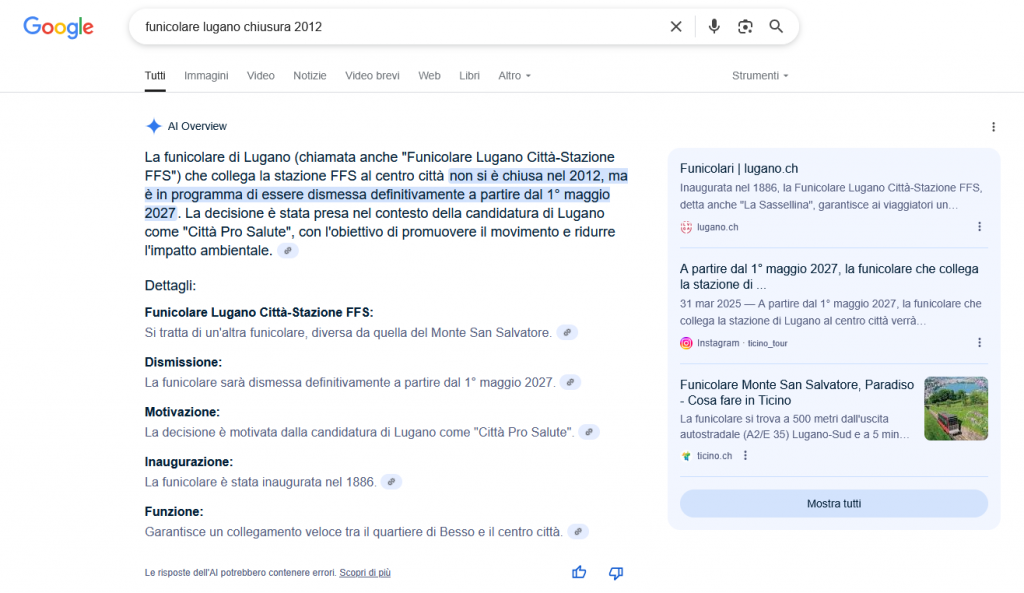




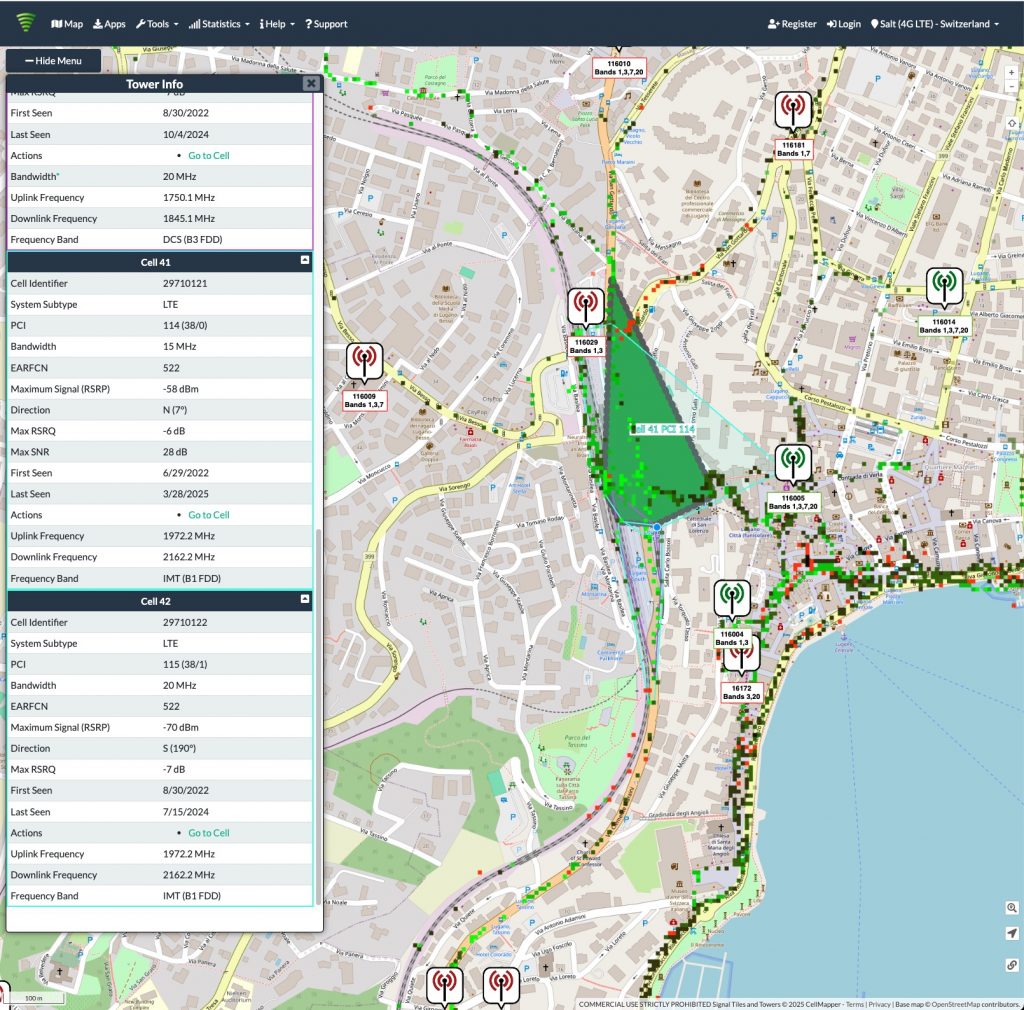































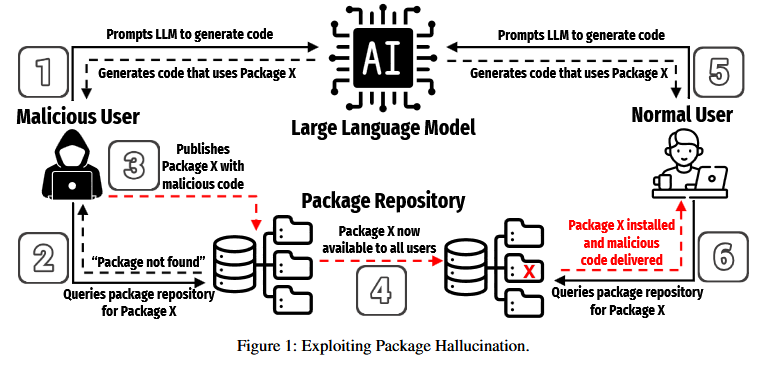






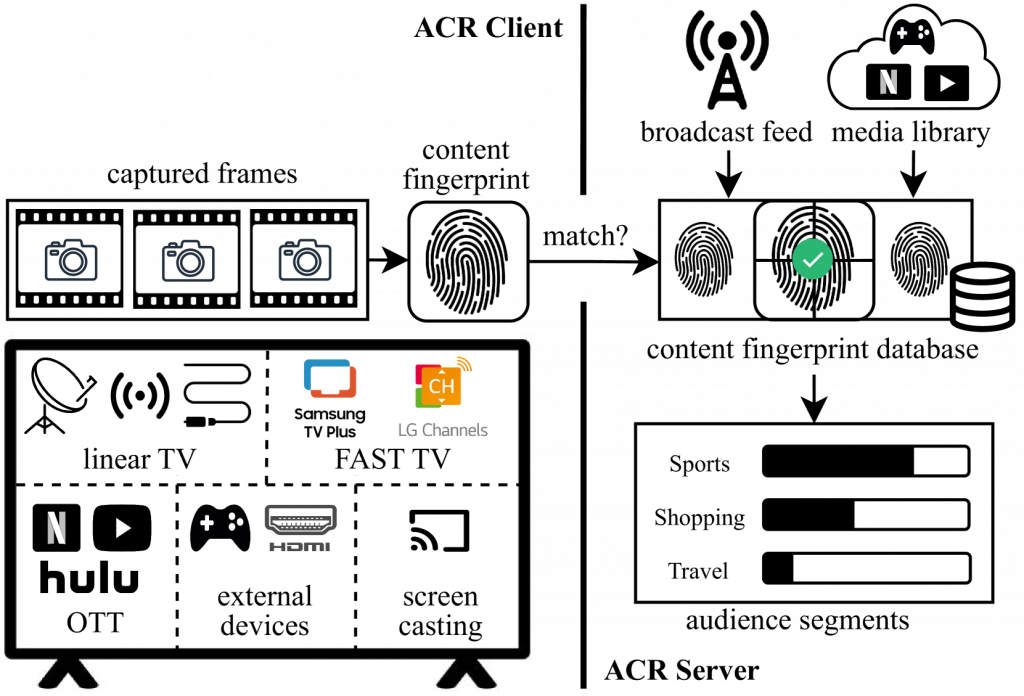



















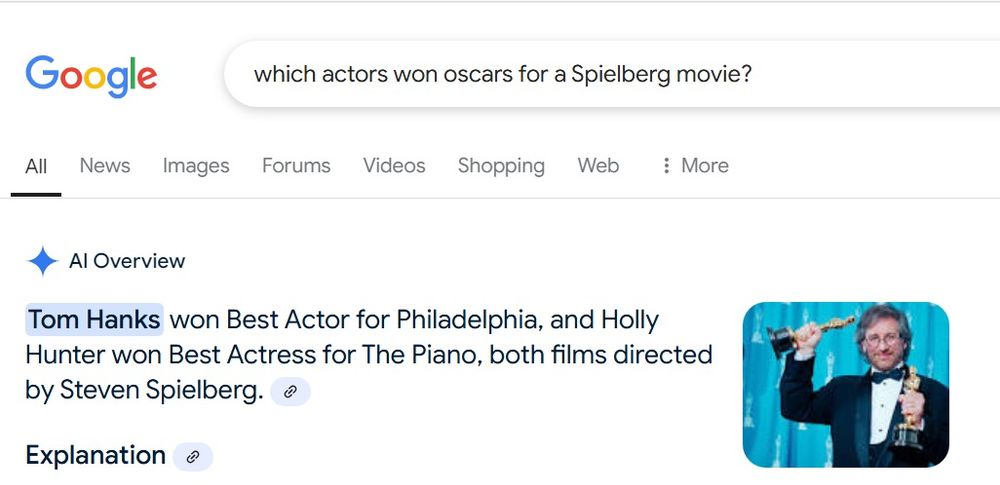




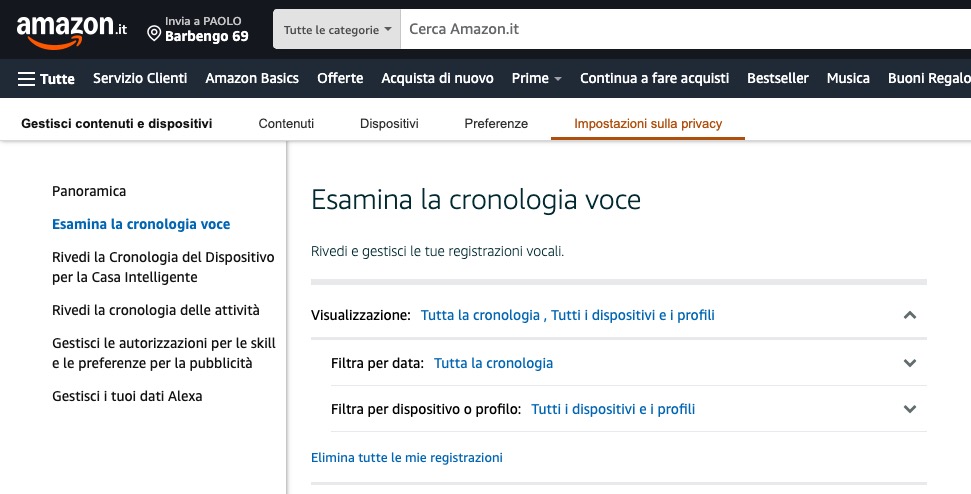
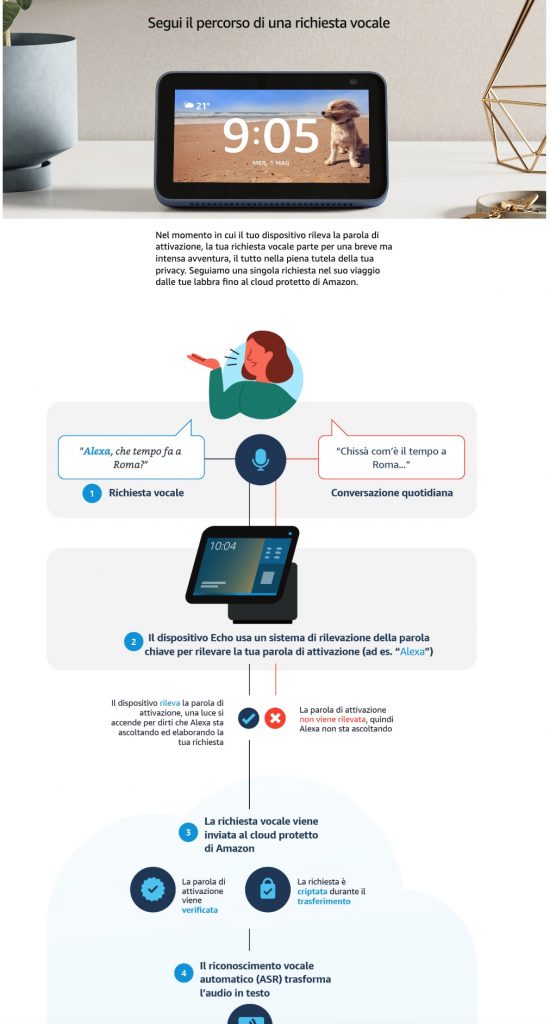




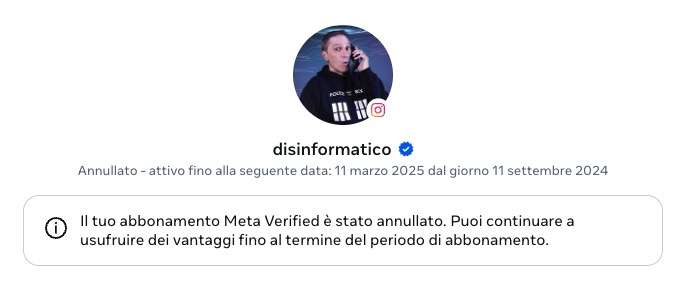
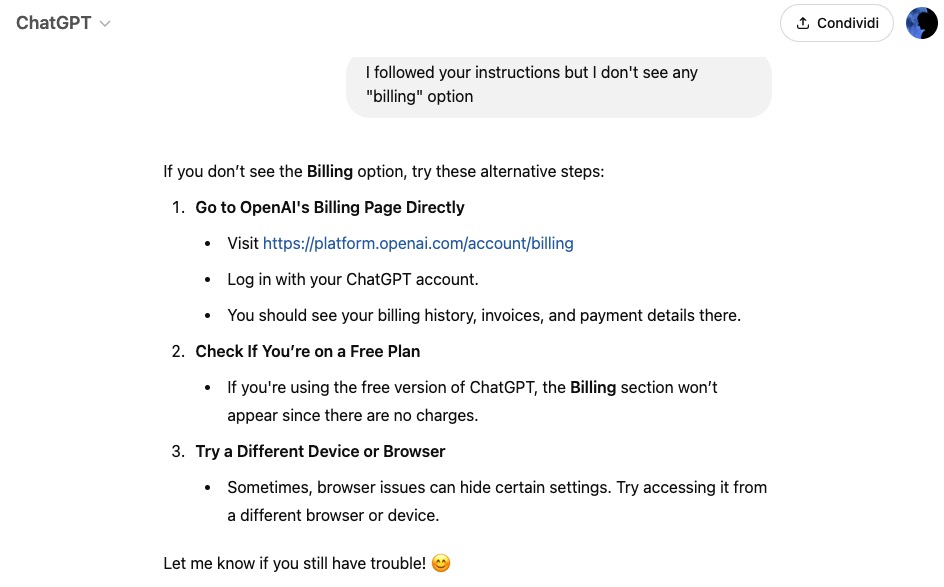
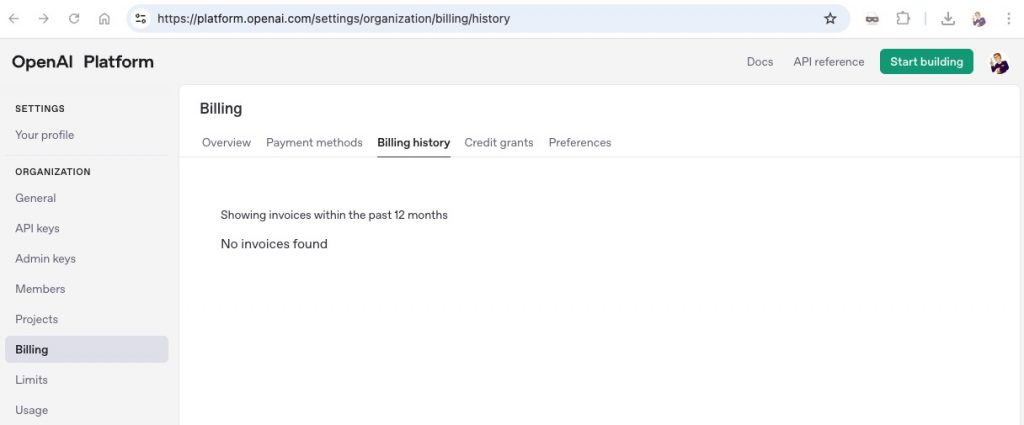
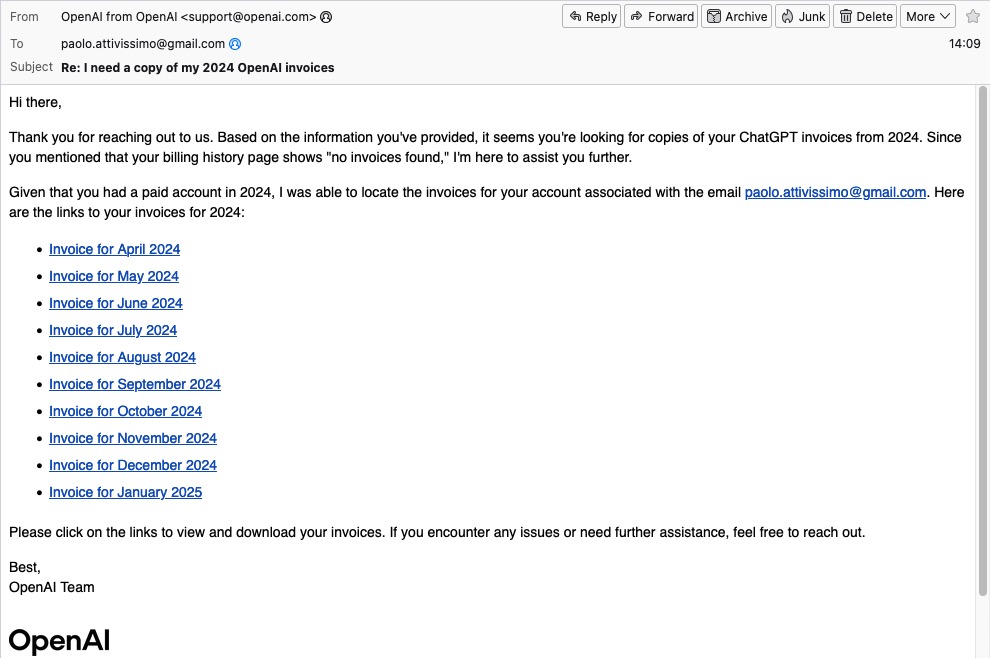

{kind=link}