Questo è il testo della puntata del 25 novembre 2024 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Le puntate del Disinformatico sono ascoltabili anche tramite iTunes, YouTube Music, Spotify e feed RSS.
[CLIP: brano della versione italiana della sigla iniziale della serie TV Il Prigioniero]
Sta circolando un’accusa pesante che riguarda il popolarissimo software Word di Microsoft: userebbe i testi scritti dagli utenti per addestrare l’intelligenza artificiale dell’azienda. Se l’accusa fosse confermata, le implicazioni in termini di privacy, confidenzialità e diritto d’autore sarebbero estremamente serie.
Questa è la storia di quest’accusa, dei dati che fin qui la avvalorano, e di come eventualmente rimediare. Benvenuti alla puntata del 25 novembre 2024 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Le intelligenze artificiali hanno bisogno di dati sui quali addestrarsi. Tanti, tanti dati: più ne hanno, più diventano capaci di fornire risposte utili. Un’intelligenza artificiale che elabora testi, per esempio, deve acquisire non miliardi, ma migliaia di miliardi di parole per funzionare decentemente.
Procurarsi così tanto testo non è facile, e quindi le aziende che sviluppano intelligenze artificiali pescano dove possono: non solo libri digitalizzati ma anche pagine Web, articoli di Wikipedia, post sui social network. E ancora non basta. Secondo le indagini del New York Times [link diretto con paywall; copia su Archive.is], OpenAI, l’azienda che sviluppa ChatGPT, aveva già esaurito nel 2021 ogni fonte di testo in inglese pubblicamente disponibile su Internet.
Per sfamare l’appetito incontenibile della sua intelligenza artificiale, OpenAI ha creato uno strumento di riconoscimento vocale, chiamato Whisper, che trascriveva il parlato dei video di YouTube e quindi produceva nuovi testi sui quali continuare ad addestrare ChatGPT. Whisper ha trascritto oltre un milione di ore di video di YouTube, e dall’addestramento basato su quei testi è nato ChatGPT 4.
Questa stessa trascrizione di massa l’ha fatta anche Google, che inoltre ha cambiato le proprie condizioni di servizio per poter acquisire anche i contenuti dei documenti pubblici scritti su Google Docs, le recensioni dei ristoranti di Google Maps, e altro ancora [New York Times].
Da parte sua, Meta ha avvisato noi utenti che da giugno di quest’anno usa tutto quello che scriviamo pubblicamente su Facebook e Instagram per l’addestramento delle sue intelligenze artificiali, a meno che ciascuno di noi non presenti formale opposizione, come ho raccontato nella puntata del 7 giugno 2024.
Insomma, la fame di dati delle intelligenze artificiali non si placa, e le grandi aziende del settore sono disposte a compromessi legalmente discutibili pur di poter mettere le mani sui dati che servono. Per esempio, la legalità di usare massicciamente i contenuti creati dagli YouTuber senza alcun compenso o riconoscimento è perlomeno controversa. Microsoft e OpenAI sono state portate in tribunale negli Stati Uniti con l’accusa di aver addestrato il loro strumento di intelligenza artificiale Copilot usando milioni di righe di codice di programmazione pubblicate sulla piattaforma GitHub senza il consenso dei creatori di quelle righe di codice e violando la licenza open source adottata da quei creatori [Vice.com].
In parole povere, il boom dell’intelligenza artificiale che stiamo vivendo, e i profitti stratosferici di alcune aziende del settore, si basano in gran parte su un saccheggio senza precedenti della fatica di qualcun altro. E quel qualcun altro, spesso, siamo noi.
In questo scenario è arrivata un’accusa molto specifica che, se confermata, rischia di toccarci molto da vicino. L’accusa è che se scriviamo un testo usando Word di Microsoft, quel testo può essere letto e usato per addestrare le intelligenze artificiali dell’azienda.
Questo vorrebbe dire che qualunque lettera confidenziale, referto medico, articolo di giornale, documentazione aziendale riservata, pubblicazione scientifica sotto embargo sarebbe a rischio di essere ingerita nel ventre senza fondo delle IA, dal quale si è già visto che può essere poi rigurgitata, per errore o per dolo, rendendo pubblici i nostri dati riservati, tant’è vero che il già citato New York Times è in causa con OpenAI e con Microsoft perché nei testi generati da ChatGPT e da Copilot compaiono interi blocchi di testi di articoli della testata, ricopiati pari pari [Harvard Law Review].
Vediamo su cosa si basa quest’accusa.
Il 13 novembre scorso il sito Ilona-andrews.com, gestito da una coppia di scrittori, ha segnalato un problema con la funzione Esperienze connesse di Microsoft Word [Connected Experiences nella versione inglese]. Se non avete mai sentito parlare di questa funzione, siete in ottima e ampia compagnia: è sepolta in una parte poco frequentata della fitta foresta di menu e sottomenu di Word. Nell’articolo che accompagna questo podcast sul sito Attivissimo.me trovate il percorso dettagliato da seguire per trovarla, per Windows e per Mac.
- Word per Windows (applicazione): File – Opzioni – Centro protezione – Impostazioni Centro protezione – Opzioni della privacy – Impostazioni di privacy – Dati di diagnostica facoltativi [in inglese: File – Options – Trust Center – Trust Center Settings – Privacy Options – Privacy Settings – Optional Connected Experiences]
- Word per Mac (applicazione): Word – Preferenze – Privacy – Gestisci le esperienze connesse [in inglese: Word – Preferences – Privacy – Manage Connected Experiences]
- Word su Web: File – Informazioni – Impostazioni privacy
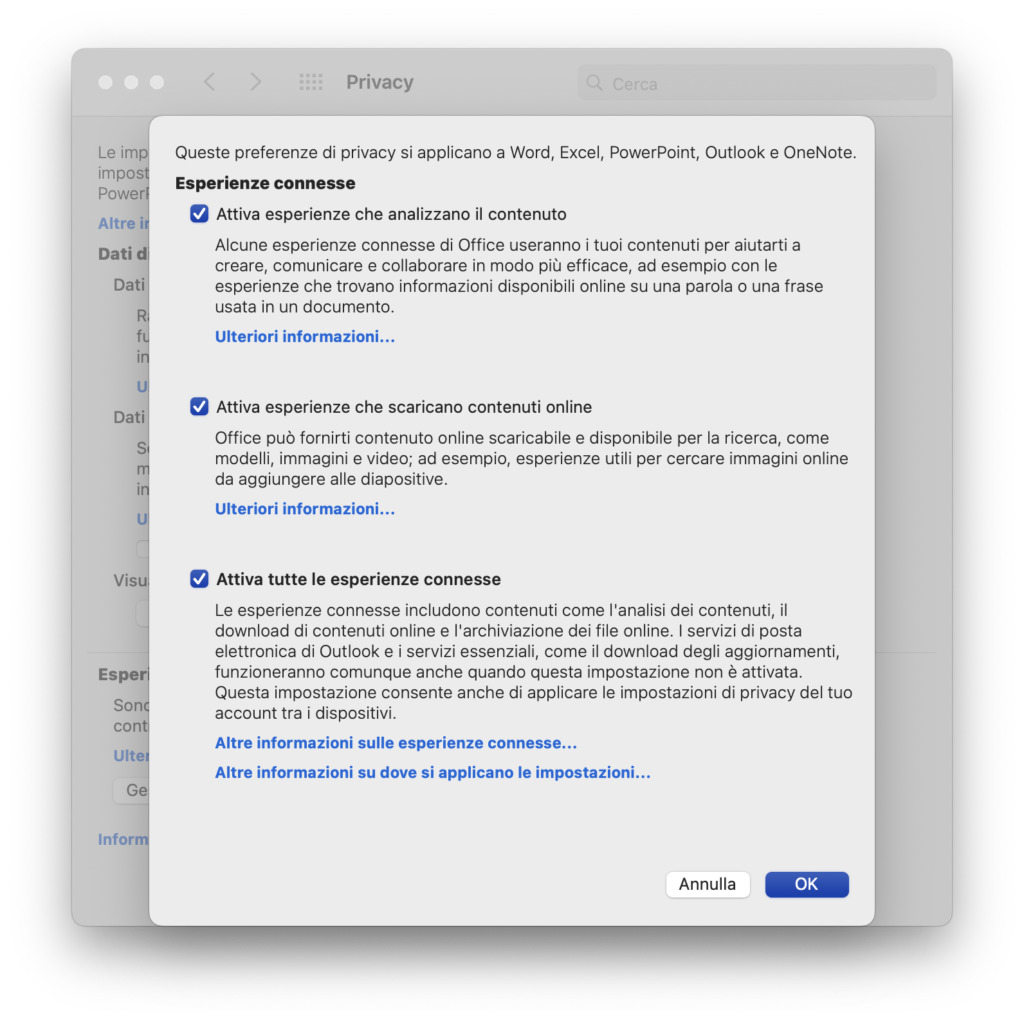
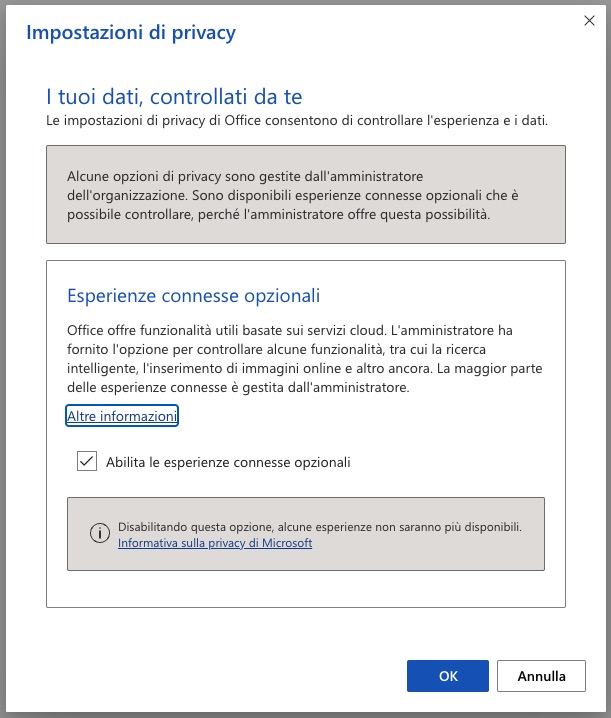
Secondo questa segnalazione di Ilona-andrews.com, ripresa e approfondita anche da Casey Lawrence su Medium.com, Microsoft avrebbe attivato senza troppo clamore in Office questa funzione, che leggerebbe i documenti degli utenti allo scopo di addestrare le sue intelligenze artificiali. Questa funzione è di tipo opt-out, ossia viene attivata automaticamente a meno che l’utente richieda esplicitamente la sua disattivazione.
L’informativa sulla privacy di Microsoft collegata a questa funzione dice testualmente che i dati personali raccolti da Microsoft vengono utilizzati, fra le altre cose, anche per “Pubblicizzare e comunicare offerte all’utente, tra cui inviare comunicazioni promozionali, materiale pubblicitario mirato e presentazioni di offerte pertinenti.” Traduzione: ti bombarderemo di pubblicità sulla base delle cose che scrivi usando Word. E già questo, che è un dato di fatto dichiarato da Microsoft, non è particolarmente gradevole.

Ma c’è anche un altro passaggio dell’informativa sulla privacy di Microsoft che è molto significativo: “Nell’ambito del nostro impegno per migliorare e sviluppare i nostri prodotti” dice “Microsoft può usare i dati dell’utente per sviluppare ed eseguire il training dei modelli di intelligenza artificiale”.
Sembra abbastanza inequivocabile, ma bisogna capire cosa intende Microsoft con l’espressione “dati dell’utente”. Se include i documenti scritti con Word, allora l’accusa è concreta; se invece non li include, ma comprende per esempio le conversazioni fatte con Copilot, allora il problema c’è lo stesso ed è serio ma non così catastroficamente grave come può parere a prima vista.
Secondo un’altra pagina informativa di Microsoft, l’azienda dichiara esplicitamente di usare le “conversazioni testuali e a voce fatte con Copilot”*, con alcune eccezioni: sono esclusi per esempio gli utenti autenticati che hanno meno di 18 anni, i clienti commerciali di Microsoft, e gli utenti europei (Svizzera e Regno Unito compresi).**
* “Except for certain categories of users (see below) or users who have opted out, Microsoft uses data from Bing, MSN, Copilot, and interactions with ads on Microsoft for AI training. This includes anonymous search and news data, interactions with ads, and your voice and text conversations with Copilot [...]”

** “Users in certain countries including: Austria, Belgium, Brazil, Bulgaria, Canada, China, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Israel, Italy, Latvia, Liechtenstein, Lithuania, Luxembourg, Malta, the Netherlands, Norway, Nigeria, Poland, Portugal, Romania, Slovakia, Slovenia, South Korea, Spain, Sweden, Switzerland, the United Kingdom, and Vietnam. This includes the regions of Guadeloupe, French Guiana, Martinique, Mayotte, Reunion Island, Saint-Martin, Azores, Madeira, and the Canary Islands.”

Nella stessa pagina, Microsoft dichiara inoltre che non addestra i propri modelli di intelligenza artificiale sui dati personali presenti nei profili degli account Microsoft o sul contenuto delle mail, e aggiunge che se le conversazioni fatte con l’intelligenza artificiale dell’azienda includono delle immagini, Microsoft rimuove i metadati e gli altri dati personali e sfuoca i volti delle persone raffigurate in quelle immagini. Inoltre rimuove anche i dati che potrebbero rendere identificabile l’utente, come nomi, numeri di telefono, identificativi di dispositivi o account, indirizzi postali e indirizzi di mail, prima di addestrare le proprie intelligenze artificiali.
Secondo le indagini di Medium.com, inoltre, le Esperienze connesse sono attivate per impostazione predefinitaper gli utenti privati, mentre sono automaticamente disattivate per gli utenti delle aziende che usano la crittografia DKE per proteggere file e mail.
In sintesi, la tesi che Microsoft si legga i documenti Word scritti da noi non è confermata per ora da prove concrete, ma di certo l’azienda ammette di usare le interazioni con la sua intelligenza artificiale a scopo pubblicitario, e già questo è piuttosto irritante. Scoprire come si fa per disattivare questo comportamento e a chi si applica è sicuramente un bonus piacevole e un risultato utile di questo allarme.
Ma visto che gli errori possono capitare, visto che i dati teoricamente anonimizzati si possono a volte deanonimizzare, e visto che le aziende spesso cambiano le proprie condizioni d’uso molto discretamente, è comunque opportuno valutare se queste Esperienze connesse vi servono davvero ed è prudente disattivarle se non avete motivo di usarle, naturalmente dopo aver sentito gli addetti ai servizi informatici se lavorate in un’organizzazione. Le istruzioni dettagliate, anche in questo caso, sono su Attivissimo.me.
E se proprio non vi fidate delle dichiarazioni delle aziende e volete stare lontani da questa febbre universale che spinge a infilare dappertutto l’intelligenza artificiale e la raccolta di dati personali, ci sono sempre prodotti alternativi a Word ed Excel, come LibreOffice, che non raccolgono assolutamente nulla e non vogliono avere niente a che fare con l’intelligenza artificiale.
Il problema di fondo, però, rimane: le grandi aziende hanno una disperata fame di dati per le loro intelligenze artificiali, e quindi continueranno a fare di tutto per acquisirli. Ad aprile 2023 Meta, che possiede Facebook, Instagram e WhatsApp, ha addirittura valutato seriamente l’idea di comperare in blocco la grande casa editrice statunitense Simon & Schuster pur di poter accedere ai contenuti testuali di alta qualità costituiti dal suo immenso catalogo di libri sui quali ha i diritti [New York Times].
OpenAI, invece, sta valutando un’altra soluzione: addestrare le intelligenze artificiali usando contenuti generati da altre intelligenze artificiali. In altre parole, su dati sintetici. Poi non sorprendiamoci se queste tecnologie restituiscono spesso dei risultati che non c’entrano nulla con la realtà. Utente avvisato, mezzo salvato.
Fonti aggiuntive
ChatGPT collected our data without permission and is going to make billions off it, Scroll.in (2023)
Panoramica delle esperienze connesse facoltative in Office (versione 30/10/2024)