Podcast RSI – Identità elettronica: pro e contro tecnici, promesse e preoccupazioni
Questo è il testo della puntata del 29 settembre 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Le puntate del Disinformatico sono ascoltabili anche tramite iTunes, YouTube Music, Spotify e feed RSS. Il mio archivio delle puntate è presso Attivissimo.me/disi.
[CLIP: varie voci che chiedono “Mi dà un documento per favore?”]
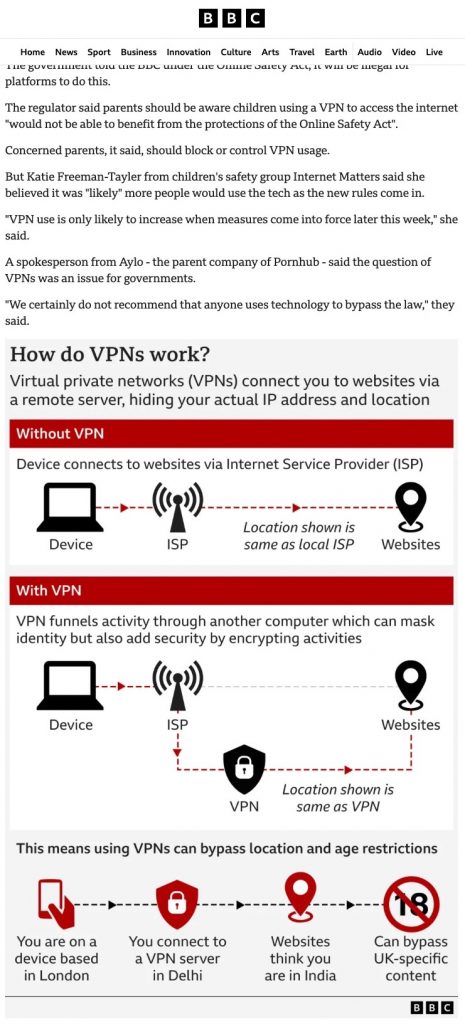
Immaginatevi di rispondere a questa richiesta senza dover frugare nella borsa o nel portafogli per trovare una tessera consunta che ha su una vostra foto venuta male. Immaginate che non vi vada a genio l’idea di dare a uno sconosciuto l’elenco completo dei fatti vostri impressi su quella tessera, compreso l’indirizzo di casa come avviene nei documenti di alcuni paesi,* quando in realtà dovete dimostrare soltanto di essere maggiorenni o di essere chi dite di essere. O immaginate di essere online e che un sito di acquisti o un social network vi chieda una foto di un documento o addirittura di fare una scansione tridimensionale del vostro volto.
* La carta d’identità elettronica italiana, per esempio, include l’indirizzo di residenza, il codice fiscale e vari altri dati personali.
Ora immaginate di poter rispondere a queste situazioni semplicemente mostrando il vostro smartphone, che fornirà al vostro interlocutore soltanto le informazioni strettamente necessarie al caso specifico, garantite e autenticate dallo Stato. Questa è la promessa del cosiddetto Id-e o e-ID o mezzo di identificazione elettronico, già disponibile in numerosi Paesi.
Ma questa promessa è accompagnata anche da alcune preoccupazioni. Si teme di barattare la comodità con la sicurezza e di svendere la riservatezza in cambio dell’efficienza. Ci si preoccupa che si possa aprire gradualmente la porta a una sorveglianza di massa informatizzata e a vulnerabilità informatiche e che si finisca per escludere dalla società chi non ha o non può avere uno smartphone.
Benvenuti alla puntata del 29 settembre 2025 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica e focalizzato, in questo caso, sui pro e i contro delle identità elettroniche. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Ci siamo abituati ormai da tempo all’idea che per acquistare certi prodotti, accedere a vari posti, fruire di determinati servizi o chiedere documentazione alla pubblica amministrazione si debba presentare un documento d’identità. Spesso non si tratta soltanto di esibire momentaneamente un documento a qualcuno che lo verifica al volo, ma quel documento viene anche scansionato o fotocopiato o comunque conservato, non sempre legittimamente, da chi ce lo ha chiesto.
E questa conservazione, a volte, non è particolarmente diligente. Lo testimonia il fatto che immettendo semplicemente in Google le parole chiave giuste emergono migliaia di scansioni di documenti d’identità perfettamente leggibili, archiviate maldestramente in qualche cloud mal configurato, a disposizione del primo truffatore che passa, e anche del secondo e del terzo. La gestione e la custodia corretta di questi dati personali rappresentano un costo importante per le amministrazioni e per le aziende.
Con la graduale introduzione dei controlli di età minima nei social network e nei siti di acquisti e di incontri, ci siamo anche abituati a dare a queste mega-aziende una scansione 3D del nostro volto oppure una foto fronte-retro di un nostro documento di identità. Quel documento contiene nome, cognome, indirizzo, data di nascita esatta, foto del volto e molte altre informazioni personali in più rispetto a quelle realmente necessarie per una semplice verifica dell’età. Una sovrabbondanza di dati che queste aziende divorano con entusiasmo per fare profilazione di massa delle persone insieme ai nostri like, alla rete dei nostri contatti e alla nostra localizzazione.
Questi problemi evidenti di sicurezza, riservatezza e costo della situazione attuale possono essere ridotti drasticamente con un sistema di identificazione elettronica come quelli già esistenti da molti anni in vari Paesi europei e come quello previsto in Svizzera dalla legge federale approvata dalla votazione popolare di ieri.
L’identificazione elettronica svizzera che viene proposta è gestita direttamente dallo Stato, che la rilascia e ne è responsabile, e si basa su standard tecnici aperti. I dati personali vengono custoditi e trattati a bordo dello smartphone dell’utente, in un’app statale chiamata Swiyu per iOS e Android [codice su Github]. Tutta la gestione ha luogo su computer dell’infrastruttura della Confederazione e quindi i dati non finiscono in qualche cloud aziendale magari d’oltreoceano, come avviene invece con le identificazioni online attuali.
Inoltre i dati che vengono trasmessi durante l’uso sono solo quelli strettamente necessari: per esempio, se un negozio fisico o online deve verificare un’età, riceverà soltanto l’informazione che il cliente ha più di 18 anni e nient’altro. Con i sistemi attuali, invece, il negozio viene a sapere, e finisce per archiviare, tutte le informazioni presenti sul documento tradizionale mostrato o trasmesso online. La privacy è insomma maggiormente protetta se si usa un’identificazione elettronica.
I dati scambiati sono protetti dalla crittografia e non sono riutilizzabili da terzi, per cui intercettarli è sostanzialmente inutile, e per chi li riceve è semplice verificare che siano autentici. Invece superare gli attuali controlli usando una carta d’identità tradizionale falsificata o trovata su Internet è relativamente facile, soprattutto online.
I documenti di identificazione tradizionali, inoltre, possono essere rubati e usati abusivamente fino alla loro scadenza prefissata, salvo che ci siano complessi coordinamenti fra archivi delle denunce di furto o smarrimento e negozi o servizi pubblici, mentre l’identificazione elettronica è facilmente revocabile in qualunque momento e cessa immediatamente di essere usabile ovunque.
Fra l’altro, la revocabilità non va vista come una procedura d’emergenza, come lo è nel caso dei documenti d’identità cartacei, ma è una prassi standard del sistema. Infatti l’identità digitale è legata strettamente allo specifico esemplare di smartphone dell’utente, grazie ancora una volta alla crittografia, e quindi non è trasferibile, in modo che siano praticamente impossibili i furti di identità. Se si cambia smartphone, si chiede semplicemente il rilascio di un nuovo certificato di identità digitale. L’intero procedimento è gratuito per i residenti.
C’è anche un altro livello di protezione della privacy: i dati personali delle credenziali digitali degli utenti non vengono mai custoditi nei server dello Stato e non c’è un’autorità centrale che li aggrega, custodisce o controlla. Lo scambio di dati avviene direttamente, in maniera decentrata, fra l’utente e il servizio o negozio. In questo modo è impossibile collegare tra loro le informazioni sull’utilizzo delle varie credenziali e fare profilazione di massa degli utenti.
I vantaggi di un sistema di identità digitale decentrato e non commerciale sono insomma numerosi, ma ci sono comunque degli aspetti meno positivi da considerare.
Il primo è la scarsa intuitività, almeno all’inizio, quando presentare il telefono per identificarsi non è ancora un gesto abituale e diffuso, anche se lo si fa già per i biglietti aerei, per i pagamenti contactless nei negozi fisici e in varie altre occasioni. Tutte le procedure informatiche che permettono, dietro le quinte, la garanzia e la verifica di un’identità digitale sono arcane e scarsamente comprensibili per l’utente non esperto, mentre verificare un documento d’identità tradizionale è un gesto naturale che conosciamo tutti.
Il secondo aspetto è la potenziale fragilità del sistema elettronico: una carta d’identità tradizionale funziona sempre, anche quando non c’è campo, e non ha una batteria che si possa scaricare. È un problema già visto con chi non stampa più i biglietti del cinema o del treno e poi va nel panico perché gli si scarica il telefono e non ha modo di ricaricarlo, o con chi si affida al navigatore nell’app e poi non sa che strada prendere quando si trova in una zona senza segnale cellulare.
Un terzo problema è la necessità di avere uno smartphone, e specificamente uno smartphone moderno con funzioni crittografiche integrate, se si vuole usare l’identità digitale: è vero che quasi tutte le persone oggi hanno un telefono cellulare, ma non tutte hanno uno smartphone Android o iOS. E ci sono persone che per mille ragioni, come costo, impatto ambientale, difficoltà motorie, diffidenza verso la tecnologia e antipatia per le interfacce tattili, non vogliono essere costrette a portarsi in giro un oggetto di questo genere.
Del resto non ci sono alternative tecniche realistiche: la potenza di calcolo e la facilità di aggiornamento che sono necessarie per avere un sistema sicuro e flessibile non consentono soluzioni come per esempio delle tessere in stile carta di credito, e comunque qualunque dispositivo dedicato comporterebbe un costo di produzione, distribuzione e gestione di milioni di esemplari, per non parlare del problema di far abituare le persone a portare con sé e tenere sempre carico un dispositivo in più, mentre lo smartphone è bene o male già nelle tasche di quasi tutti.
È anche per questo che la Confederazione continuerà a offrire tutti i servizi anche in maniera analogica e i metodi tradizionali di identificazione non verranno soppiantati ma resteranno disponibili in parallelo, per evitare che si formino dei ghetti tecnologici che intrappolano chi non può permettersi o non può usare uno smartphone, e quindi proprio le persone più deboli e vulnerabili.
Resta comunque il problema di fondo di tante innovazioni tecnologiche degli ultimi tempi: la crescente centralità e importanza che fanno assumere allo smartphone nella vita di tutti i giorni. Quello che una volta era un telefono è oggi un oggetto fragile e costoso al quale viene chiesto di fare sempre più cose: fotocamera, agenda, navigatore, chiave di casa e dell’auto, custodia per i biglietti di viaggio, portafogli, traduttore, terminale bancario e adesso anche mezzo di identificazione. Se perdiamo lo smartphone o si rompe, rischiamo la paralisi sociale. Ma siccome capita raramente, ci abituiamo, diamo per scontato che funzioni, e smettiamo di sapere come usare i metodi alternativi.
Tirando le somme, il sistema di identità digitale svizzero non è perfetto, ma l’ottimo è nemico del buono, e non fare nulla significa lasciare le cose come stanno, cioè continuare a riversare dati personali negli immensi collettori delle aziende trilionarie del settore tecnologico. Il timore istintivo che un sistema di identità digitale porti a un ipotetico Grande Fratello governativo è comprensibile, ma l’alternativa è continuare a sottostare agli umori dei tanti Grandi Fratelli commerciali che non sono affatto ipotetici.
Una regola d’oro dell’informatica, quando si tratta di privacy e riservatezza, è che bisogna sempre progettare i software che gestiscono questi aspetti cruciali della vita sociale democratica in modo che siano resistenti non solo alle tentazioni di abuso del governo corrente di un Paese, ma anche a quelle di tutti i possibili governi futuri, compresi quelli peggiori immaginabili. Per l’identità digitale svizzera sono state prese misure tecniche robuste proprio per ridurre al minimo questo rischio. La sua progettazione si basa su tre punti di forza principali.
- Il primo è la cosiddetta privacy by design, ossia la riservatezza è incorporata e intrinseca e non è una funzione aggiunta a posteriori.
- Il secondo è la minimizzazione dei dati, ossia in ogni fase vengono condivisi e scambiati soltanto i dati strettamente necessari allo scopo specifico, e anzi se un negozio o servizio ne chiede più del necessario è prevista la sua segnalazione pubblica.
- Il terzo è il decentramento, vale a dire i dati dell’identità digitale di un utente sono custoditi esclusivamente sul suo dispositivo, senza archivi centrali.
A questi tre si aggiunge un quarto punto felicemente lungimirante: il sistema di identità digitale svizzero è concepito per essere conforme agli standard internazionali, in modo da garantire che possa essere usato in futuro anche all’estero, per esempio nell’Unione Europea, che si sta attrezzando con un sistema analogo.
Se tutto procederà secondo i piani, dall’anno prossimo sarà possibile avere una sorta di portafoglio elettronico che potrà contenere documenti e attestati della pubblica amministrazione, diplomi, biglietti, licenze di circolazione, tessere di assicurazione malattia, tessere di socio, carte clienti, iscrizioni protette ai social network e altro ancora, senza più stampare e spedire montagne di carta o tessere di plastica, e permetterà di identificarsi online, o meglio di qualificarsi per esempio in termini di età o di licenze,senza regalare a ogni sito tutti i nostri dati personali.
La spesa prevista per lo sviluppo e la gestione di questa identità digitale nazionale e per l’infrastruttura che la supporterà equivale a meno di tre franchi e mezzo a testa all’anno. Sembra una spesa ragionevole, se permette di snellire la burocrazia e di evitare di dover inviare ovunque immagini dettagliate dei nostri documenti.
E soprattutto se permette di creare una penuria di scansioni di documenti di identificazione sfruttabili dai criminali informatici. Sarebbe davvero splendido riuscire a indurre finalmente in questi malviventi una vera e propria… crisi di identità.
Fonti
Cinque lezioni dalla votazione del 28 settembre sull’e-ID, Swissinfo.ch
Un “sì” poco convinto per l’e-ID in Svizzera, Swissinfo.ch
Referendum committee calls for e-ID vote in Switzerland to be cancelled, Swissinfo.ch
Identità elettronica e Infrastruttura Fiduciaria – Tecnologia, Admin.ch
Identità elettronica e Infrastruttura Fiduciaria – Public Beta, Admin.ch
Swiyu technical documentation, Github
Licenza digitale per allievo conducente (progetto pilota) Admin.ch
Il sistema AGOV svizzero: video, spiegazione
E-ID in Switzerland and EU – Technology and Regulations Decoded, Adnovum.com
CF: Legge su Id-e, si dice sollevato per esito voto, La Regione
In Svizzera, il destino dell’e-ID si decide di nuovo alle urne, Swissinfo, luglio 2025
Id-e: il Consiglio federale adotta il messaggio, Admin.ch, novembre 2023
Le argomentazioni degli oppositori (in francese)
Age Verification in the European Union: The Commission’s Age Verification App, 2025
Identificazione elettronica – eID, Europa.eu